


数据驱动是通过先进的IT技术和人工智能对企业的数据资产进行有效和充分的利用,其目的是从数据中获得有价值的“洞见”,以指导人们作出更加科学的决策和更加有效的行动。
企业数字化转型离不开数据驱动,而数据驱动的基础是建立在高质量数据之上的。没有高质量数据,就不可能产生有价值的洞见。
数据驱动的企业看着似乎很厉害的样子,实际上他们一直也在为数据质量问题而苦苦挣扎。数据的不完整、不准确、不一致,数据安全、数据隐私等问题似乎是无穷尽的,成为了企业数字化转型的一个难以逾越的障碍。
今天和大家聊一聊,实现数据驱动的过程中常见的数据质量问题,以及该如何解决这些问题。
01 从DIKW金字塔模型到数据供应链
要实现数据驱动,重要的是创建一个“数据供应链”,保证数据在从生产、采集、存储、加工、处理,到分析、应用的全过程中的数据质量,并且确保每个过程都是为业务目标而服务的。
供应链的概念的是从生产制造行业发展衍生出来的,它将企业的生产活动进行了前伸和后延。艾伦·哈理森(Harrison)将供应链定义为:“供应链是执行采购原材料,将它们转换为中间产品和成品,并且将成品销售到用户的功能网链。”日本丰田公司的精益协作方式中就将供应商的活动视为生产活动的有机组成部分而加以控制和协调。
数字化世界,数据既是产品也是原料,DIKW金字塔模型足以说明这个观点。在DIKW模型中,数据是用来描述事实和现象的原始的资料,是无组织的事实。将原始的、无序的、杂乱的数据进行收集和整理,并从中提取有用的信息,让数据变得更加有意义;再将信息加工、萃取成可被传播、沉淀、复用的知识,从而获得更大的价值;而智慧是DIKW层次结构的最高层,是将知识应用于行动后产生的结果,回答的是诸如“为什么要做”和“什么是最好的”之类的问题。
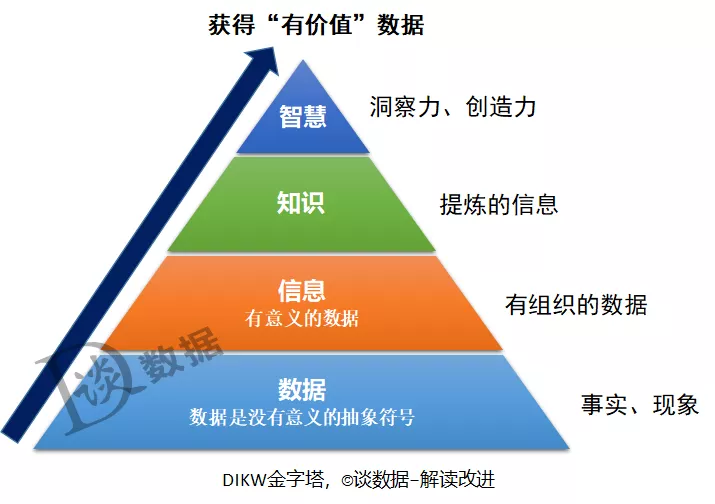
DIKW模型,反映了数据被加工、提炼的一个过程,这个过程本质上来说也是从数据需求到数据供给的过程。通过这个过程,原始的数据进入企业,经过各种处理、转换,成为可供人们使用的有价值的东西,我们将这个过程称之为数据供应链。
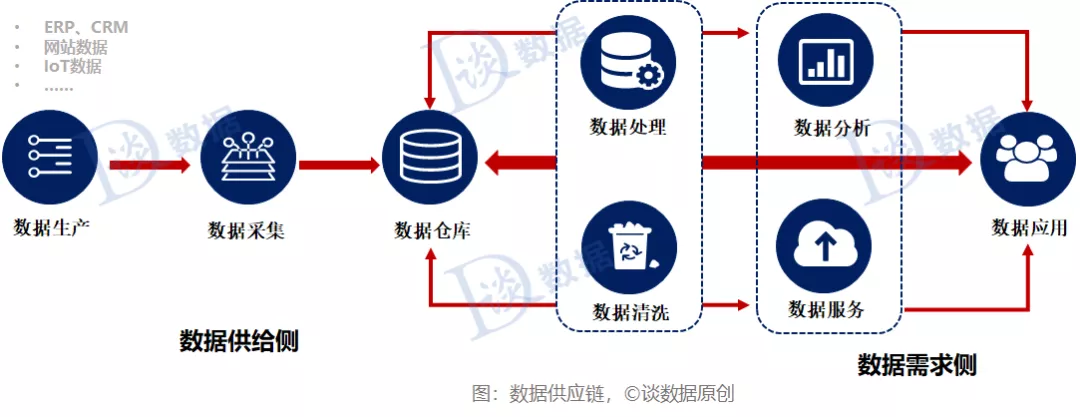
如下图所示,数据供应链与生产供应链十分相似,“原料数据”从系统的一端输入,然后在下一步中进行分析和转换。最后,它作为一组有意义、有价值的“数据产品”提供出来,用于企业业务流程的改进和指导企业管理决策。进入数据供应链的数据来自各种来源,如企业的各类信息系统ERP、CRM、移动应用程序等;企业外部的网站、社交网络、电商平台等;以及来自设备物联数据,各类传感器产生的时序数据等。这个过程,也是实施数据治理,提升数据质量,实现数据标准化的过程。
02 供给侧:重点关注的数据质量维度
数据质量问题贯穿整个“数据供应链”。我们经常听到:“垃圾进,垃圾出”,这句话是指高质量数据分析结果,取决于高质量的数据输入,输入的数据质量低下,数据分析结果也叫没有什么价值。以及笔者经常提的“数据治理要从源头抓起”,也是说的这个意思。重点都在强调数据供给侧保障数据质量的重要性。数据供给侧更多的是站在数据生产者或数据管理者的角度看数据质量的,重点关注以下的5个数据质量维度。
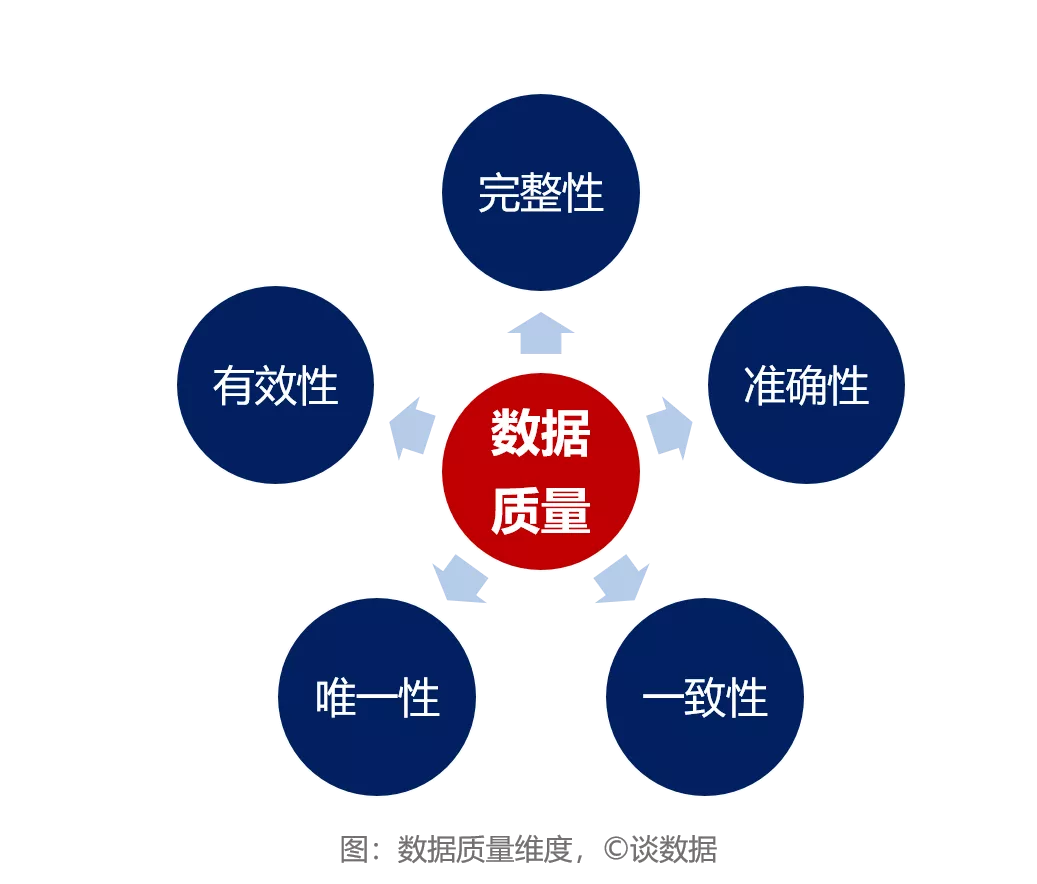
1)数据完整性。数据完整性体现在三个方面,第一是元数据的完整性,例如:唯一性约束完整性、参照完整性等;第二是数据条目完整性,例如:数据记录丢失或不可用会影响数据的完整性;第三是数据属性完整性,例如:数据属性空值情况等。
2)数据准确性。数据的准确性也叫数据可靠性,狭义上的数据准确性是用于分析、识别和度量哪些是不准确的或无效的数据的。
3)数据一致性。数据一致性主要体现在两个方面,第一是多源数据的数据模型不一致,例如:命名不一致、数据结构不一致、约束规则不一致。第二是数据实体不一致,例如:数据编码不一致、命名及含义不一致、分类层次不一致、生命周期不一致……。相同的数据有多个副本的情况下的数据不一致、数据内容冲突等问题。
4)数据唯一性。数据唯一性是用于识别和度量重复数据、冗余数据。重复数据是导致业务无法协同、流程无法追溯的重要因素,也是数据治理需要解决的最基本的数据质量问题。
5)数据有效性。数据有效性用于度量数据是否符合既定的条件,不符合条件的视为无效数据。例如:在统计当前在职的职工人数时,数据集中的已离职人员应当被剔除出去。
低下的数据质量是实现数据赋能、数据驱动的头号敌人,只有提高供给侧的数据质量,才能保证输出的数据服务或数据应用是有价值的。当然,供给是由需求驱动的,以上5个数据治理维度同样也适用于需求侧,这5个维度也是广义上的数据准确性。
03 需求侧:超越准确性的数据质量维度
从数据供给侧(生产和管理的角度)来看,数据质量主要关注准确性。其目标是尽可能地将数据与现实世界的实体相匹配。通过实施数据清理、修复数据、转换等一系列数据管理工作旨在提高数据准确性。
如果我们将视角切换至“数据供应链”的需求侧,也就是站在数据消费者、业务人员(下文统称:数据用户)的角度看,人们对数据质量的需求将超越准确性,并在此基础之上增加三个维度,如下图:
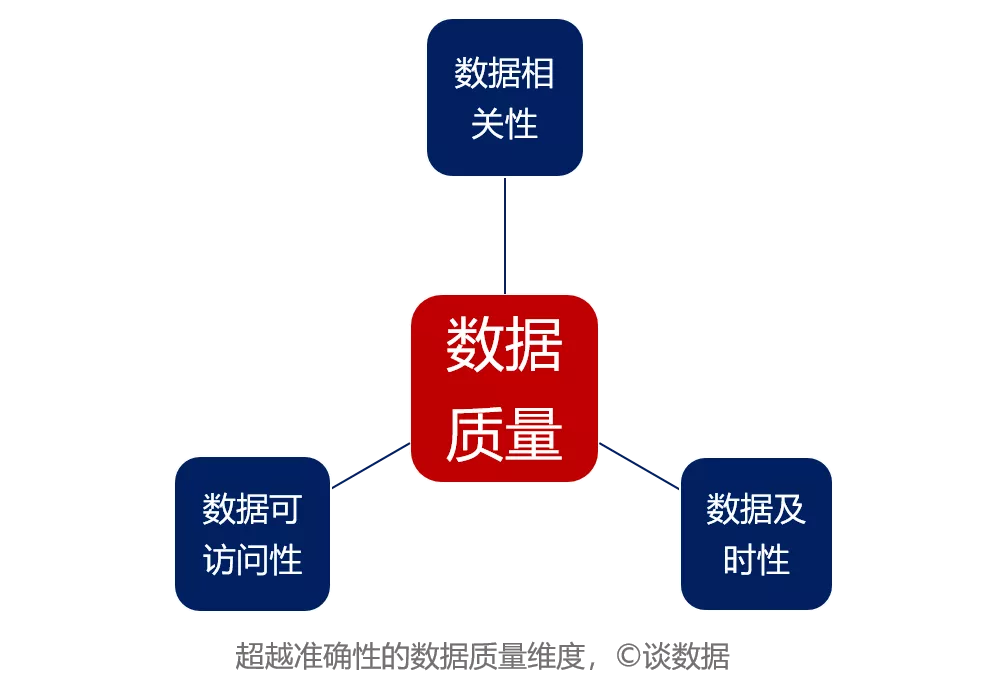
1)可访问性。对数据用户来讲,最核心的需求是当他们需要用数据的时候,这些数据是可以被访问的。他们想知道企业有哪些数据?存放在哪里?以及如何访问到这些数据?我们看到很多数据平台提供的统一数据资源目录功能就是解决这个问题的。
2)及时性。数据的价值在于能够被使用,如果不能及时使用,可访问的数据就没有价值。及时性定义了数据在需要时是否可用,过期的数据带来的结果可能是误导或误判,保证数据的及时性在一定程度上是保证业务创新性和前瞻性的基础。与实时性相比,及时性强调在需要时间内准时送达,它可以是实时的,也可以是定时的,但一定是准时的,发生在你需要的时候。
3)相关性。当数据的可访问性和及时性得到满足,用户很大程度都会将关注度放到相关性上来。数据的相关性是指数据之间,或数据与用户之间的某种关联关系,例如:函数关系、相关系数、主外键关系、索引关系等。我们在数据治理过程中经常说的相关性问题,就是指数据间或数据与用户间的关联关系缺失或错误,这可能会导致用户将大量的精力放在了不相关的数据上,或者引发出的数据准确性问题。
及时的、准确的、可信且可访问的数据是业务和管理的基础,是数据驱动的灵魂,需要站在完整个“数据供应链”的全局视角来制定考量数据质量的策略,这一过程需要数据生产者、管理者、使用者共同参与其中。数据生产者和使用者必须定义出需要什么样的数据,什么数据对业务是重要的,而数据的管理者必须专注于提供业务所需的重要数据。
04 提升企业数据质量的8点建议
1)业务需求和影响评估
数据质量改进的驱动因素永远来自业务目标,不能脱离业务需求谈数据质量。制定数据质量改进方案的基础,首先是清晰定义业务需求,然后是根据业务需求对企业业务的长期影响来定义数据质量问题的优先级。衡量业务影响、定义问题优先级有助于明确治理目标并跟进数据质量改进的进度。
2)全面盘点和正确描述
全面的数据盘不仅可以帮助您回答:有哪些数据,数据在哪里,以及如何访问数据等问题。同时,也能够帮助您正确理解数据,例如:数据描述了什么,数据对业务的价值在哪里,以及如何获得最大价值。当您需要确定数据是否“准确”或是否满足业务所需的时候,全面的数据盘点和对数据的正确描述,是您理解数据和提升数据质量的有效方法。
3)数据质量从源头抓起
“从源头解决数据质量问题”是笔者一直秉承的观点。但很多时候,我们依然看到一些数据治理项目将治理重点放在了数据副本上,例如通过修复副本中的错误或建立各种映射表,以支持下一步的数据分析。其实,这是一种“治标不治本”的做法,原始数据集仍然存在质量问题,影响其后续使用。从源头解决数据质量问题是提高数据质量、防止不良数据传播的最佳方法。
正如Gartner专家说:一个数据的生命周期有两个有趣的时刻,创建时刻和使用时刻。如果您可以在创建数据时最大限度地减少错误并始终从源头解决质量问题,那么就可以确保使用时的数据质量。
4)能选择的时候别输入
形成可供选择的值域,是一个有效避免人为因素错误、提升数据质量的操作性技巧。当用户以不同的形式输入数据的时候,难免发生一些“人为”的错误,例如:输入的数据多一个空格,大小写,简繁体,特殊符合不规范使用等常见数据质量问题。解决这个问题的有效方法是为这些数据定义好标准数据值域/值集(或称数据字典),以避免用户的输入错误。
5)建立数据驱动的文化
上文中我们说明了数据质量对数据驱动的重要性。事实上,数据驱动也能够反作用于数据质量。在企业中,建立数据驱动的文化和行为规范,更好地使用数据,能够反向促进数据质量的提升。数据驱动文化是“数据质量、人人有责”的文化,在企业范围内对数据需求定义、数据质量目标达成共识,以便持续推进数据质量问题的改进和优化。
6)DataOps——数据运营
DataOps是将DevOps的理念延伸到了数据领域,提供了一种更加自动化的数据运营方式,以提高数据分析的质量和敏捷性。DevOps是建立在3个原则之上:持续集成、持续交付和持续部署,对应到DataOps就是利用自动化数据管理工具,实现数据的数据的发现、集成和准备自动化,并支持数据质量的持续测量,在整个企业范围内持续交付准确、可信的数据。
7)数据质量,防大于治
数据质量管理不仅仅在于纠正当前的数据质量问题,还在于防止未来的发生类似数据质量问题。评估和解决企业数据质量问题的根本原因是预防问题发生的关键。例如:是否正确定义了业务需求以及对应的数据质量指标?业务流程是手动的还是自动化的?数据质量的利益相关者能否直接参与数据质量问题的解决?企业的数据驱动文化是否牢固到位?
8)数据质量成效评估
定期对企业的数据质量改进情况进行成效评估,有利于提升数据治理的成熟度,并为下一阶段的数据质量改进提供参考依据。与相关部门、相关人员就数据质量问题、产生的原因、采取的措施、改进的结果进行交流,让更多的人将积极参与到数据质量改进中来,进一步巩固企业的数据文化。
05 写在最后的话
数据驱动是依靠数据来赋能决策和运营,高质量数据无疑是实现数据驱动的保证。高质量数据意味着高质量的洞察力、值得信赖的分析报告,可优化的业务流程,更加良好的客户体验和更好的投资回报率。
没有企业不关注数据质量,但大部分企业没有站在“数据供应链”的全局视角,来看待数据质量问题。本文对“数据供应链”以及数据质量对数据驱动的意义进行了介绍,并重点从需求、供给两侧分析了数据质量应关注的维度,最后给出了数据质量管理的8点建议。
来源:谈数据
作者:石秀峰




