

01 引言
在之前的一篇博客《细谈数据仓库》我大致讲解了为何需要数据仓库?数据仓库的概念以及分层等。与数据仓库紧密相关联的概念就是 “数据治理” 了,也就是本文要讲的内容。
在讲解数据治理前,需要了解一下相关的概念,这里先贴出来 (可以先跳过):
元数据(Metadata ):描述数据的数据或关于数据的结构化数据,比如“年龄:18岁”,年龄是一种属性,用来描述具体的“值”的,而这种属性的信息就叫元数据;
主数据(Master Data):企业内需要在多个部门、多个信息系统之间共享的数据,如客户、供应商、组织、人员、项目、物料等;
资源目录:资源目录指在数据库表基础上建立的,用于对内部系统或对外部应用共享的数据资源清单;
数据模型:数据模型是通过对元数据表描述信息、字段描述信息等元数据的定义,来抽象建立元数据实体表逻辑和物理模型;
血缘分析:是保证数据融合(聚合)的一个手段,通过血缘分析实现数据融合处理的可追溯;
02 为何需要数据治理?
2.1 数据治理定义
网上对数据治理的定义褒贬不一,而我理解的数据治理就是:“处理高质量的数据,以便于高层做正确的决策”!
2.2 何为数据治理?
首先我们需要明白为何数据需要治理?下面来举个例子:
假设一家公司下有很多家子公司,每家子公司都有一个财务部门,每个财务部门都有一个财务系统,财务数据都存入他们的数据库。何时有一个问题来了,年底了,总公司的高层需要知道每年的年度报表,需要知道公司的盈利情况,那么如何解决呢?
针对上述问题,我们会很自然的想到一个方案,那就设计一个类似于 “ 数据中台 ” 的系统,也就是把每个子公司的财务系统数据库里的数据,汇聚(即ETL)到我们数据中台通过数据建模定义“数据仓库表”里面去,这样我们就能看到每个子公司财务系统里面的数据了,减少了多个子公司数据库的连库表查询,可以看到,这是十分方便和高效的。但是,这会有一个问题,因为高层不熟悉我们的系统,他们往往希望看到他们期望的东西,例如盈利的趋势,走向等,那该如何解决呢?其实这也就是我们讲数据治理的核心,即“质量”。
考过 PMP的都知道有个铁三角,即“成本、效率、质量”,这三者同时保障是很困难的,但是有了 “数据治理” 我们可以提高“效率”(如前面讲的“数据中台设计数据仓库表”),再提高“质量”,进行了数据治理之后方便高层做出决策,进而减少“成本”。
如何保证质量?这个时候就需要我们设计一个高质量的模型了,这个模型需要我们结合财务高手一起来设计,设计的前提是我们财务的基础数据(即每个子公司的财务系统数据),协同财务高手的主要目的是他们的经验(因为技术不懂财务知识)。假如他们有一套财务公式可以预测盈利的走势,那么,我们可以使用到我们的 “数据中台” 系统通过模型设计把这套财务公式应用进来,进而保证了“质量”。
再回顾之前开头说的一句话:“数据治理就是处理高质量的数据,以便于高层做正确的决策!”,通过上面的例子,是不是对“数据治理”这个概念有所理解了呢?如果还不是很清晰,可以继续往下阅读。
03 数据治理设计
先贴出一张设计图:
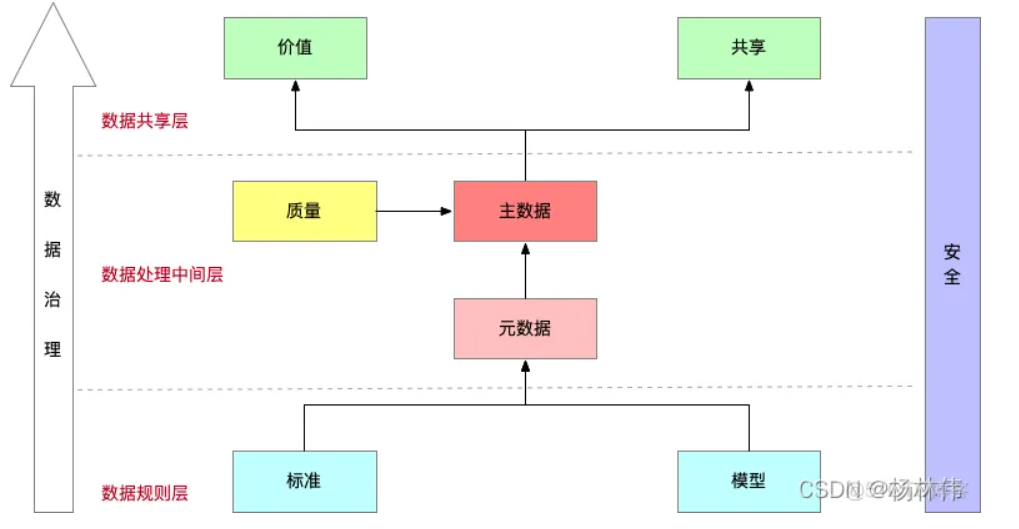
这是我自己画的一张关于“数据治理的设计图”,可以看到我把它分为了三层,分别为:“数据规则层”、“数据处理中间层”、“数据共享层”。
3.1 数据规则
3.1.1 标准
在数据治理之前,我们必须定义“标准”,这些标准都是大家公认的,比如:“国家标准”、“行业标准”、“地区标准”等。这些标准我们可以在网站里看到: http://std.samr.gov.cn/gb/
所以我们定义标准前,必须是按照全国的标准才是最规范的,例如:1表示男,2表示女等。
3.1.2 模型
这里的模型主要指的是 “元模型” 的设计,比如我们期望的数据在我们的数据仓库里面存储的规则是怎样的?例如:有哪些字段?每个字段能存什么类型?每个字段能存的值有哪些等等?
3.2 数据处理中间层
在前面,我们已经有了一个“标准”以及“模型”,那么我们可以设计数据属性了,也就是数据处理中间层要做的事情。
3.2.1 元数据
元数据(Metadata ):描述数据的数据或关于数据的结构化数据,比如“年龄:18岁”,年龄是一种属性,用来描述具体的“值”的,而这种属性的信息就叫元数据;
可以说 “元数据” 是前面说的 “模型” 来定义的,这里定义的元数据,就是我们期望的 “未来存入数据定义” ,例如:这里定义了MySQL的某张表的数据(列字段,列信息、列长度等)。
还可以理解 “元数据”对应的 “实际数据” 就是ods层的数据。
数据从源表拉过来,进行etl,比如mysql映射到hive,那么到了hive里面就是ods层,但是,这一层面的数据却不等同于原始数据,为我们定义表的数据。
3.2.2 主数据
主数据(Master Data):企业内需要在多个部门、多个信息系统之间共享的数据,如客户、供应商、组织、人员、项目、物料等;
我理解的 “主数据”,就是“元数据”的一种抽取。我们都知道“元数据”都是为了方便高效的去整理和处理数据,只能说从程序中优化了来自各系统的数据,并把它们规范存储起来,但是这些数据不能保证 “质量” 的,如果保证到了“质量”,这个数据就是“主数据”了。
主数据就是有价值的的数据,例如:这些数据可以跨部门共享的,如OA打卡数据,每个部门都需要用到。
3.3 数据共享
我把设计图的最后一层定义为 “数据共享层”,根据意思,就是把上一层的数据共享出去,可以通过“开发API”等技术共享出去,当然这些数据共享是需要通过逐层审批的,不能随意的共享出去,因为这些数据已经是 “有价值” 的了,具体怎么申请,是否需要充值,这个企业的业务需求了。
04 文末
其实最后还有一层是 “安全”,做任何的系统都是需要保障安全,具体的安全规则如何定义?这里就不再多说了。
来源:51CTO博客
作者:阿甘兄_




