

元数据管理,数据平台,数据治理,数据资产,数据质量随着企业越来越多地利用数据为研发生产提供动力、推动决策制定创新,了解这些最关键数据资产的健康状况和可靠性至关重要。几十年来,组织一直依靠数据目录来支持数据治理。但这足够了吗? 然而,数据目录并不能满足现代数据堆栈的需求,以及新方法如何进行数据发现,如何更好地促进元数据管理和数据可靠性。
了解数据存储在哪里以及谁可以访问这些数据对于了解数据对业务的影响至关重要。事实上,在构建成功的数据平台时,数据必须既有序又集中,同时易于发现,这一点至关重要。
与物理图书馆目录类似,数据目录用作元数据清单,并为用户提供评估数据可访问性、健康状况和位置所需的信息。在自助式商业智能时代,数据目录也已成为数据管理和数据治理的强大工具。
对于大多数数据领导者来说,他们的首要任务之一就是构建数据目录。
数据目录至少应该回答:
应该在哪里查找数据?
这些数据重要吗?
这些数据代表什么?
这些数据是否相关且重要?
如何使用这些数据?
尽管如此,随着数据操作的成熟和数据管道变得越来越复杂,传统的数据目录往往无法满足这些要求。
这就是为什么一些最好的数据工程团队正在创新他们的元数据管理方法。
一 当前数据目录不足的地方
虽然数据目录能够记录数据,但让用户“发现”和收集有关数据健康状况的有意义的实时见解的挑战在很大程度上仍未解决。
我们所知道的数据目录无法跟上新时代的步伐,主要原因有以下三个:
(1) 缺乏自动化;
(2) 无法随着数据堆栈的增长和多样性而扩展;
(3) 其非分布式格式。
1.难以实现高度自动化程度
传统的数据目录和治理方法通常依赖数据团队来完成手动数据输入的繁重工作,他们负责随着数据资产的发展更新目录。这种方法不仅时间密集,而且需要大量的手工劳动。如果这些工作可以自动化,数据工程师和分析师就能腾出时间专注于真正能取得进展的项目。
作为一名数据专业人士,了解数据状态是一场持久战,这说明需要更大、更定制化的自动化。也许这种情况敲响了警钟:
在利益相关者会议之前,您是否经常发现自己在疯狂地查询以找出正在使用的特定报告或模型的数据集,以及为什么上周数据停止到达?为了解决这个问题,您和您的团队是否挤在一个房间里,并开始为特定的关键报告对上游和下游的所有各种连接进行白板化?
血淋淋的事实是数据关系可能看起来像下面的图片所示:

如果上图刚好反映了你的情况,也并奇怪。许多需要解决这种依赖关系的公司开始了多年的流程来手动绘制其所有数据资产。有些企业能够投入资源来构建短期实效,甚至是内部工具,使他们能够搜索和探索他们的数据。即使能达到最终目标,这也会给数据组织带来沉重的负担,数据工程团队的时间和成本本可以花在其他更重要事情上,比如产品开发或实际使用数据。
2.难以随着数据变化而扩展
当数据结构化时,数据目录运行良好,但在 2020 年后,情况并非总是如此。随着机器生成数据的增加和公司对机器学习计划的投资,非结构化数据变得越来越普遍,占所产生的所有新数据的 90% 以上。
通常存储在数据湖中,非结构化数据没有预定义的模型,必须经过多次转换才能使用和有用。非结构化数据是非常动态的,其形状、来源和含义在经历不同的处理阶段(包括转换、建模和聚合)时一直在变化。我们对这些非结构化数据所做的事情(即转换、建模、聚合和可视化)使得在其“期望状态”中进行分类变得更加困难。
最重要的是,除了简单的描述消费者访问和使用的数据之外,还越来越需要根据数据的意图和目的来理解数据。数据生产者描述资产的方式与数据消费者理解其功能的方式会有很大不同,甚至在一个数据消费者与另一个消费者之间,在理解赋予数据的含义方面也可能存在巨大差异。
例如,从数据集中提取的数据集对数据工程师的意义与对销售团队中的某个人的意义完全不同。虽然工程师会理解“ODS_7_V3”的含义,但销售团队会摸不着头脑,试图确定所述数据集是否与 “2022 年3月分的收入预测”仪表板相关。而这样的例子不胜枚举。
静态数据描述受性质限制,我们必须接受并适应这些不断变化的新动态,才能真正理解数据。
3.数据是分布式的目录不是
尽管现代数据架构的分布以及将半结构化和非结构化数据作为规范的趋势,但大多数数据目录仍然将数据视为一维实体。随着数据的聚合和转换,它流经数据堆栈的不同元素,几乎不可能记录。
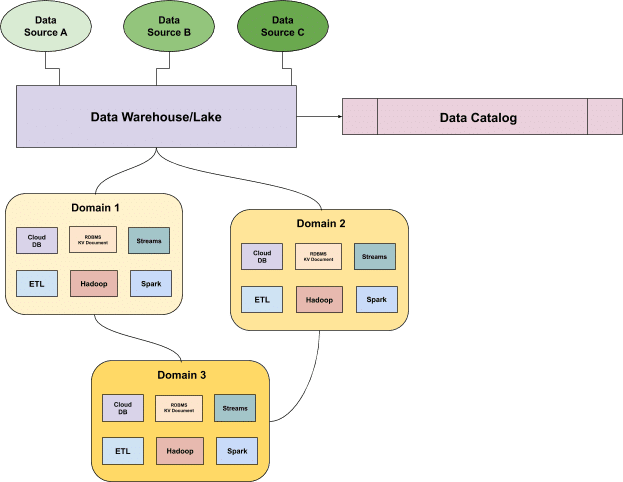
传统的数据目录在摄取状态下管理元数据,但数据在不断变化,因此很难了解数据在管道中发展时的健康状况。
如今,数据往往是自描述的,在单个包中包含数据和描述数据格式和含义的元数据。
由于传统的数据目录不是分布式的,因此几乎不可能将其用作数据的中心事实来源。这个问题只会随着更广泛的用户(从 BI 分析师到运营团队)越来越容易访问数据,以及支持 机器学习、运营和分析的管道变得越来越复杂而变得越来越严重。
现代数据目录需要跨这些域联合数据的含义。数据团队需要能够理解这些数据域如何相互关联,以及聚合视图的哪些方面很重要。他们需要一种集中的方式来作为一个整体来回答这些分布式问题,也就是说需要一个分布式的联合数据目录。
二 数据目录2.0即数据发现
当组织拥有严格的模型时,数据目录工作得很好,但随着数据管道变得越来越复杂,非结构化数据成为黄金标准,我们对这些数据的理解(它做什么、谁使用它、如何使用它等)并不能反映现实。
下一代数据目录将具备学习、理解和推断数据的能力,使用户能够以自助服务的方式利用其洞察力。我们如何才能达到这种目的呢?
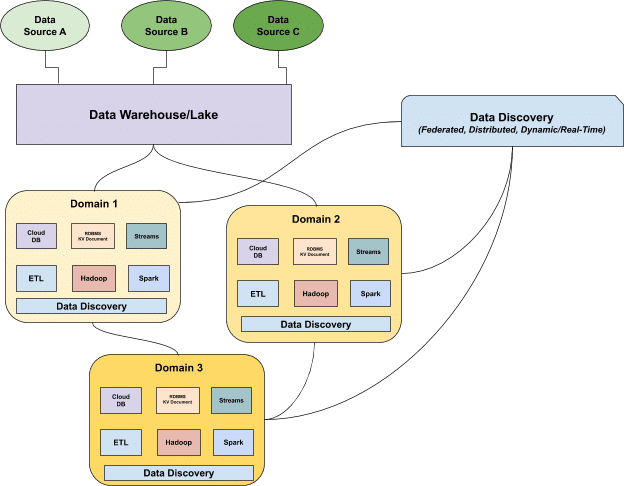
数据发现可以通过提供有关跨不同域的数据的分布式实时洞察来取代现代数据目录,同时遵守一套中央治理标准。
除了对数据进行编目外,元数据和数据管理策略还必须包含数据发现,这是一种实时了解分布式数据资产健康状况的新方法。利用数据网格模型提出的面向领域的分布式架构,数据发现假设不同的数据所有者对其作为产品的数据负责,并促进不同位置的分布式数据之间的通信。一旦数据被提供给给定域并由给定域转换,域数据所有者就可以利用这些数据来满足他们的操作或分析需求。
数据发现通过根据一组特定消费者如何摄取、存储、聚合和使用数据,提供对数据的特定领域的动态理解,从而取代了对数据目录的需求。与数据目录一样,治理标准和工具在这些域之间联合起来,允许更大的可访问性和互操作性,但与数据目录不同的是,数据发现可以实时了解数据的当前状态,而不是理想状态或“编目”状态。
数据发现不仅可以回答数据的理想状态,还可以回答每个域中数据的当前状态:
什么数据集是最新的?可以弃用哪些数据集?
上次更新此表是什么时候?
域中给定字段的含义是什么?
谁有权访问这些数据?上次使用此数据是什么时候?由谁使用?
这些数据的上游和下游依赖是什么?
这是生产质量数据吗?
哪些数据对我的域的业务需求很重要?
这些数据的假设是什么,它们是否得到满足?
数据目录2.0也就是数据发现,将具有以下特点:
1.自助服务发现和自动化
数据团队应该能够在没有专门的支持团队的情况下轻松利用他们的数据目录。数据工具的自助服务、自动化和工作流程编排消除数据管道各个阶段之间以及流程中的孤岛,从而更容易理解和访问数据。更高的可访问性会导致数据采用率增加,从而减轻数据工程团队的负担。
2.随着数据发展的可扩展性
随着摄取越来越多的数据和非结构化数据成为常态,扩展以满足这些需求的能力对于数据计划的成功至关重要。数据发现利用机器学习在组织的数据资产扩展时获得鸟瞰图,确保理解随着数据的发展而适应。通过这种方式,数据消费者可以做出更明智的决策,而不是依赖过时的文档或更糟的是基于直觉的决策。
3.分布式发现的数据沿袭
数据发现严重依赖自动化表和字段级沿袭来映射数据资产之间的上游和下游依赖关系。数据目录2.0有助于在正确的时间显示正确的信息(数据发现的核心功能)并在数据资产之间建立联系,以便可以在数据管道确实发生故障时更好地进行故障排除,随着现代数据堆栈的发展以适应这种情况,这正成为一个越来越普遍的问题更复杂的用例。
4.数据可靠性确保数据的黄金标准
事实是组织已经以某种方式可能已经在数据发现上进行了投资。无论是通过团队为验证数据而进行的手动工作、工程师正在编写的自定义验证规则,还是仅仅是基于损坏的数据或未被注意到的静默错误做出的决策成本。现代数据团队已开始利用自动化方法来确保管道每个阶段的数据高度可信,从数据质量监控到更强大的端到端数据可观察性平台,用于监控数据管道中的问题并发出警报。此类解决方案会在数据中断时通知您,以便可以快速确定根本原因以快速解决问题并防止未来停机。
数据发现使数据团队能够相信他们对数据的假设与现实相匹配,从而在数据基础架构中实现动态发现和高度可靠性,而不管领域如何。
三 数据目录的未来发展
如果坏数据比没有数据更糟糕,那么没有数据发现的数据目录比根本没有数据目录更糟糕。要获得真正可发现的数据,重要的是数据不仅要“编目”,而且要准确、干净且完全可观察,以便从摄取到消费——换句话说:可靠。
一种强大的数据发现方法依赖于自动化和可扩展的数据管理,它与数据系统的新分布式特性一起工作。因此,要真正实现组织中的数据发现,需要重新考虑如何处理数据目录。
只有了解数据、数据的状态以及在其生命周期的所有阶段、跨域数据的使用方式,我们才能信任它。
作者:晓晓
来源:数据驱动智能




