

01 数据资产的生产和消费现状
—— 孤岛就在那里!
在大数据时代,企业数据资产的生产和消费,实际现状大概是这样的。
一方面,每个业务部门都产生并存储了大量的数据。这些数据存储在不同的系统中。每个业务部门都是数据的生产者。另外一方面,每个业务部门都有使用数据来帮助进行更智能决策,每个业务部门也都是数据的消费者。
作为数据的消费者们,希望可以自由地消费全公司的数据资产。因为只有联合了多个相关部门的数据进行分析,才能够得到更为有用的结果。
但是,部门墙、数据孤岛总是客观存在的,让数据消费者去方便地消费全公司的数据有很多困难。
一方面,数据是由各个业务部门产生的。绝大部分公司,并不存在一个覆盖全公司各个业务部门的数据资产的地方。所以数据消费者不知道有哪些数据可以消费。
另一方面,数据的使用也带来了授权和监管的需求。如果数据包含了敏感信息,比如个人信用卡信息,那么法律法规就限制数据只能在有限情况下被特定的人访问。无论是授权给合适的人,还是监督谁访问了这些数据,都是数据被使用的必然要求。而这些要求伴随数据生产者,在公司内部很碎片化。
02 数据资产的消费和监督
—— 鱼和熊掌可兼得?
那么我们怎么样一方面能够让数据更好更快更方便的在全公司范围内被发现被消费,另外一方面又能够做到数据的所有使用和访问都需要授权和监督?
为了兼顾全公司范围内的数据资产能被方便的使用,和数据资产的使用被有效授权和监管这两个不同的要求,有的公司采用了这样一个办法:专门成立一个部门,集中管理全公司范围内各个业务部门产生的所有数据,给需要的人提供访问,并做好授权和监督。
现实中这个想法很难行得通。这个部门,既不是数据的生产者,也不是数据的消费者,但是却需要对数据的访问和监督负责。这问题就很大了。责权不匹配,是各个部门互相推卸责任的好帮手。可以想象如果出问题的话,到底是数据生产者的锅,数据消费者的锅还是这个部门的锅,没人能搞得清楚了。
其实,退一步海阔天空,数据治理是有可能从一个较小的范围启动起来的。
市场部门需要销售部门的每周的数据汇总,那就先把这个数据给提取出来,形成API,让市场部门去用。
这样就在市场部门(数据消费者)和销售部门(数据生产者)之间,建立了一条线,并且有了一个公共的数据“每周销售汇总”。
这个数据就像一个手机充电头,不但市场部门可以“充电”,别的部门将来也可以用。随着时间推移,这样的充电头就会越来越多,就会形成一个小型充电站,数据治理也就基本完成了。这是一种需求驱动的敏捷方法,不过,敏捷的方式需要敏捷的工具。
这个工具应该支持数据生成者迅速地把自家数据形成一个Schema,定义好有哪些字段,字段的具体含义。并且定义好哪些组织,什么人可以访问,消费者看到以后,就可以直接使用。
03 敏捷的,分散式的数据治理
—— 到底怎么搞?
也许有人要问,有没有一个办法可以提供一种靠谱的,持续发展的数据治理方式,帮助企业在生产者和消费者之间牵线搭桥,既能方便消费者很好地跨部门使用数据,又能够让数据的访问经过合理的授权,接受监督呢?
下面就给您答案!
2022亚马逊云科技re:Invent全球大会上发布了一个新服务Amazon DataZone。Amazon DataZone为数据治理提供了一套可行的思路:敏捷的,分散式的数据治理。
具体来说,Amazon DataZone提供了一个平台和对应的工具,方便数据的生产者和消费者建立连接,让消费者对生产者的数据进行使用。
在实际使用过程中,并不需要全公司全方位进行数据治理。只需要找到一个生产者和一个消费者,这一对生产者和消费者就可以先创建项目和API,让消费者把数据在监管的情况下先用起来。下图展示了Amazon DataZone的主要组件。

这样一来,就不需要有一个跨部门全公司范围内全方位的治理了。生产者依然是数据的拥有者,消费者依然是向生产者请求数据的使用。生产者和消费者所对应的信息被聚集到Amazon DataZone这个统一的平台下。
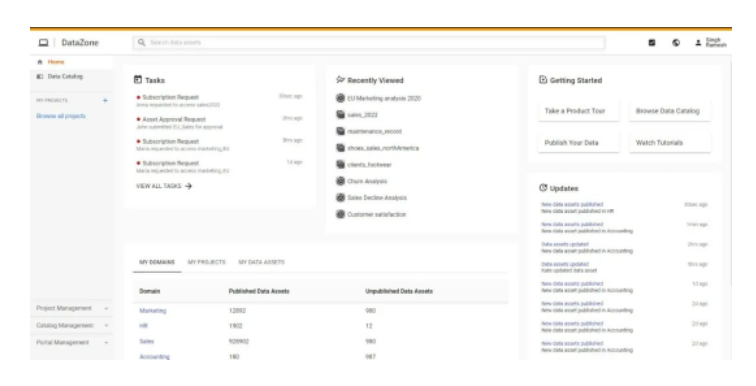
Amazon DataZone的另外一个重要的功能是提供了一个统一的门户,潜在的数据消费者可以很容易的在这里对所有在Amazon DataZone上的数据资产进行搜索。下图展示了Amazon DataZone的数据门户。
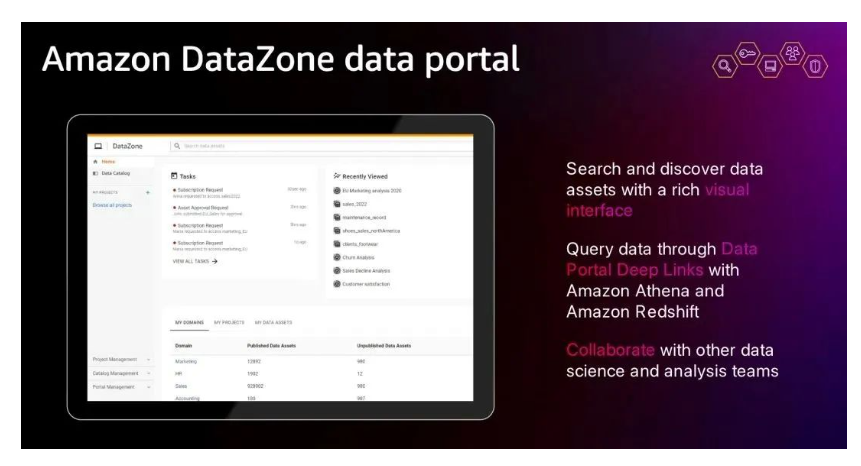
继续上面这个例子。如果有更多团队想使用已有的数据资产,他只需要在Amazon DataZone的门户搜索并发现这个数据资产。然后就可以订阅并加入消费者的行列。第三者的使用并不需要生产者再次重复之前创立数据资产和对应API的所有步骤了。下图展示了潜在数据消费者,如何利用数据门户进行搜索。
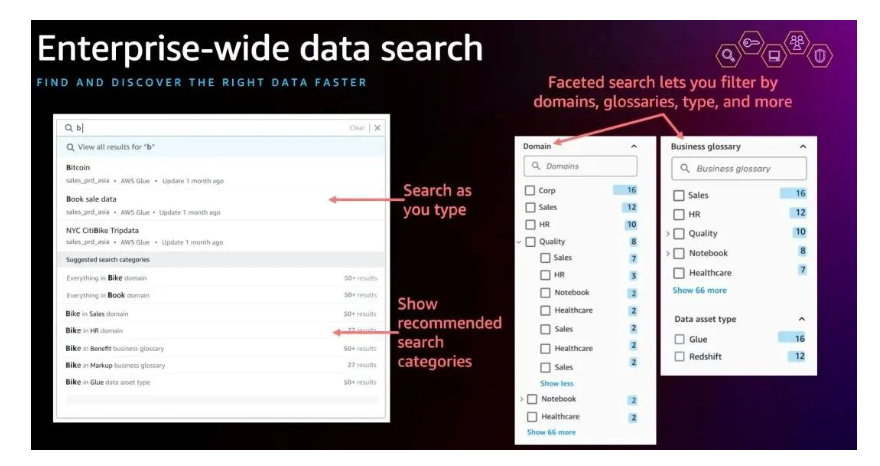
如果说Amazon DataZone提供的功能让一对生产者和消费者建立连接,是一个企业内部的两个点被连成了一条线的话,那么第三者通过Amazon DataZone发现数据资产并使用,则可以让线变成网。用的时间就来,不断有生产者和消费者加入,不断有额外的消费者建立额外的链接,数据治理也就越来越成规模化发展了。这就是敏捷的,分散式的数据治理。
在这里,Amazon DataZone扮演了重要角色。一方面,Amazon DataZone只是一个数据资产发布和管理的平台,实际对数据资产进行管理的依然是数据的生产者。
另外一方面,Amazon DataZone事实上聚集了越来越多的数据资产的信息。同时Amazon DataZone也提供了让第三方潜在数据消费者去发现这些数据资产,从而能够使用这些数据资产的能力。
这两方面能力的结合,是Amazon DataZone解决数据治理过程中万里长征不知道从何开始,也不知道怎么样完成的核心手段。Amazon DataZone通过这些能力,为企业敏捷的,分散式的数据治理提供了一个平台。
在这个平台下,企业可以通过敏捷的增量模式,逐渐将公司的所有数据资产在一个统一的平台下实现数据治理,让数据治理的万里长征真正成功。Amazon DataZone这个服务,值得每个需要数据治理的企业去尝试。
对于企业来说,数据可能来源于数据仓库、数据湖、流数据、关系数据库、第三方系统等多个地方,亚马逊云科技提供了一个叫Amazon Glue工具,可以轻松地发现、集成来自多个数据源的数据,并且可以对数据进行提取、转换、加载(ETL)。用户可以按照自己的需求,把各个数据源的数据进行编目,形成数据目录(Data Catalog)。
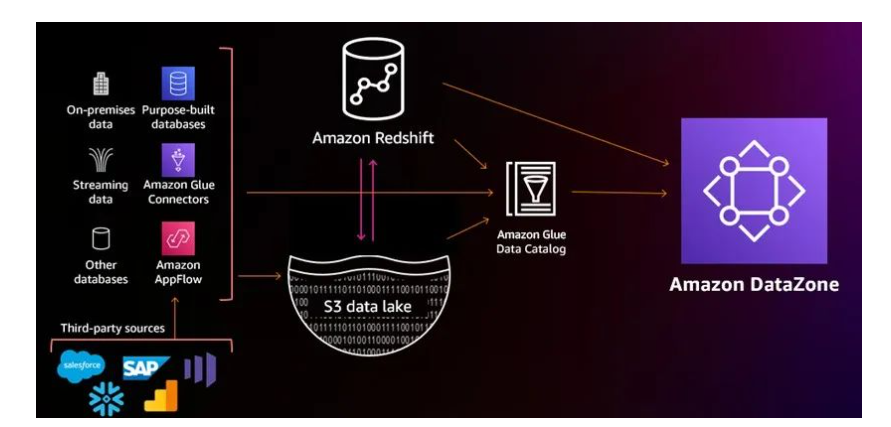
有了数据目录和组织结构做基础,每个部门就可以根据需要来创建属于自己的业务术语,元数据,从而建立自己的数据资产。
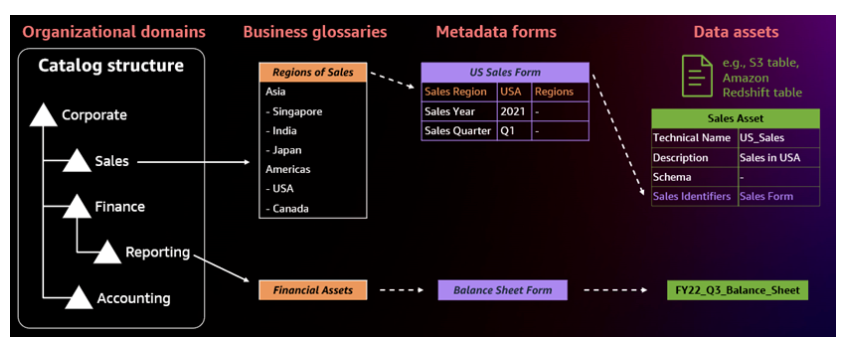
数据资产一旦发布出去(当然,需要设置好权限),别人就可以查询了,Amazon DataZone 专门提供了一个门户(Portal)对数据资产进行查询,非常方便。

利用这种方式,可以迅速地对接生产者和消费者,把数据资产创建起来,马上投入使用,从而实现快速响应业务需求,应对市场变化。沉淀下来的数据资产还可以继续被别的消费者使用,随着这样的数据资产越来越多,大家都看到了业务价值,数据治理就会走上正轨。
来源:大数据架构师
作者:谈数据




