

你知道ChatGPT和国内的DeepSeek为什么能迅速崛起吗?
技术?架构?算法?
都不是。
这些模型真正的秘密武器是——
数据治理。 当所有人都在谈论"参数规模"时,少有人意识到,数据质量才是AI真正的生命线。
从"算法为王"到"数据为王"
我不止一次听到AI工程师们说:"给我相同的数据,我可以用更好的算法获得更好的结果。"
多么自信的断言!可惜,这种思维已经过时了。
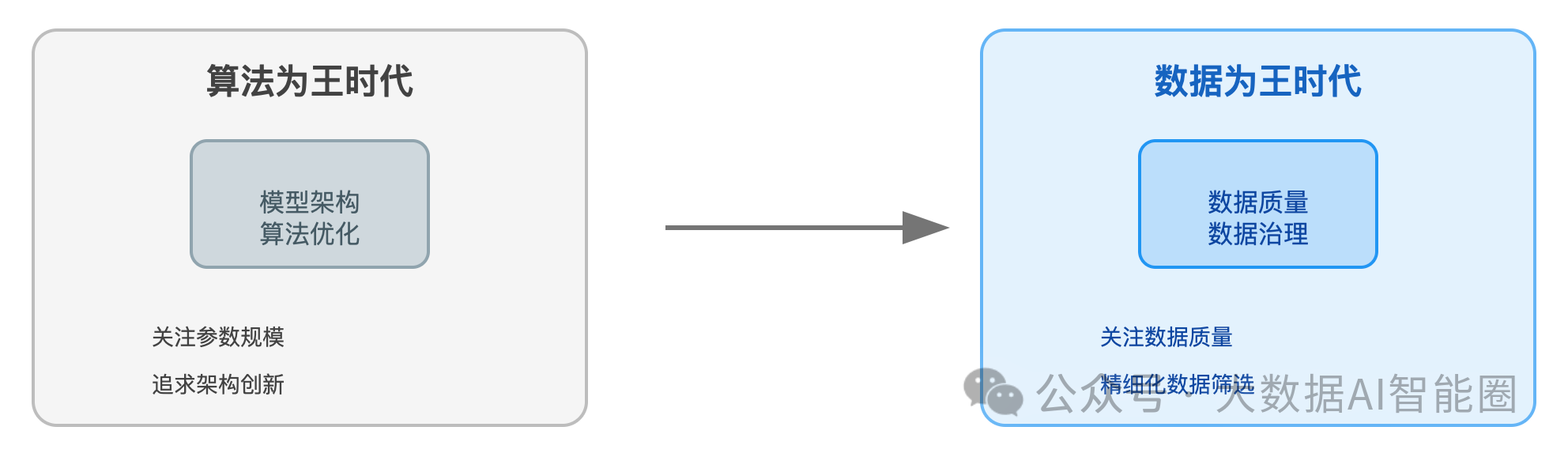
GPT-1到GPT-4o的演进历程证明了一个关键事实:在模型架构相对稳定的情况下,高质量数据是提升性能的决定性因素。
GPT-1使用了4629MB文本数据,性能平平。
GPT-2增加到40GB,表现提升。
GPT-3采用570GB经严格筛选的数据(从45TB原始数据中仅选取1.27%),性能飞跃。
ChatGPT引入人类反馈数据,彻底改变了游戏规则。
这已然不仅仅是数据量的增加,更是数据治理质量的飞跃。
而国内的DeepSeek同样验证了这一点!数据治理,正是AI成功的隐形之手。
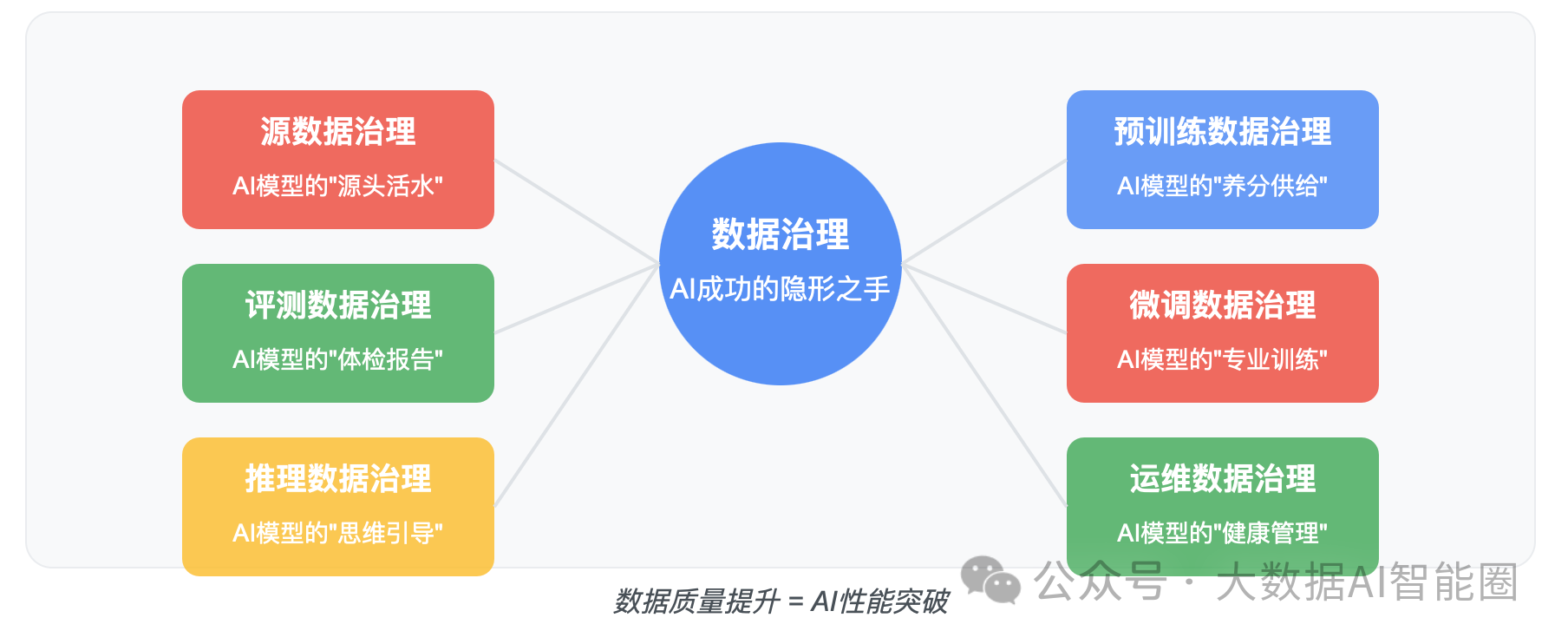
六维数据治理框架
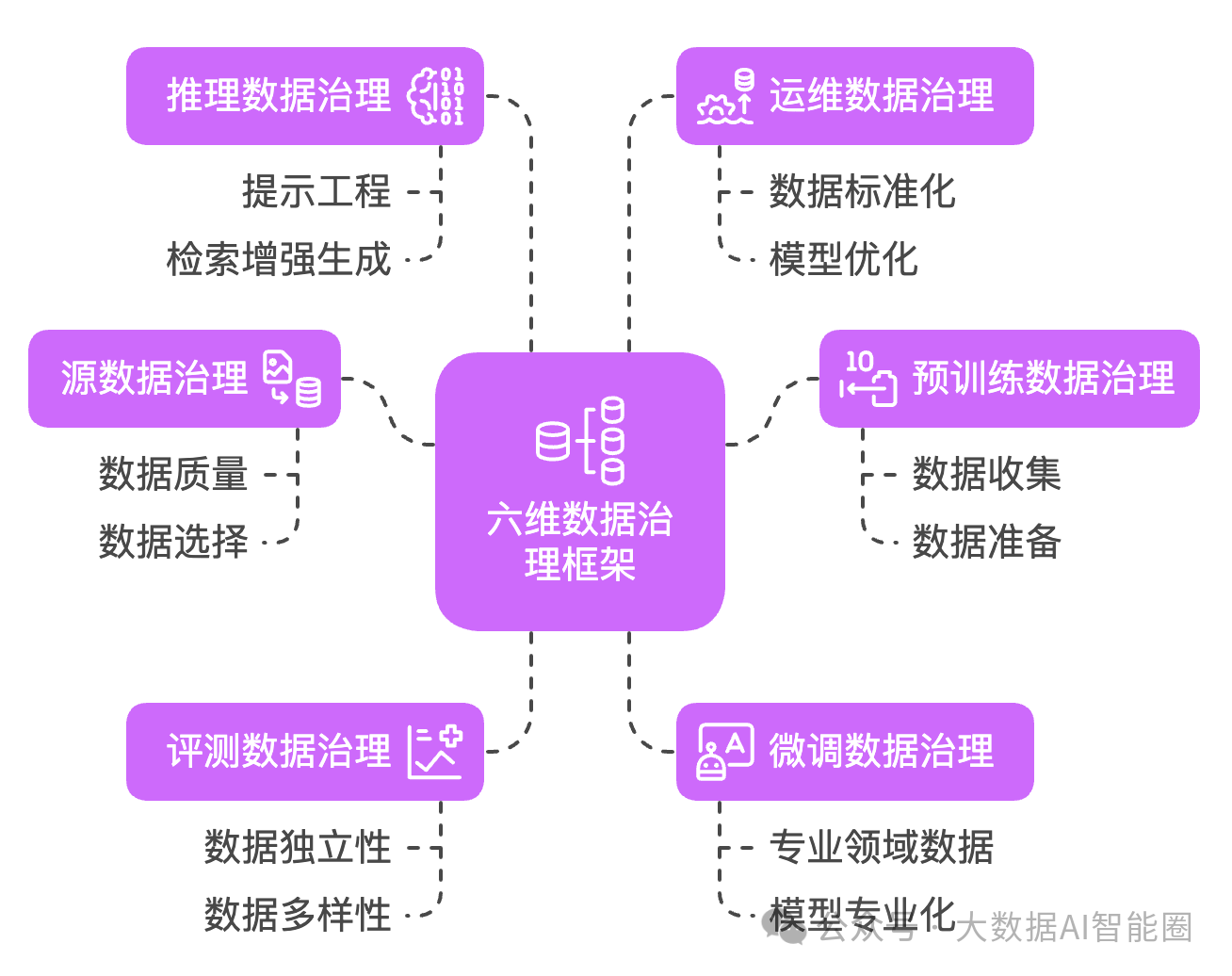
那么,怎样才能实现高效的AI数据治理?
我为你总结了2025年面向AI的六维数据治理框架:
1. 源数据治理
这是AI模型的"源头活水"。
南方电网的"大瓦特"大语言模型从源头解决了电力行业专业数据的质量问题,使其在输电巡检等特定领域表现出色。
优质的源数据治理就像农民精选种子,决定了未来收获的上限。
2. 预训练数据治理
这是AI模型的"养分供给"。
它包含数据收集、准备、浓缩和增强四个环节。
GPT-3团队从45TB数据中仅选取了1.27%作为训练数据,这种严苛的筛选标准确保了每一条数据都具有营养价值。
3. 评测数据治理
这是AI模型的"体检报告"。
评测数据必须与训练数据保持独立,同时具备多样性与代表性。
好比医生需要全面的检查才能准确诊断,AI模型也需要全面而客观的评测数据来验证其真实能力。
4. 微调数据治理
这是AI模型的"专业训练"。
国家能源集团的能源通道大语言模型通过融合煤炭、电力、铁路等专业领域数据,实现了从通用模型到行业专家的转变。
精心设计的微调数据集就像量身定制的训练计划,让模型在特定领域达到专业水准。
5. 推理数据治理
这是AI模型的"思维引导"。
提示工程(Prompt Engineering)、检索增强生成(RAG)和思维链都是提升推理能力的关键技术。
热电云平台模型通过精确的推理数据输入,实现了热电生产的智能调控,提升了发电效率,减少了碳排放。
6. 运维数据治理
这是AI模型的"健康管理"。
国网山东电力公司的AI中台通过标准化的数据管理,实现了模型的持续优化和迭代升级。运维数据治理就像定期体检和保养,确保模型在长期运行中保持最佳状态。
结语
数据治理不是理论概念,而是实践智慧。
以ChatGPT为例,其数据治理经历了三个阶段的演进:从较低质量、较小规模的数据集,到更高质量、更大规模的数据集,再到引入人类反馈的标注数据集。
在此过程中,模型算法结构几乎没有重大调整,真正变化的是数据治理的深度和广度。
未来,数据治理将越来越成为AI发展的核心驱动力。
当模型架构趋于稳定,数据质量的提升将成为性能突破的主要途径。面向人工智能的数据治理框架,正成为推动AI进步的关键支撑!
来源(公众号):大数据AI智能圈




