

数据建模听起来像是一个高调的词,你会在高风险的创业公司路演中听到,或者在数据团队会议上虔诚地低声说。但如果你曾经列过购物清单,或者对衣柜进行过分类(没错,袜子总要有个归宿),那么恭喜你——某种程度上来说,你已经在进行数据建模了。
在这篇博客中,我们将深入剖析最近学习到的一些最重要的数据建模方法——所有这些都是在努力平衡过多的标签、大量的咖啡和一个令人困惑的橡皮鸭调试会话的过程中完成的。我们将从数据建模层和范式到星型模式、数据仓库、ETL/ELT,甚至Spark 管道,分解关键概念,并提供真实案例,避免过多的专业术语。
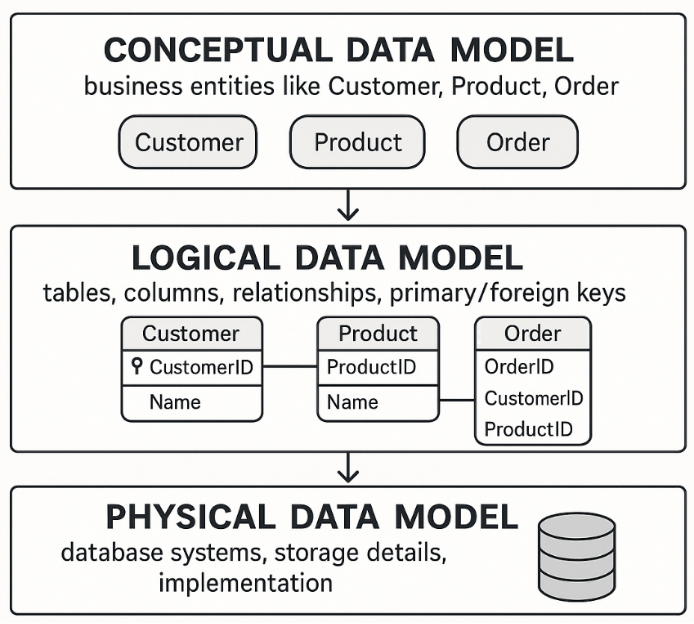
数据建模层:概念层、逻辑层、物理层
数据建模是设计数据系统结构的过程。它通常分为三个层次:
·概念模型——业务实体和关系的高级视图,不包含技术细节。
·逻辑模型——定义表结构、关系、键和属性。独立于物理存储。
·物理模型——在特定的数据库引擎中实现逻辑模型,包括索引、分区和数据类型。
想象:
你正在规划一栋房子。
概念=纸上草图(卧室、厨房、浴室)
逻辑=带有测量和布局的蓝图
物理 =用木材、瓷砖和电线实际建造
数据库规范化(1NF-3NF)
规范化可帮助您减少重复并提高数据完整性——通过将大型冗余表拆分为更小、干净相关的表。
前三个范式是:
·1NF:消除重复组和嵌套数据。
·2NF:消除部分依赖——每一列必须依赖于完整的主键。
·3NF:删除传递依赖关系——非键列必须仅依赖于键。
想想你的衣柜:
1NF:所有东西都折叠起来,没有嵌套在另一件衬衫里
2NF:每个抽屉只包含一个类别(没有混合的衬衫+裤子)
3NF:配饰(如腰带)与服装分开存放
TL;DR:进行规范化,直到您的查询高效并且您的连接看起来不像谋杀谜题板。
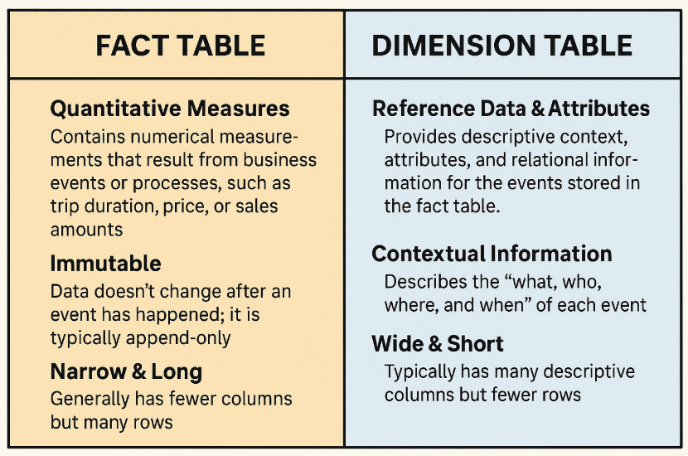
星型模式
星型模式是数据仓库中使用的一种维度建模方法。
·它以一个中心事实表(销售额或收入等定量数据)为特色,周围环绕着维度表(客户、产品、地区等描述性数据)。
·此设置可使您的 SQL 速度更快并且仪表板更整洁。
可以将事实表想象成商店的销售登记簿。维度表则是产品目录、客户目录和商店列表。这种结构使分析查询更快、更容易。
事实表与维度表
·事实表:包含可测量的定量数据(例如销售额、数量、收入),通常非常大(数百万或数十亿行),并具有引用维度表的外键
·维度表:存储描述性、分类数据(例如,客户名称、产品类型、地区),有助于为事实表中的数字提供背景信息,通常较小且经常被引用
·Inmon 方法(自上而下):首先使用规范化结构(通常为 3NF)创建一个集中式企业数据仓库 (EDW)。数据经过大量的暂存和转换后加载到仓库中。EDW 完成后,将为特定部门(例如销售、人力资源、财务)创建数据集市。这种方法有利于实现强大的治理、一致性和长期可扩展性。
·Kimball 方法(自下而上):首先使用非规范化的星型模式,直接从源系统构建数据集市。这些数据集市随后会集成到更大的数据仓库中,或作为独立的数据集市保留。该方法强调速度、访问便捷性和业务友好性。
技术权衡:
·Inmon需要更多的前期规划、更长的时间表和更严格的建模规则,但可以提供高度的数据完整性。
·Kimball部署速度更快,分析师查询也更方便——但如果管理不善,可能会导致重复和控制松散。
当你需要全局一致性时,请选择Inmon 。当速度和可用性至关重要时,
请选择Kimball 。
现实世界?大多数团队都会两者兼顾。而且会花数周时间去命名表格,却无人能达成一致。
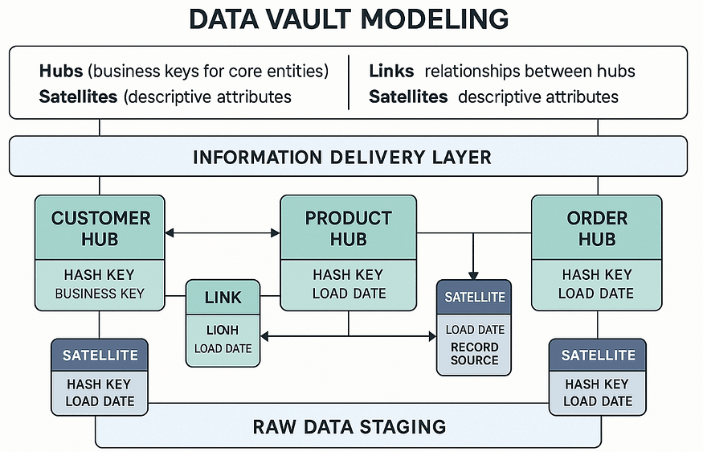
数据仓库建模
Data Vault 是一种混合数据建模方法,旨在实现敏捷、可扩展且可审计的数据仓库。它将数据分为三个核心部分:
·中心——代表唯一的业务实体(例如,客户、产品)。每一行都由一个业务键唯一标识。
·链接——定义中心之间的多对多关系(例如,客户→订单)。
·卫星——包含与中心或链接相关的上下文、历史变化和描述性属性。
主要特点:
·支持缓慢变化维度(SCD)的历史跟踪。 -
·专为并行加载而设计——集线器、链路和卫星可以独立加载。
·鼓励可审计性、沿袭跟踪和易于模式扩展。
可以将 Data Vault 想象成乐高套件——灵活、可扩展,并且您可以在不破坏整个套件的情况下克服错误。
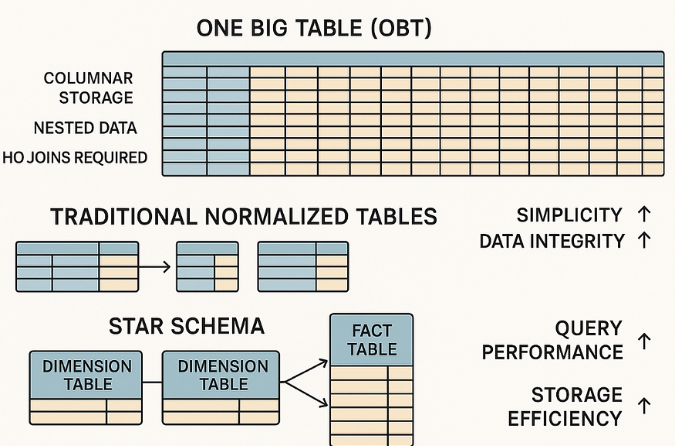
一个大表(OBT):快速,平坦,并且......有缺陷?
OBT将事实数据和维度数据合并到单个宽表中。它快速、简单,非常适合仪表板。
但:
·很难维持。
·模式改变=麻烦。
·空值?哦,肯定有很多。
例如:
想象一下,你不再为收据、供应商和日期设置单独的文件夹,而是将所有信息都放在一个大电子表格里。阅读速度很快,但维护起来却很困难。
何时使用:优先考虑速度的仪表板或 BI 工具、原型设计或 MVP 分析,以及当模式更改最少且简单性是关键时
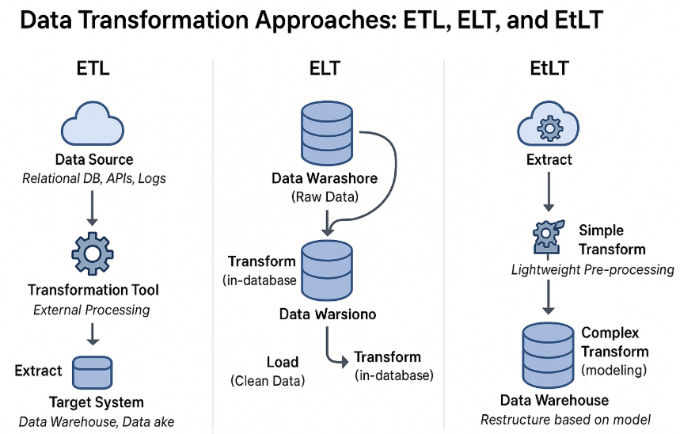
ETL 与 ELT 与 ETLT
·ETL:提取→转换→加载——数据在加载到仓库之前进行转换。
·ELT:提取→加载→转换——将原始数据加载到仓库中,然后进行转换。
·ETLT:一种混合体,具有轻度处理预载和之后更深层次的转换。
把它想象成烹饪:
ETL 是在下锅前把所有食材准备好。ELT
则是把所有食材放入锅中,边煮边调味。ETLT
介于大厨和“冰箱里有什么?”之间。
数据转换工具
常用工具:
·AWS Glue:基于 Apache Spark 构建的无服务器 ETL。配置正确后,可扩展性良好。
·DBT:云数据仓库内部基于 SQL 的转换。非常适合仓库中的版本控制和 CI/CD。
·AWS DataBrew:无需代码即可进行数据整理。拖放式转换。非常适合快速探索或非程序员使用。
·Pandas/Spark——用于转换的自定义脚本。非常适合处理早期混乱的数据或一次性批处理作业。
Hadoop 与 Spark:传统与 Lightning
Hadoop:
·批处理。
·将数据存储在磁盘上
·适用于大型但速度较慢的数据工作负载,历史上使用较多
Spark:
·内存处理,分布式计算。
·处理批处理、流处理、ML,甚至 SQL
·为 AWS Glue、Databricks 等现代工具以及一半的面试问题提供支持。
TL;DR:当您的数据管道想要感觉快速和智能时,它就会使用 Spark。
机器学习的特征工程
您并不总是能够构建模型,但您却能够使模型成为可能。
作为数据工程师,您的职责是准备:
·清理并标记的数据集
·编码类别(标签、独热)
·缩放数值
·衍生特征(例如“每分钟观看次数”)
·噪声或缺失值最少的数据集
特征工程就像准备饭菜。准备得越干净、越好,厨师(你的机器学习模型)的工作速度就越快。
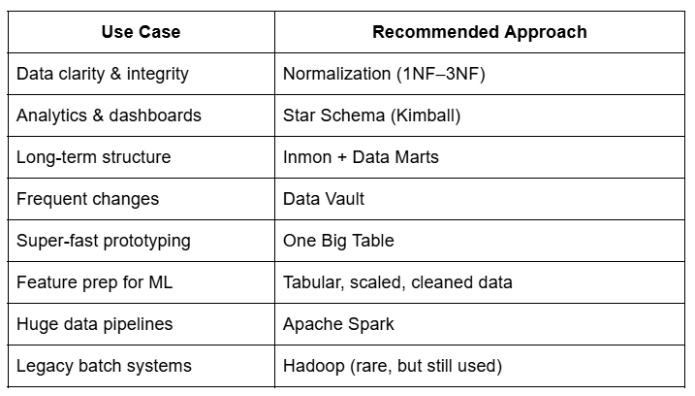
TL;DR 备忘单
最后的想法
好的建模造就好的数据。那么,好的数据呢?这是每一个伟大的产品、洞察和决策的开端。
因此,无论您是在绘制第一个星型模式还是在生产中设置并行 Spark 作业,请谨慎、清晰地构建数据,并设置适当的混乱度以保持其趣味性
来源(公众号):数据驱动智能




