

最近和几位数据团队负责人聊天,发现一个挺普遍的情况:
大家都在说 “数据开发难”,可真问起难在哪儿,说法却不一样。
有人说 “业务提的需求没头没尾,做完就说不对”;
有人抱怨 “天天写SQL,数据质量还是老出问题”;
还有人念叨 “老板要实时报表,可现有的离线架构根本撑不起来”。
这些吐槽背后,其实是对数据开发的理解偏了:
很多人觉得数据开发就是 “技术搬运工”,写几条 ETL 脚本、建几个数据表、跑几个任务就完事了。
但实际上:
数据开发的本质是 “用数据解决问题的系统工程”,不光要懂技术实现,还得能把业务需求、数据链路、质量管控和价值落地整个流程串起来。
今天这篇文章,我想抛开数据开发那些表面的东西,从最根本的逻辑来讲讲,这门技术活儿到底是怎么一回事。
一、数据开发的本质是 “用数据”
先问个问题:数据开发是从哪儿开始的?
我见过太多团队,一上来就说 “接数据”——
先把业务库、日志、第三方接口的数据同步到数仓,
然后建表、清洗、聚合,
最后就等着业务方来取数。
但这种 “先有数据再找需求” 的模式,往往会出两个问题:
数据团队天天忙,业务却总说 “要的数没有,有的数没用”;
数仓里堆了一堆 “历史遗留表”,90% 的表半年都没人碰过。
这就是典型的把 “数据驱动” 做成了 “数据驱动数据”。
说白了,真正的数据开发,起点应该是 “业务问题”——
先搞清楚要解决什么业务目标,再反过来想需要哪些数据、怎么加工、怎么才能产生价值。
举个真实的例子:
有个电商平台的用户增长团队,想提高 “首单转化率”,但传统的离线数仓只能提供 T+1 的用户行为汇总数据。数据团队没直接说不行,而是和业务方一起把问题拆解开:
首单转化的关键节点有哪些?(浏览商品→加购→支付)
每个节点的流失率是多少?和用户设备、渠道、时段有没有关系?
需要什么样的数据来支持分析?(实时点击流、设备信息、渠道标签、支付状态)
根据这些需求,数据团队做了三件事:
技术上:搭了实时数据管道,把用户行为日志从 Kafka 接到 Flink,实现了秒级延迟处理;
业务上:和运营团队把 “关键指标口径” 对齐了(比如 “加购未支付”,定义成 “加购后 30 分钟没支付”);
交付上:开发了实时看板,还输出了 “高流失时段用户画像” 和 “促活策略建议”。
结果也很好:
首单转化率提高了,而数据团队的工作量比之前做 “通用报表” 还少了。
这就说明:
数据开发的核心不是 “我能产出什么数据”,而是 “业务需要什么数据来解决什么问题”。
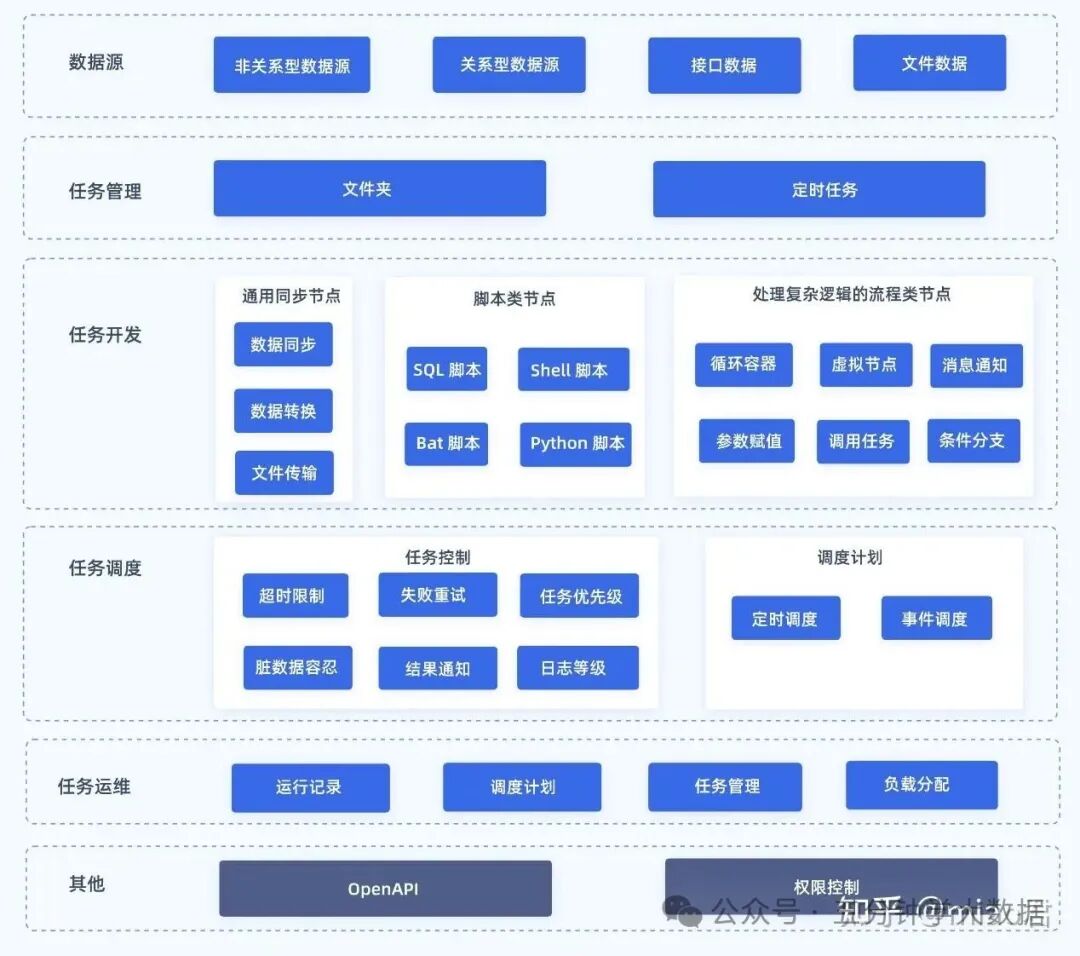
二、数据开发的五个关键环节
既然数据开发的起点是业务问题,那整个流程该怎么设计呢?
我调研了 20 多个数据团队,总结出数据开发的 “五步闭环模型”,能覆盖从需求接收到价值验证的全流程:
1. 需求洞察:把 “伪需求” 过滤掉,锁定 “真问题”
需求阶段是数据开发的起点,但也是最容易被忽略的环节。很多团队为了 “快速响应业务”,不管什么需求都接,结果陷入 “需求越做越多,价值越来越低” 的怪圈。
正确的做法是 “三层提问法”:

2. 数据采集:别 “全量同步”,要 “精准获取”
数据采集的本质是 “按需取数”。以前技术能力有限,很多团队只能 “全量同步”,但现在数据量增长太快了,这种模式在成本和效率上都不行了。
现在的数据采集得 “精准分层”:
核心数据(像交易、用户基础信息):用 “实时 + 增量” 采集;
行为数据(像点击、浏览日志):通过埋点 SDK 或者日志采集工具收集,按天或者小时分区存储;
外部数据(像天气、舆情):通过 API 接口或者 ETL 工具定时拉取,还要设 “数据有效期”。
3. 数据处理:从 “脏数据” 变成 “可信数据”
数据处理是数据开发的 “重灾区”,主要有3个痛点:
脏数据(缺失、重复、错误)
数据冗余(同一指标好几个版本)
计算低效(复杂 SQL 跑几小时)
解决办法就是 “分层治理 + 标准化”:

4. 数据服务:让数据 “能复用、好调用”
很多数据团队做完数据处理就觉得完事了,但其实数据的价值得通过 “服务” 才能释放出来。数据服务的本质是 “把数据变成 API、报表、标签等产品,让业务方能快速拿到需要的信息”。
关键要做好两件事:
服务标准化:定好统一的接口规范、数据格式、权限控制,对发布的 API 进行任务管理、运行监控和任务监控,查看调用情况、批量上下线 API 等。
服务产品化:把常用的数据能力打包成 “数据产品”(比如用户标签平台、实时看板、自助取数工具),让业务方用起来更方便。
5. 运维监控:让数据 “稳定、能追溯”
数据开发不是 “一锤子买卖”,上线后的运维监控也很关键。很多团队都遇到过这些问题:
任务突然失败
数据延迟变高
指标口径改了没同步
根本原因就是没有有效的运维体系。完整的运维监控要覆盖三个方面:
任务监控:实时盯着 ETL 任务、实时作业的运行状态(成功 / 失败 / 超时),设好阈值告警;
数据监控:监控数据的完整性、准确性、及时性;
血缘监控:记录数据的 “血缘关系”,上游数据变了,能自动通知下游依赖的任务和报表。
三、数据开发的底层逻辑
说到这儿,可能有人会问:“数据开发的核心要素到底是什么?” 我一直强调,技术是手段,业务是方向,人是关键。
1.技术层面
不用盲目追新,但得知道主流工具适合什么场景。比如:
离线处理用 Hive/Spark
实时处理用 Flink/Kafka Streams
数据服务用 API 网关
2.业务层面
数据开发人员必须深入业务,比如参加业务复盘会、了解运营策略,不然根本理解不了需求。
3.人层面
数据团队得打破 “技术孤岛”,和业务、产品、运营团队建立 “共建机制”,比如成立 “数据敏捷小组”,一起定义需求、迭代方案。
总结
数据开发的终极目标不是 “做出好看的报表” 或者 “搭个复杂的数仓”,而是 “用数据驱动业务决策,创造能衡量的商业价值”。不妨问问自己:
你做的每个数据项目,有没有明确对业务的贡献?
你的数据服务,业务方用得多不多?
你的运维体系,能不能保障数据稳定输出?
如果答案都是肯定的,那恭喜你 —— 你已经掌握了数据开发的 “底层逻辑”。如果不是,希望这篇文章能帮你找到改进的方向。
毕竟,数据开发的魅力,从来不是 “我能写多复杂的 SQL”,而是 “我用数据解决了多重要的问题”。
来源(公众号):五分钟学大数据




