

推理革命:强化学习如何教会人工智能真正思考
我们都对像ChatGPT这样的大型语言模型(LLM)的能力感到惊叹。它们可以写邮件、起草诗歌,并回答几乎所有主题的问题。但流畅的对话与深入的多步推理之间存在着差异。我们如何让AI不仅能检索信息,而且能真正地思考——解决复杂的数学问题、编写功能代码并规划一系列行动?

一篇全面的新综述《A Survey of Reinforcement Learning for Large Reasoning Models》描绘了人工智能发展中一个 groundbreaking 的转变历程。研究人员现在正在使用一种称为强化学习(RL)的技术,不仅是为了让模型更安全、更符合人类偏好,更是为了从根本上增强其推理能力。这正在将今天的LLM转变为大型推理模型(LRM),这标志着向更强大、更通用的人工智能迈出了关键的一步。
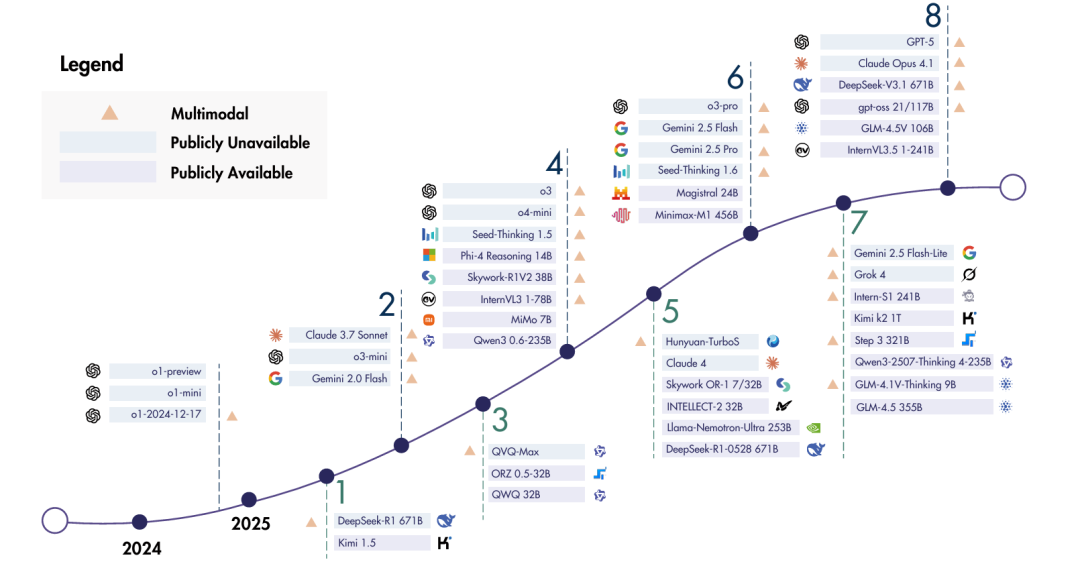
从遵循规则到解决问题
强化学习是一种训练方法,其灵感来源于我们如何从试错中学习。一个“智能体”(AI模型)通过与“环境”(一个问题或任务)交互来采取“行动”(生成文本或代码)。然后,它会根据其表现获得“奖励”。这与使AlphaGo等AI系统掌握围棋所依据的原理相同——通过进行数百万局游戏并学习哪些落子能导向胜利。
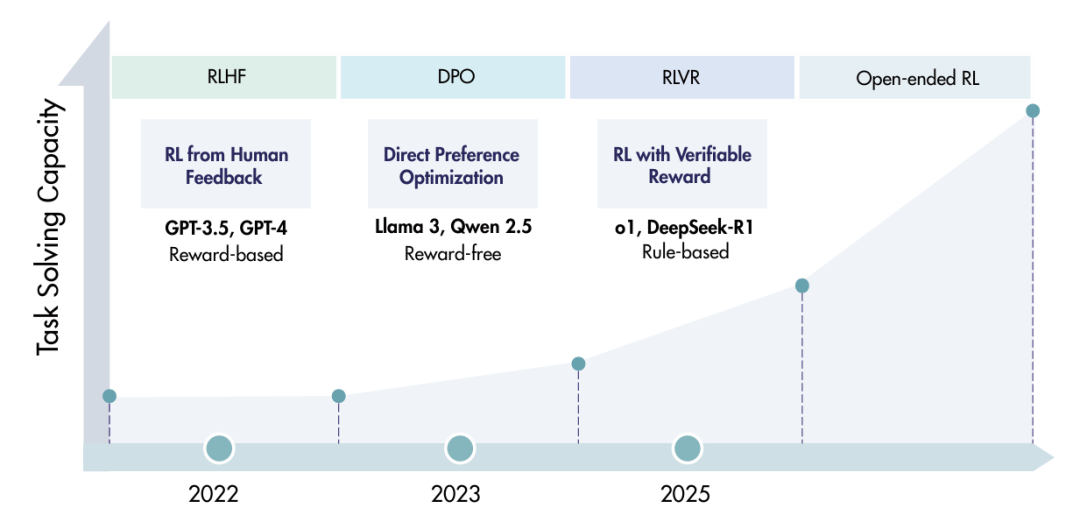
最初,RL被著名地用于在一个称为人类反馈强化学习(RLHF)的过程中,将LLM与人类价值观对齐。在这个过程中,人类评审员会对不同的AI响应进行排名,然后利用这种反馈来训练一个“奖励模型”,以引导LLM变得更有帮助、更诚实且更无害。
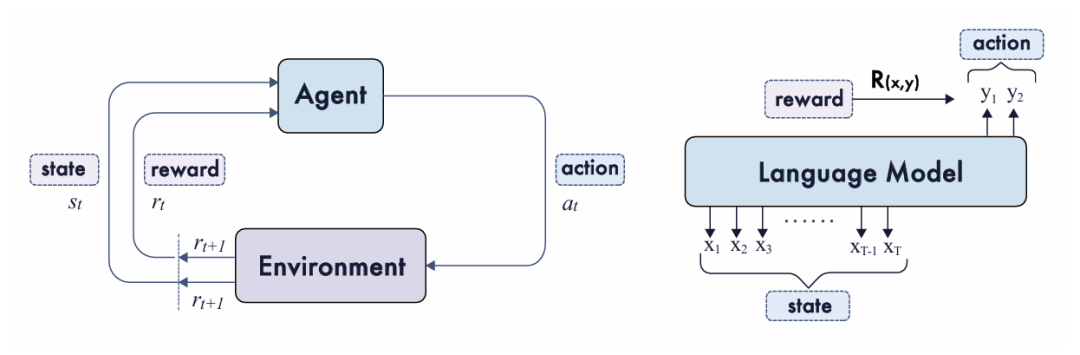
但一种新趋势已经出现,以里程碑式的模型如OpenAI o1和DeepSeek-R1为典范。这种新范式被称为带可验证奖励的强化学习(RLVR),它使用客观的、可自动检查的奖励来直接教授推理。AI不再依赖主观的人类反馈,而是为结果可验证的任务获得清晰的奖励信号:
对于数学问题,如果\boxed{...}中的最终答案正确,则给予奖励。
对于编码任务,如果生成的代码通过了所有单元测试,则给予奖励。
这个简单的转变是深刻的。它允许AI模型通过生成长思维链、探索不同策略、并逐步发现那些能导向正确答案的推理路径,来学习复杂的问题解决。它开辟了一条扩展AI能力的新途径,这条途径与仅仅增大模型规模是互补的。
训练师的工具包:用于推理的RL核心组件
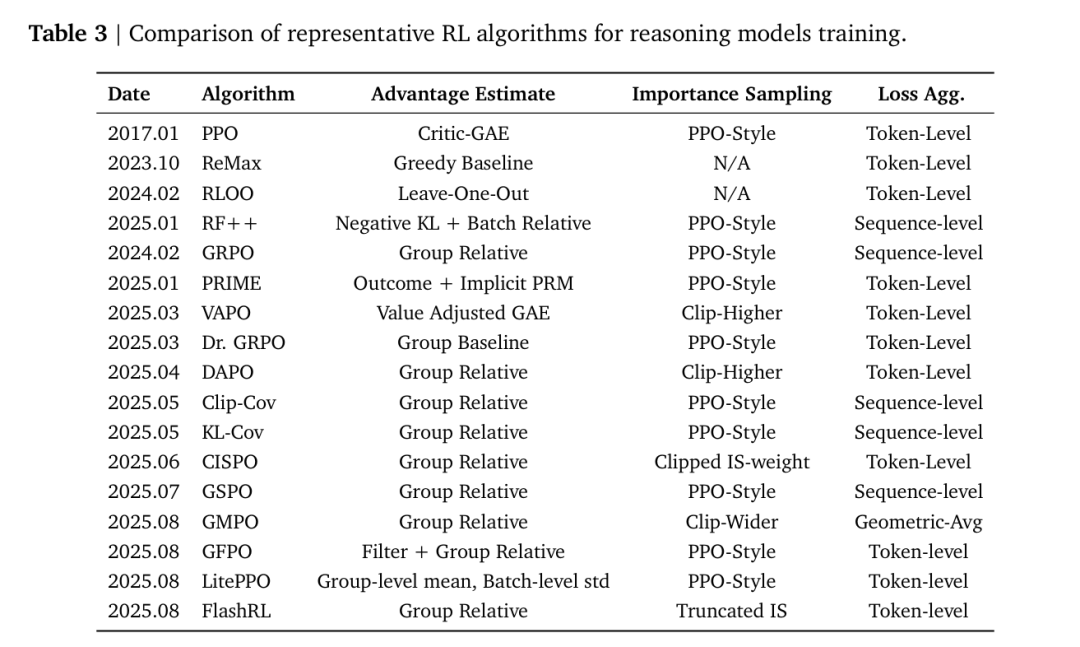
该综述将训练LRM的整个过程分解为三个基础组成部分。可以将其视为思维机器的完整训练方案。
奖励设计:定义“做得好”:RL的核心是奖励。论文探讨了设计这些信号的几种方式:
可验证奖励:如前所述,这些是清晰的、基于规则的信号,如正确的数学答案或通过的代码测试。它们具有可扩展性和可靠性。
生成式奖励:对于更主观的任务(如评判故事的质量),可以使用另一个强大的AI作为评判员来提供批评和分数,充当“生成式奖励模型”。
密集奖励:模型不仅能在最后获得奖励,还能在其推理链的每个中间步骤获得反馈。这就像一位老师在整个问题解决过程中给予指导。
无监督奖励:在这里,模型学会根据内部信号(如其自身答案的一致性或其置信度)来自我奖励,从而消除了对外部标签的需求。
策略优化:学习算法:一旦AI获得奖励,它需要一个机制来更新其内部“策略”,以便下次做得更好。该综述详细介绍了算法从标准的PPO(近端策略优化)到无评论者方法(如GRPO(组相对策略优化))的演变,后者因其在大规模训练中的简单性和高效性而变得流行。这些算法是将奖励信号转化为改进的推理能力的数学引擎。
采样策略:智能练习:AI不仅仅是从静态的教科书中学习。它通过积极尝试解决问题来学习。采样策略是关于选择处理哪些问题。例如,动态采样策略可能会将AI的训练时间集中在既不太容易也不太困难的问题上,确保每个计算周期都用于学习一些有用的东西。
大辩论:AI训练中的基础问题
虽然进展迅速,但该领域正在努力解决几个基本且有争议的问题。该综述巧妙地概述了这些开放性问题:
锐化 vs. 发现:RL仅仅是“锐化”模型从初始训练中 already latently 具备的推理能力吗?还是它能导致“发现”真正新的问题解决策略?证据好坏参半,一些研究表明RL主要 refine 现有技能,而另一些则显示它可以推动模型能力的边界。
RL vs. SFT(泛化 vs. 记忆):RL与标准的监督微调(SFT)相比如何?在SFT中,模型只是学习模仿正确的例子。一个引人注目的结论正从最近的研究中浮现:“SFT memorizes, RL generalizes。” RL倾向于产生在未见过的、新问题上表现更好的模型,而SFT可能导致对训练数据的过拟合。
过程 vs. 结果:我们应该奖励模型获得正确的最终答案(结果),还是奖励其正确的逐步推理过程?奖励结果更容易扩展,但这可能会鼓励AI寻找捷径或产生不忠实的思维链。奖励过程确保了忠实的推理,但监督成本要高得多。
现实世界中的RL:推理AI的应用
这些方法的最终检验是它们的现实影响。该综述强调了在广泛应用中取得的惊人进展:
编码任务:经过RL训练的模型正在超越简单的代码生成,去应对竞争性编程、领域特定代码(如SQL),甚至仓库级的软件工程挑战,如代码修复和质量改进。
智能体任务:这是AI学习使用工具的地方。借助RL,智能体可以学习浏览网页查找信息、使用计算器,或与图形用户界面(GUI)交互以完成任务,更像自主助手一样行动。
多模态任务:推理不仅限于文本。RL正被用于训练能够理解和推理图像、视频甚至3D环境的模型。这包括从回答关于视频的复杂问题到生成符合特定、细致入微指令的图像等一切。
机器人技术与医学:RL正在帮助弥合机器人的仿真与现实世界之间的差距,让视觉-语言-动作(VLA)模型能够以最少的人类数据学习操作任务。在医学领域,它正被用于增强诊断推理、解读医学图像,甚至优化治疗计划。
正如近期模型的时间线所示,该领域的创新速度惊人,新的开源和专有模型不断推动着前沿。
前路指南
该综述通过展望未来作为结尾,概述了几个令人兴奋的方向。这些包括开发能够在其整个生命周期中持续学习(持续RL)的AI、构建具有鲁棒记忆系统(基于记忆的RL)的模型,甚至使用RL来共同设计未来AI模型的架构。
这篇论文提供了一幅正处于革命中的领域的重要地图。通过利用试错学习的原则,研究人员正在构建的AI不仅仅是模仿智能,而是在积极培养智能。从大型语言模型到真正的大型推理模型的旅程正在进行中,而强化学习是推动它向前发展的引擎。
来源(公众号):AI Signal




