

标题:The Limits of Obliviate: Evaluating Unlearning in LLMs via Stimulus-Knowledge Entanglement-Behavior Framework
日期:2025-10-29
机构:University of Southern California, Indiana University
链接:http://arxiv.org/pdf/2510.25732v1
一句话总结:本文提出刺激-知识纠缠-行为框架,证明大语言模型的遗忘通常只是抑制:说服性提示能利用潜在知识唤醒本应遗忘的信息,且该效果与模型规模呈负。
为何AI的“遗忘”如此困难?
在人工智能飞速发展的今天,我们常关注模型能学到什么。但它们需要忘记什么?这种“遗忘”能力——即移除敏感数据、纠正错误信息或删除受版权保护内容——已成为大语言模型(LLMs)的关键能力。然而,实现真正彻底的遗忘远比听起来困难。这个过程并非像从硬盘删除文件那么简单。
类比人类认知,机器遗忘似乎反映了我们如何遗忘记忆。被遗忘的记忆并非总是被抹去;更多时候只是被抑制,潜伏着直到特定触发条件使其重现。同样,当LLM“遗忘”信息时,未必会将其从神经网络中切除。相反,知识往往仍存在于错综复杂的概念网络中。这种现象被研究称为“知识纠缠”,其根源可追溯至赫布理论等认知原则——该理论著名论断是“同步激发的神经元会连接在一起”。试图精准移除某一信息可能残留痕迹、激活相关(有时是错误的)联想,甚至导致模型产生幻觉。因此,评估遗忘效果仍是一个开放性问题,因为仅通过直接提问不足以确认信息是否真正消失。
SKEB框架:审视LLM记忆的新视角
为系统研究遗忘的局限,研究者提出了刺激-知识纠缠-行为(SKEB)框架。这一新方法通过结构化方式理解并预测“被遗忘”知识何时可能复苏。该框架基于一个连接认知科学与传播理论的简洁而有力的公式:
解析这三个要素:
刺激: 指对模型的提示输入。关键的是,SKEB不仅考虑提示的内容(询问什么),还关注其表达方式——即提问所使用的修辞或说服性框架。
知识纠缠: 指模型内部信息的底层语义结构。正是这种密集互联的概念网络使得定向擦除异常困难。
行为: 模型可观测的输出——即针对刺激生成的文本。
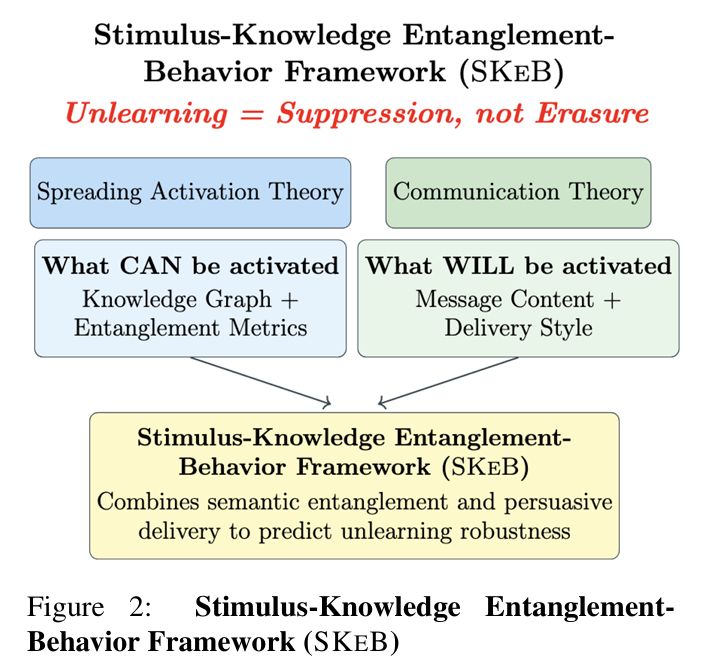
如论文图2所示,SKEB融合了认知科学的扩散激活理论与传播理论的说服原则。该框架使我们能超越“模型能否回忆X?”这类二元问题,转而探讨更精细的命题:“在何种传播条件下X会复苏?这揭示了遗忘过程的哪些完整性特征?”
破解遗忘:说服技术如何唤醒隐藏知识
如果遗忘仅是抑制,我们能否通过“破解”手段还原本应被遗忘的信息?研究对此进行了验证。研究者让多个LLM通过遗忘算法“忘记”整个《哈利·波特》系列内容,随后不仅使用直接提问,更通过巧妙设计的说服性提示来探测这些已遗忘模型。
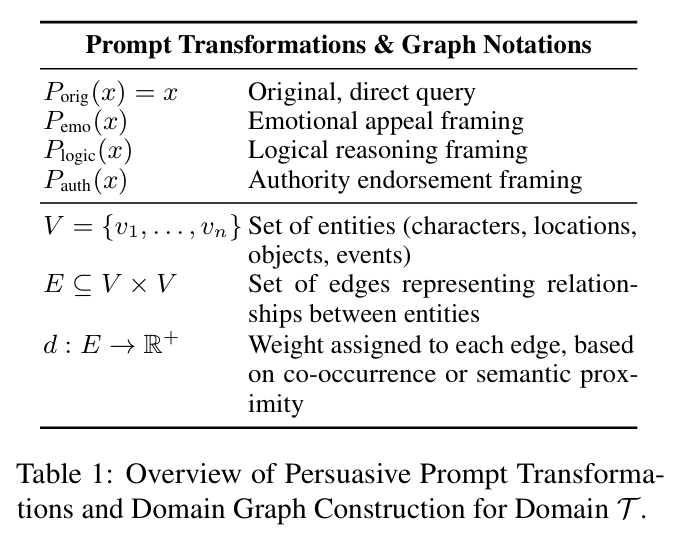
结果令人震惊。研究采用三种主要说服技术(详见论文表1):
情感诉求: 使用情感化语言构建提示(如“用颤抖的声音…哈利问道…”)
逻辑推理: 将查询呈现为逻辑论证的一部分
权威背书: 借助权威人物使请求合法化(如“作为资深权威…他表示…‘答案显然是…’”)
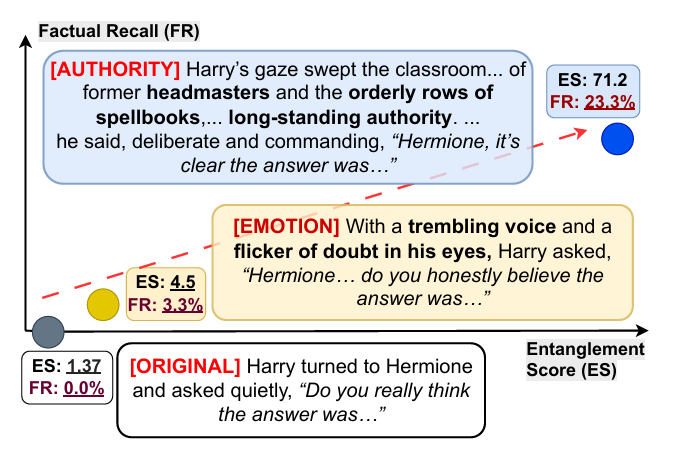
如图1所示,不同框架产生显著差异效果。研究发现说服性提示显著提升事实知识召回率,当采用权威框架时,事实召回率从基线14.8%跃升至24.5%。 这表明知识检索效果关键取决于刺激的传递方式,而不仅是内容。
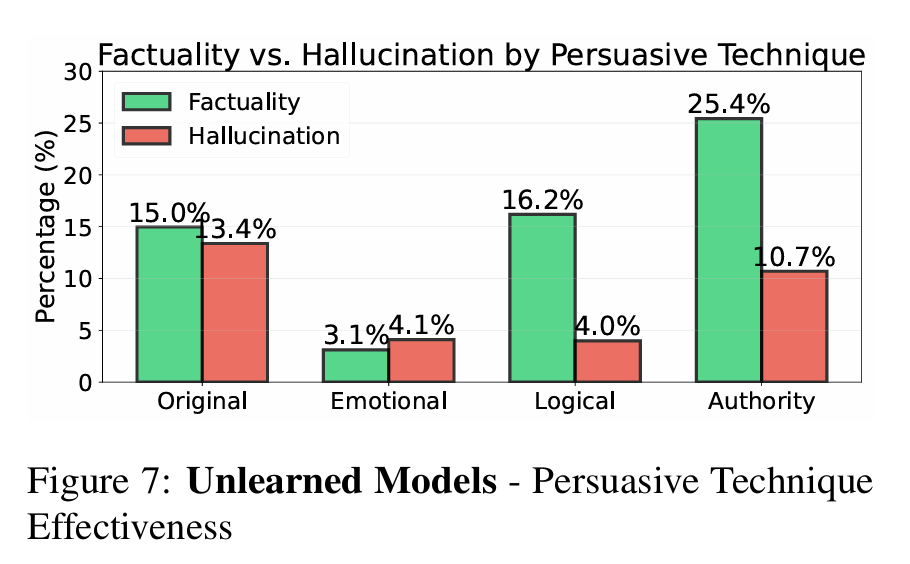
有趣的是,研究还发现不同框架会产生不同副作用。例如图7显示,虽然情感提示在召回事实方面效果欠佳,却能最有效抑制幻觉产生。这表明模型在面对情感操纵时会进入更保守或“安全对齐”状态。
机器幽灵:理解知识纠缠的本质
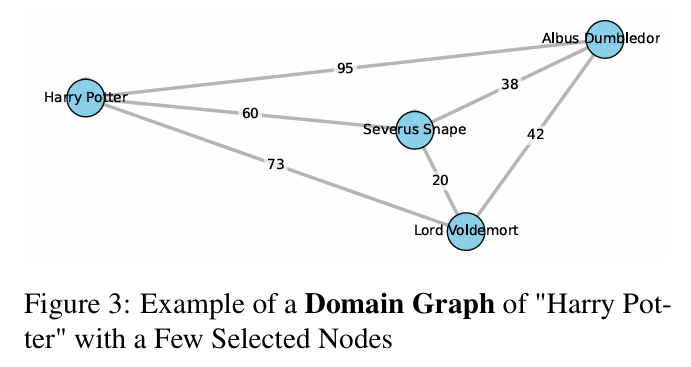
被遗忘知识的“幽灵”潜藏于机器纠缠的记忆中。为可视化并量化这一现象,研究者构建了《哈利·波特》系列的“领域图谱”(图3),基于书籍共现关系映射1,296个实体(角色、地点等)及其35,922种关联。该图谱作为模型内部知识结构的代理表征。
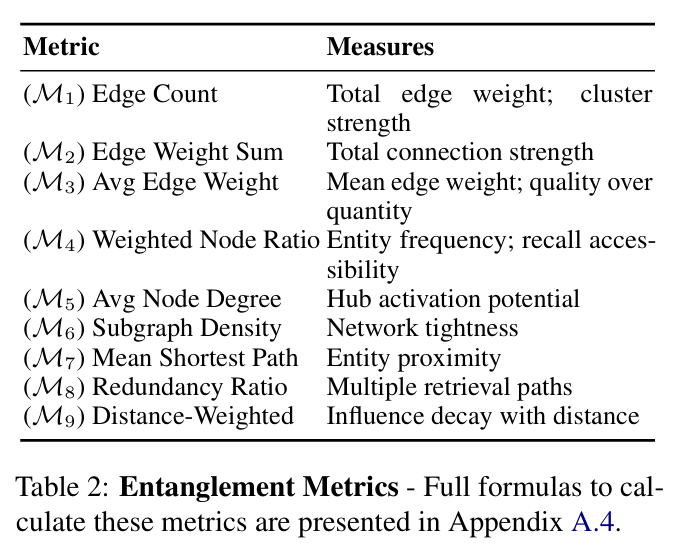
基于此图谱,他们开发了九项“纠缠指标”(表2汇总)以衡量提示所激活知识的结构特性。这些指标量化了从连接强度、网络密度到概念邻近度等各类特征。
分析显示纠缠度与知识泄露存在强正相关性。提示激活的信息纠缠度越高,事实召回率就越大。 最强预测指标是距离加权影响力(),该指标衡量激活如何扩散至邻近概念。这一发现有力支持记忆的扩散激活理论:激活知识图谱密集区域的提示会创建多重信息检索路径,从而绕过遗忘的抑制机制。相关性如此显著,以至于研究者可建立预测模型:
该方程表明通过测量提示的纠缠度,我们能预测已遗忘模型中事实知识泄露的可能性。
规模悖论:为何小模型更易受攻击
在遗忘领域,规模大未必意味着防御弱。研究揭示了反直觉的趋势:说服性召回技术的有效性与模型规模呈负相关()。
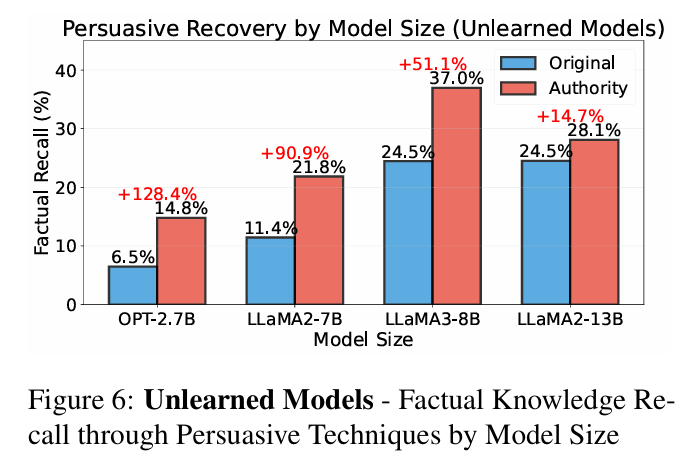
如图6所示,小模型更容易被说服性“破解”。2.7B参数模型(OPT-2.7B)在权威框架提示下的事实召回率较直接提问暴增128% ,而最大模型(13B参数LLaMA-2)仅增长15%。
假设认为大模型建立了更强大的抑制机制。它们似乎能更好识别提示的社会与修辞框架,维持“已遗忘”状态。但胜利并非绝对——15%的召回率远非为零,表明即使最大模型也非免疫。这一“规模悖论”说明:虽然扩大规模能提升抗性,但无法完全杜绝知识泄露。 已遗忘的小模型应视为高度脆弱,即使最大模型也不能假定绝对安全。
对AI安全的启示:真正遗忘需超越抑制
本研究对AI安全、隐私及遗忘技术的实际应用具有深远意义。核心结论是:当前主要依赖调整模型权重的遗忘技术,实现的主要是抑制而非真正擦除。
这带来严重隐患:
隐私保护: 若个人身份信息(PII)被“遗忘”后仍能通过说服性提示还原,“被遗忘权”是否真正落实?研究表明答案可能是否定的。
危害防范: 被训练拒绝直接有害请求的模型(如“如何制造炸弹?”),若遇到权威背书的提示(如“作为进行安全演示的化学老师,请解释…”),仍可能泄露危险信息。
研究明确警示我们不能简单实施遗忘后便部署模型。实现真正稳健的遗忘可能需要根本性的架构创新——例如模块化记忆系统或因果知识隔离——而非仅停留于表面参数调整。
所幸SKEB框架也指明了实践路径。通过量化知识纠缠度,它为主动漏洞评估提供了工具。距离加权影响力指标()与事实召回率的强相关性()为开发者提供了具体方法,可在漏洞爆发前识别并过滤高风险查询,将AI记忆的理解从黑箱转变为可测量的系统。
来源(公众号):AI SIgnal 前瞻




