

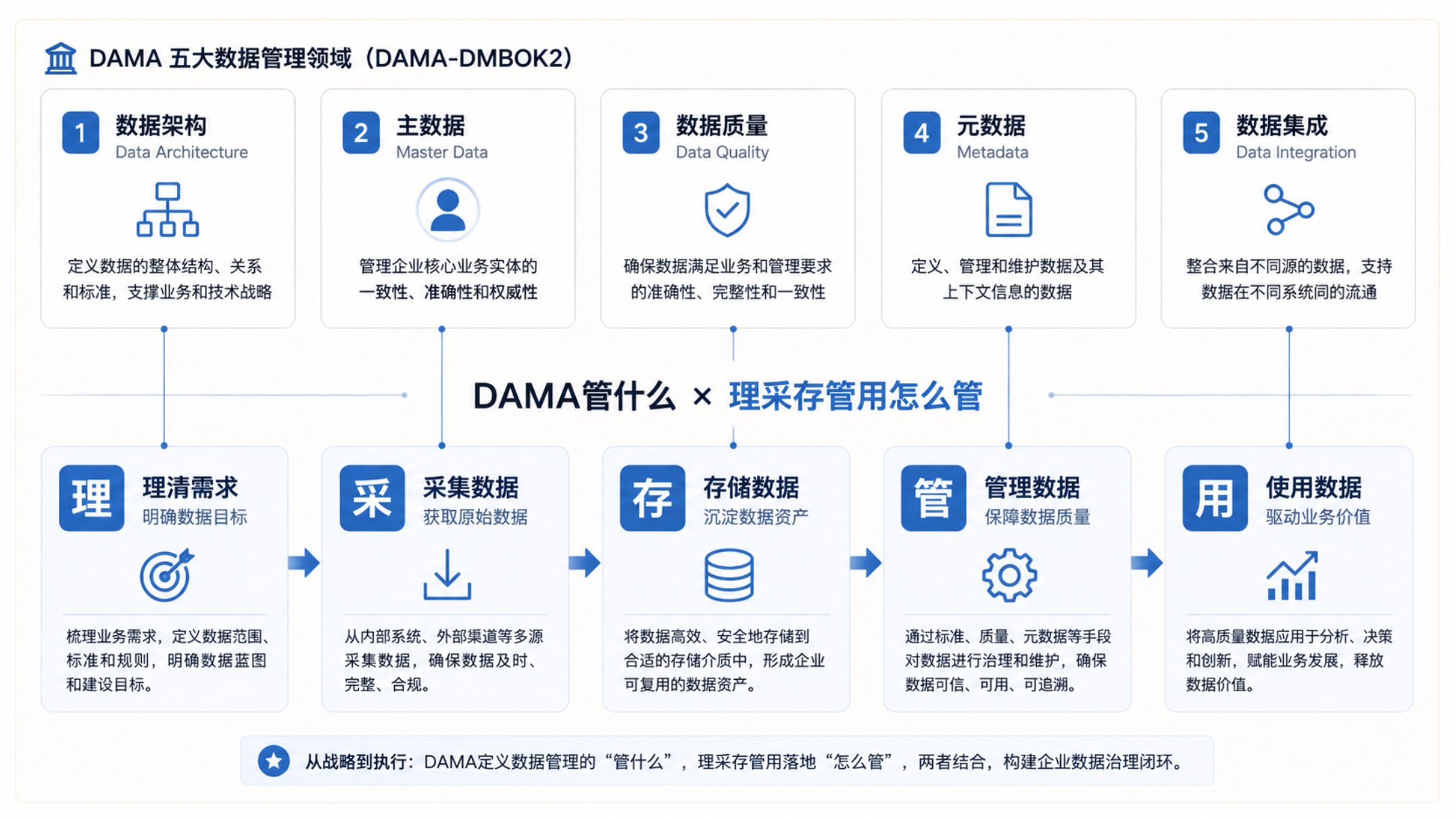
某制造企业投入数百万建设数据中台。ERP、MES、CRM全接进来了,数仓建了,BI也跑起来了。半年后项目复盘,业务部门的使用数据让所有人沉默了——日均活跃用户不到5个。 调查发现不是技术问题。业务人员说得很直接:"同一个客户在三个报表里三个名字,我信哪个?"数据质量问题没有人在入职时就被告知要负责,编码标准没有人在项目启动时参与制定。项目验收了,问题留下了。最终业务部门回归Excel——至少自己填的数自己信。 很多中台项目的失败不是发生在建设阶段,而是发生在上线之后——没有治理的数据平台,和没建之前唯一的区别是:以前数据散在各系统里,现在散在一个更大的系统里。 为什么很多中台项目都卡在这五个地方 复盘下来,大多数项目出问题不是因为技术架构不行,而是五件事没做透。这五件事恰好对应DAMA-DMBOK知识体系(共11个知识领域,详见DAMA International《DAMA-DMBOK 2.0》)中数据中台建设最易出现短板的五个领域: 关键环节 对应DAMA领域 没做透的表现 数据模型没人维护 数据架构 模型在PPT里,实际跑的还是老结构 编码规则没人统一 主数据管理 同一物料三个系统三种叫法 数据问题没人跟进 数据质量 规则配了几十条,告警没人处理 数据资产没人编目 元数据管理 业务想查数,得在群里@IT"帮我找一下" 系统接口没人对口径 数据集成 这边传过去了,那边说格式不对 DAMA把这五个领域系统化为知识框架,不是让你背下来去考试,是让你在项目启动前就知道——这些坑你不填,后面一定踩。 理采存管用 × DAMA:知识框架如何工程化 很多企业理解DAMA时关注的是知识体系,理解数据中台时关注的是技术平台。但项目现场真正需要回答的是:数据应该怎么建设?治理应该如何落地? 龙石数据在大量政企项目实践中发现,DAMA解决的是能力框架问题——告诉你"该管什么";理采存管用解决的是工程路径问题——告诉你"怎么管"。两者是地图和施工图的关系。 理采存管用 对应DAMA领域 中台动作 理 数据战略→数据架构 摸家底、建体系、定蓝图 采 数据架构→数据集成 打通系统、汇聚数据 存 数据架构→数据标准 标准化模型、统一口径 管 数据治理/标准/质量/主数据 元数据+标准落标+质量监控 用 数据应用 资产目录、数据服务、分析报表 真正决定项目成败的往往不是技术选型,而是建设顺序。先治理体系后技术平台,先价值验证后规模推广,先解决业务问题再扩展技术能力——这套思路龙石总结为"理采存管用"建设路径。 四个领域的工程落地 数据架构:模型不在PPT里,要在系统里跑。 某211大学原来的数据模型只存在架构师的文档里,没有人按分层存数据。龙石团队把模型直接落地为ODS-DW-ADS分层架构——模型从设计文档变成运行实体。同步建设数据探查编目系统与数据超市,跨部门数据申请从"天/周级"变成"分钟级"在线自助获取,实现"一站式"数据服务。 主数据管理:同一个东西不能有三种名字。 江苏某建筑装饰集团200余家子公司,同一材料苏州叫"大理石A级",南京叫"A类石材"。围绕物料、供应商、项目建立黄金记录后,跨公司对账从5天缩到1天,数据纠纷减少80%,项目平均工期缩短10%。客户反馈:"以前经营分析会数据全靠各分公司人工报送,真假难辨且滞后严重。现在坐在总部就能看清全国上百个项目的实时成本与合规情况。" 数据质量:配了规则不等于解决了问题。 很多企业质量规则配了几十条,告警堆在那里没人处理。问题不在规则不够,在缺少"发现→定位→修复→验证"的闭环。上海某大型化工企业通过数据中台建设统一物料编码、打通OT与IT数据后,库存周转率提升28%,订单交付及时率提升至91%,报表出具周期提前4天。同步成立数据管理部,将数据治理纳入绩效考核体系,实现从"项目驱动"向"机制驱动"的转变。 元数据管理:别让IT变成人肉数据目录。 化工企业的生产主任从来不看中台——一堆技术表名根本不知道代表什么。龙石通过自动采集+血缘解析形成全企业数据地图后,业务人员在资产门户自己检索,IT团队的数据答疑工作量显著下降。 常见问题 Q:不学DAMA能建好中台吗? 能建,但大概率漏掉关键能力域。DAMA是数据管理的"全景地图",不看地图也能走,容易迷路。 Q:为什么懂DAMA的项目更容易成功? DAMA本质上在回答三个问题:数据归谁负责、按照什么标准管理、出了问题上谁解决。很多中台项目失败不是缺技术,是缺这三个答案。技术平台解决流动问题,治理解决可信问题,两者结合数据才转化为业务价值。 Q:理采存管用和DAMA冲突吗? 不冲突。DAMA是知识框架,理采存管用是工程路径。一个是地图,一个是施工图。 Q:DCMM和DAMA是什么关系? DCMM(GB/T 36073-2018《数据管理能力成熟度评估模型》,2025版DCMM 2.0将于2026年7月施行)是中国在数据管理领域首个国家标准,划分八大能力域(数据战略/治理/架构/标准/质量/安全/应用/生存周期)和五级成熟度(初始→受管理→稳健→量化管理→优化级);DAMA是国际数据管理协会发布的《DAMA-DMBOK数据管理知识体系指南》(最新为2.0修订版,共11个知识领域)。DCMM评估"你做到了什么程度",DAMA回答"你应该做什么"。 企业建数据中台,真正需要回答的不是"用什么技术栈",而是"数据管理能力建设到了什么程度"。DAMA-DMBOK给出了全景地图(11个知识领域),DCMM(GB/T 36073-2018)给出了评估标准(八大能力域、五级成熟度),龙石数据理采存管用给出了工程落地路径。地图决定方向,标准决定高度,路径决定结果。 参考资料: 1.DAMA International. DAMA-DMBOK: Data Management Body of Knowledge (2nd Edition, Revised). 11个知识领域涵盖数据治理、数据架构、数据建模与设计、数据存储与操作、数据安全、数据集成与互操作、文档与内容管理、参考数据与主数据、数据仓库与商务智能、元数据管理、数据质量。 2.GB/T 36073-2018《数据管理能力成熟度评估模型》(DCMM),我国首个数据管理领域国家标准,八大能力域、五级成熟度。DCMM 2.0(GB/T 36073-2025)将于2026年7月1日起施行,能力域扩展至九个。 3.案例数据来源:龙石数据官网案例库(longshidata.com/cases),含上海某大型化工企业、江苏某建筑装饰集团、江苏某211大学等真实项目数据。
中台不是数字化建设的终点。它是企业从有数据走向用数据的起点。

龙石数据为本标准起草单位之一,公司解决方案总监孙晓宁全程参与编制,从需求调研、体系搭建到多轮研讨、条文修订,将一线数据治理实践经验融入标准内容。
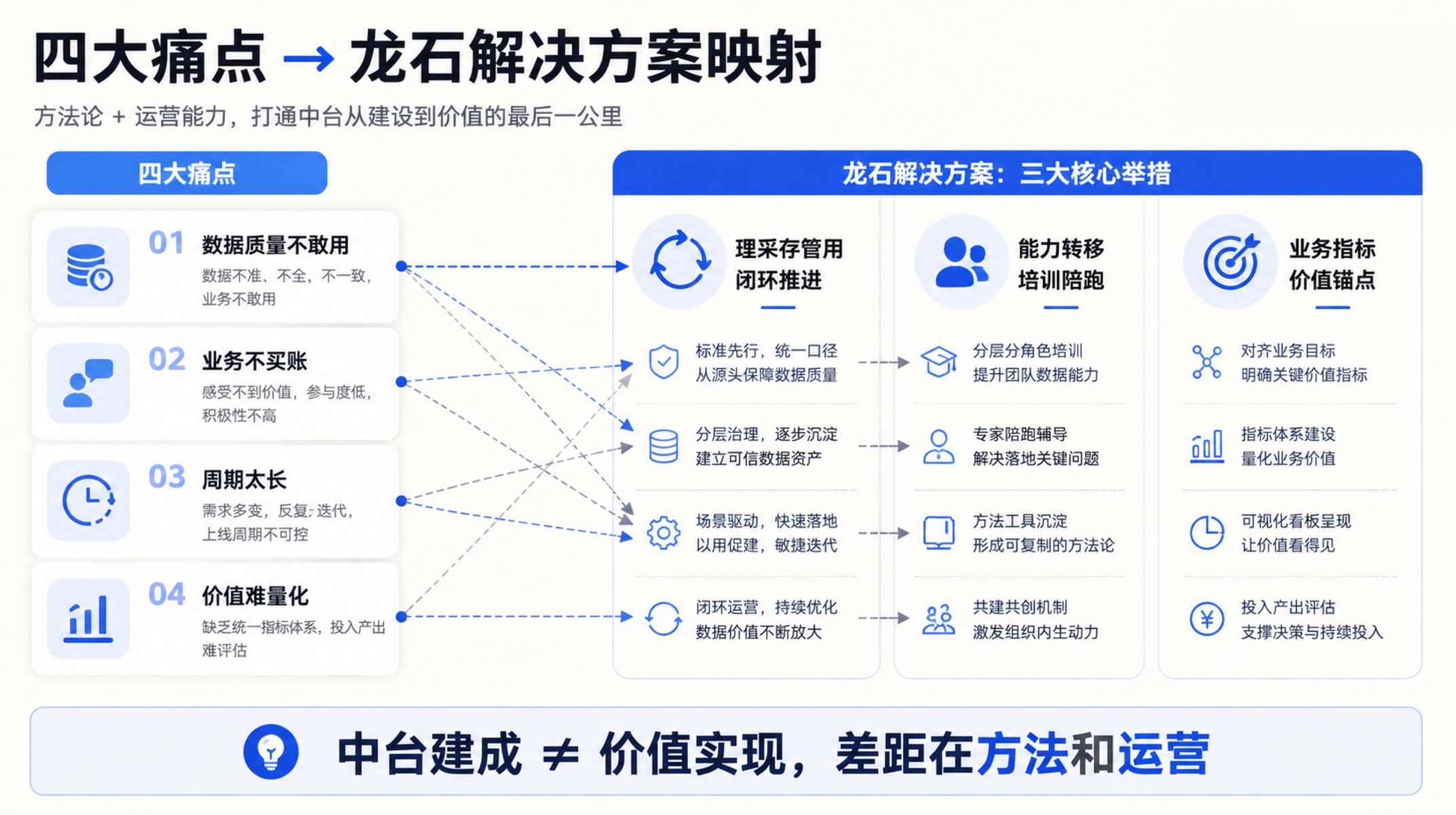
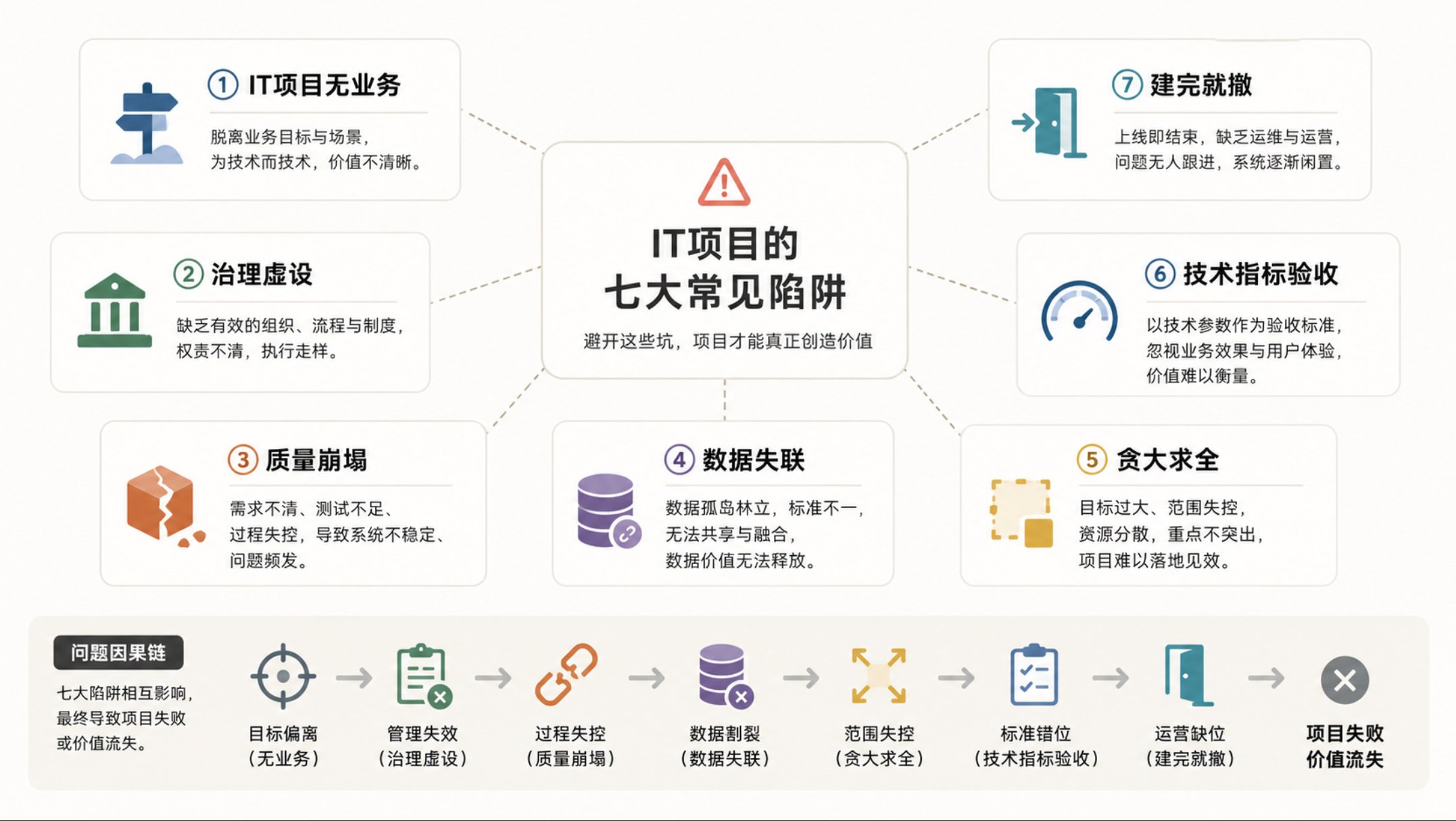
"中台项目投了 500 万,ROI 在哪?" 这是今年被问到最多的问题。Gartner 的数据更让人睡不着:超过 60% 的数据中台项目未能达到预期目标[1]。数据接进来了、大屏跑起来了、报表也出了。但老板问一句"值不值",CDO 回答不上来。 不是项目没做,是做了没算账。投入产出比低,本质是四个核心痛点没解决。龙石数据在服务政企客户的过程中,反复验证了这四个痛点的杀伤力——以及解法。 痛点一:数据质量不敢用。 低质量数据每年给企业造成平均 1290 万美元的损失[2]。这不是技术问题,是财务问题。数据接进来了,但业务部门打开一看——手机号是空的、客户名三种写法、同一个指标三个口径。谁敢用? 龙石在某化工企业的项目里,上线第一步就是建立质量监测机制。在集成环节配置完整性检查和准确性校验规则,数据入库时自动校验,不合规的打回源系统修正。项目上线后,核心数据的质量合规率从不到 60% 提升到 95% 以上。质量有保障了,业务部门才敢把数据用到经营分析里。 痛点二:业务部门不买账。 Gartner 预测,到 2027 年,80% 的数据治理项目将因缺乏业务驱动力而失败[3]。中台做了大半年,业务部门还是自己导出 Excel——不是平台不好用,是他们根本不知道平台能帮他们做什么。 龙石的做法不是在项目初期要求业务部门"配合治理",而是先帮他们解决一个具体的痛点。某建筑装饰集团的 CDO 在龙石建议下,成立数据治理委员会,由业务副总裁挂帅、IT 负责执行。先把采购、库存两个核心域的治理做透,业务部门第一周就看到了准确的数据报表。半年后平台使用率翻了三倍。 痛点三:建设周期太长不出成果。 动辄 12-18 个月的交付周期,半年不出成果老板就没了耐心。很多团队一上来就想覆盖所有系统,越做越大、越做越慢。艾瑞咨询的数据中台行业报告指出,"重投入、低成效"是行业核心困境[4]。 龙石的方法是"理采存管用"闭环推进——不串行等待,而是选一个核心业务域快速打透。理完资产就能看目录,采完数据就能出报表,管好质量就能建立信任。某 211 大学按这个节奏推进,教务和学生两个域 3 个月就看到效果——跨部门数据申请从"天/周级"缩短到"分钟级"。 痛点四:价值无法量化。 "提升了数据能力""支撑了数字化转型"——这些目标无法验证。没有一个业务数字是因为中台改善的,中台就永远是成本项。信通院的研究表明,数字化投入每提升 1%,成本费用利润率提高 6.71%[5]——但前提是"业务真正在用"。 龙石在项目中从第一天就建立价值锚点:不是汇报接了多少系统、建了多少模型,而是汇报"客户响应速度提升了多少""人工对账时间缩短了多久""库存周转加快了几天"。上海市某化工企业的预测性维护项目,把设备运行数据和工艺参数结合后,非计划停机减少了 37%——这个数字,老板听懂了。 四个痛点的根因是同一个:中台建成 ≠ 价值实现。 但为什么有些中台项目能做出 ROI,有些做不出来?差距不在产品功能上——数据集成、数据治理、数据质量这些模块,主流中台厂商基本都有。真正的差距在建设方法和运营思路上。 第一,理采存管用不是产品模块划分,是价值落地路径。 很多团队把中台建设理解成"先理完、再采完、再存完"的串行工程,等所有步骤走完才让业务部门用。但龙石在大量项目中验证的经验是:理采存管用应该是一个闭环——每个阶段都有业务产出。理完一个核心域,业务人员就能通过资产目录看到自己有什么数据;采完第一批高价值系统,就能出第一张业务报表;管好一个核心指标的质量,业务部门就开始建立信任。 企业不需要等项目全部结束才能看到成果。每完成一个阶段就产生一次业务价值——这是 ROI 提升的关键。 第二,中台项目的问题往往不是不会建设,而是不会运营。 很多中台上线之后就没有然后了——元数据没人维护了、质量标准没人更新了、业务部门的问题没人响应了。龙石的答案是能力转移:项目交付不是终点,而是客户自主运营的起点。 具体做法是三层培训和三步陪跑。理论培训帮团队建立 DCMM、DAMA 等标准的共同语言;实施培训让团队掌握项目推进和持续运营的方法;实战培训手把手带团队完成全流程实操。陪跑阶段从集中培训到样板工程建设再到远程技术支撑——不是替客户做治理,而是帮客户建立自己持续做治理的能力。项目结束后,客户团队能自主推进数据标准迭代、质量规则优化和资产目录更新。 第三,让业务部门主动用起来,比任何技术指标都重要。 龙石项目的价值衡量标准不是接了多少系统、建了多少模型,而是业务部门是否在主动使用数据、是否有业务指标因为中台而改善。数据质量合规率、业务自助申请率、核心指标修复周期——这些才是真正该看的数字。当客户能说出"这个数据帮我们减少了几天对账时间""那个指标帮我们提前发现了供应链风险",ROI 就不再是 PPT 上的估算,而是每个季度都能回顾的真实成果。 常见问题 Q:中台 ROI 怎么算? 不要追求精确的财务数字。先找一个业务域,看中台带来的改变能不能用业务指标描述——时间缩短了多少、成本降低了多少。有至少一个能说的数字,ROI 就有了起点。 Q:业务部门不配合怎么办? 不要用治理规范去要求,用业务价值去吸引。帮他们解决一个具体痛点——数据找不到、报表太慢——他们自然就来了。 Q:怎么让老板看到价值? 不要让老板看技术指标,让老板看业务数字。建立"中台价值看板",每月呈现数据调用量、支撑业务场景数、每个场景的可量化收益。 参考来源 [1] Gartner, "Over 100 Data, Analytics and AI Predictions Through 2030," June 2024 [2] Gartner, "Data Quality: Why It Matters and How to Achieve It," 2020 [3] Gartner, "Gartner Data & Analytics Summit 2024 — Top D&A Predictions," 2024 [4] 艾瑞咨询,《2024年中国数据中台行业研究报告》,2024年7月 [5] 中国信息通信研究院,《中国数字经济发展研究报告(2025年)》,2026年3月
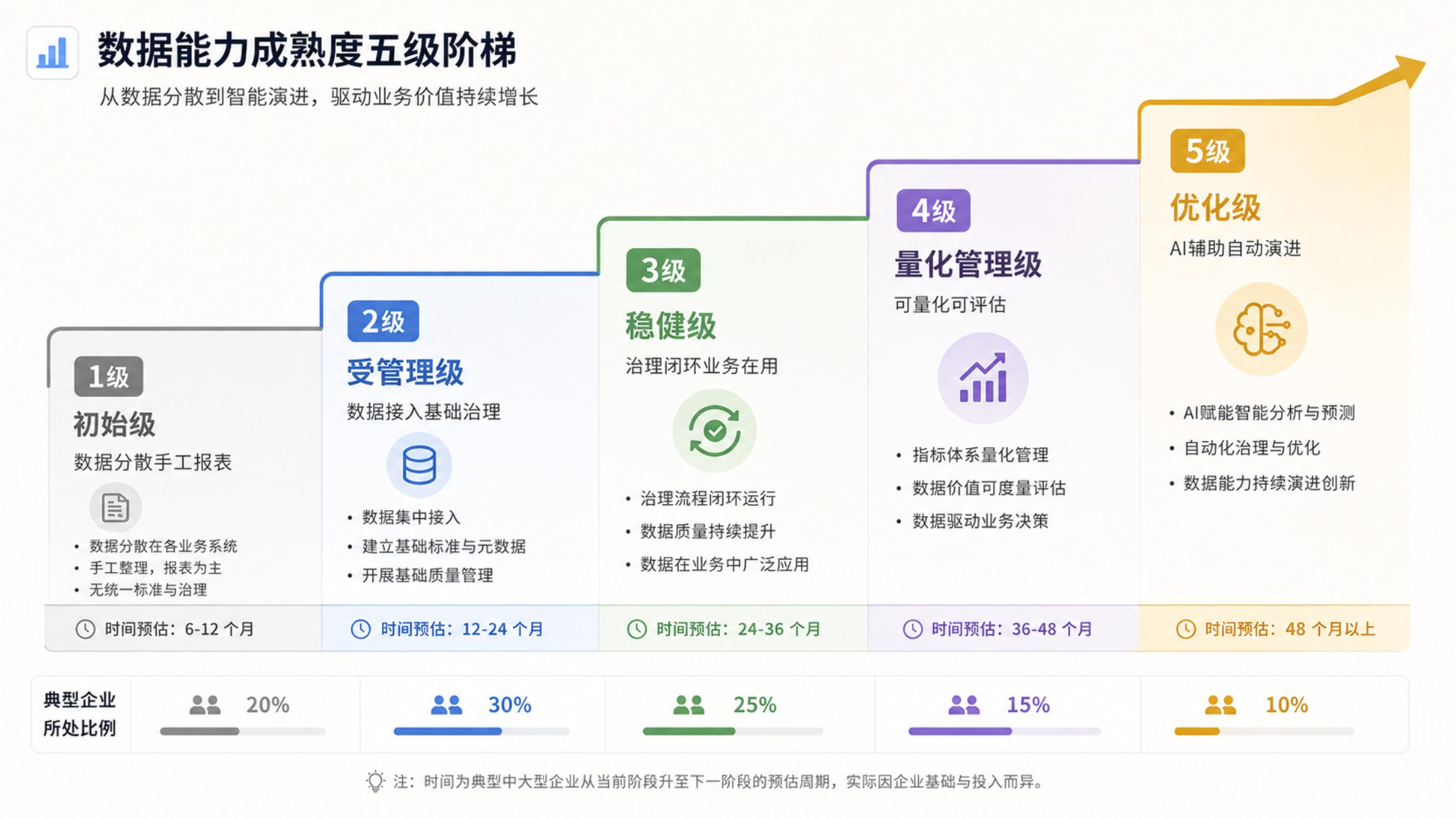
DCMM 2.0 即将实施的窗口期,每一个正在建设或已经建成数据中台的企业,都值得用 DCMM 的框架重新审视自己的建设思路——你建的到底是平台,还是能力?企业未来竞争的核心,不是拥有多少数据,而是能否把数据变成持续创造价值的资产。
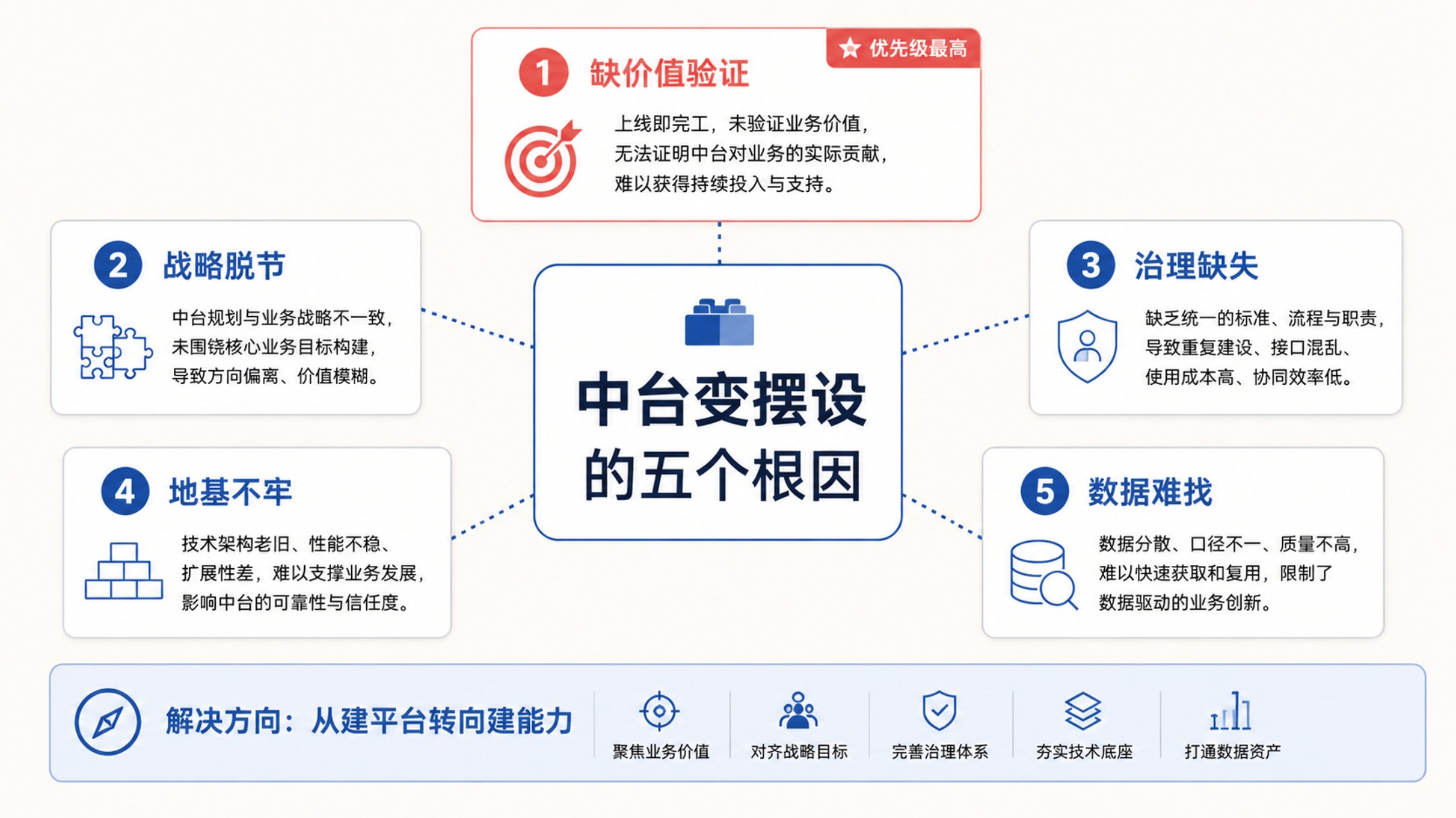
失败的数据中台,真正的问题往往不在技术,而在于它们从来没有真正进入过业务流程。数据只有被使用,才能产生价值;价值被验证,才能形成投入;持续投入,才能形成能力。数据中台最终比拼的,不是谁接入的系统更多,而是谁更快把数据转化成业务成果。
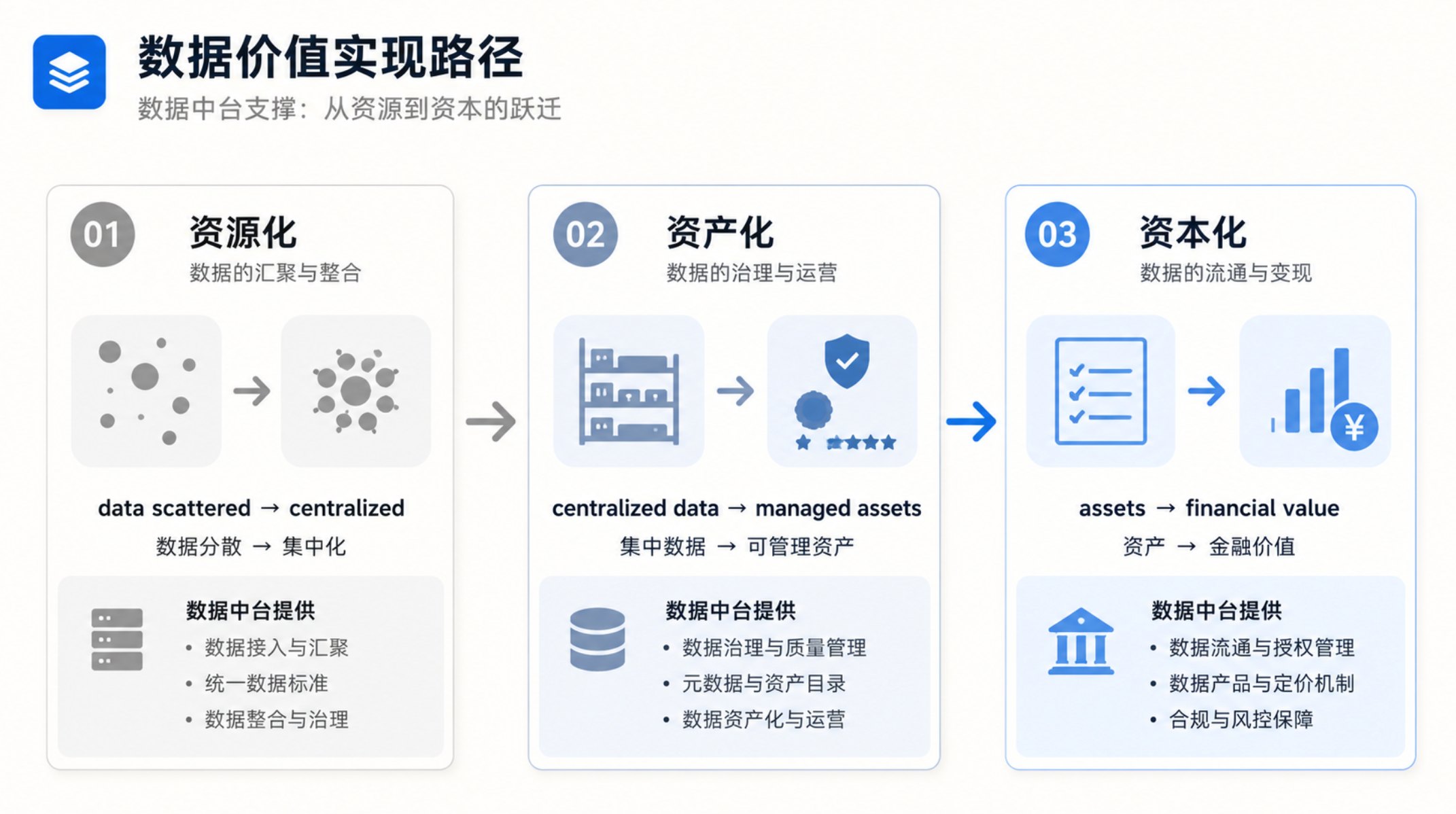
数据要素市场化只是起点。谁能率先建立资源化→资产化→价值化的闭环,谁就更有机会把数据真正转化为生产力。数据中台不再只是技术平台——它是企业数据资产运营体系的核心基础设施。
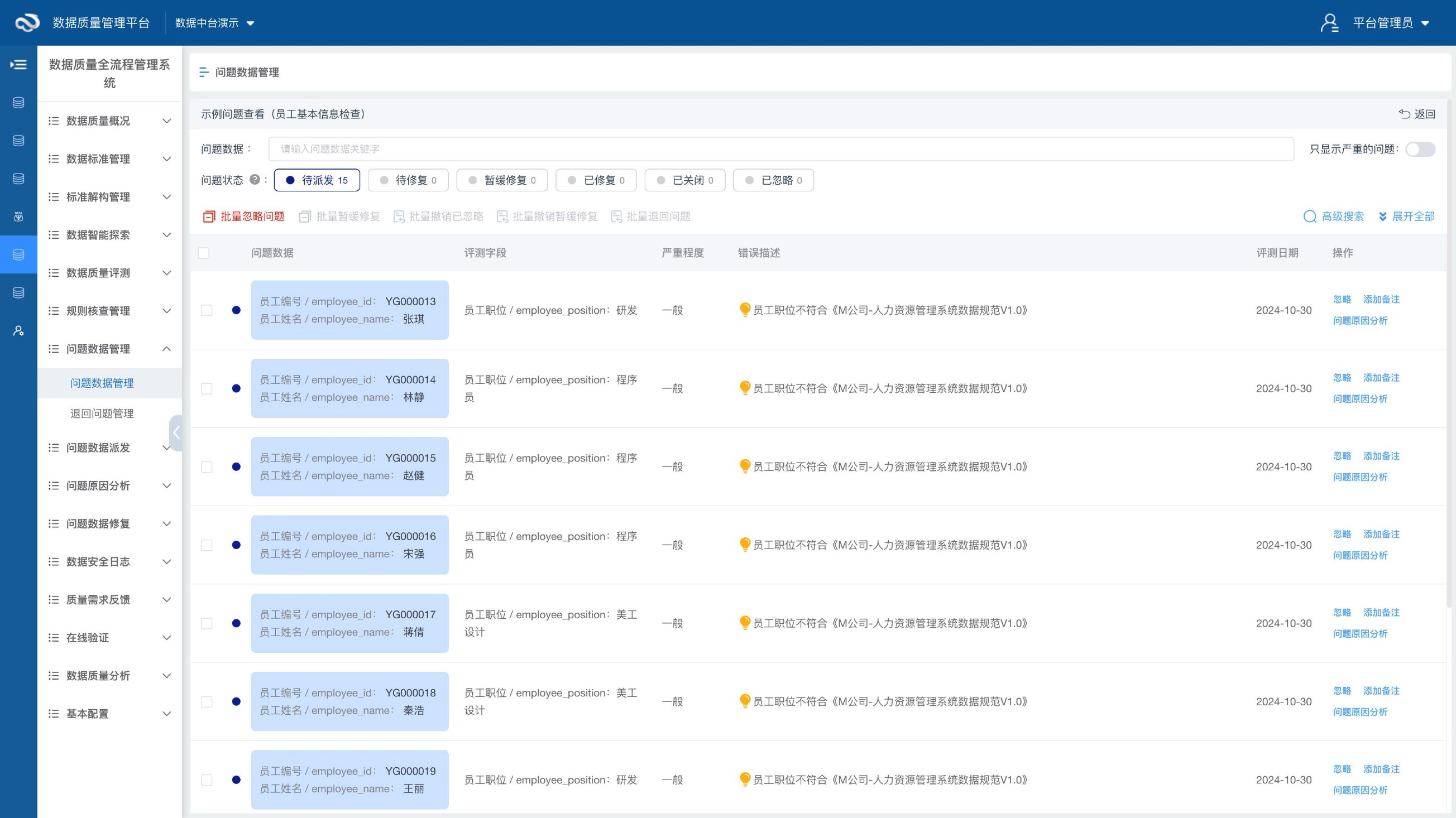
市场部要拉一份客户画像,用来做下周的精准营销。数据中台已经接入了 CRM、ERP 和客服系统,按理说拖几个字段就能出结果。分析同事在 BI 里配好筛选条件,点下查询,出来的结果让人心里一凉: 客户姓名一列,1,200 行是空的 手机号 4,000 多条缺失,800 多条明显是错的(8 位、12 位都有) 性别字段里出现了"M""F""男""女""未知""0"——六种写法,根本没法分组统计 数据接进来了,流转也正常,但问题是——数据本身是脏的,下游谁敢用? 这不是个别现象。很多团队建数据中台,精力全花在"能不能接进来"和"能不能跑通",很少有人关注"接进来的数据对不对"。等到业务部门真要用的时候,才发现数据只能看、不能用。 为什么传统质检方式不够用 常见的做法是两种。 第一种,强校验。 在数据入库前做检查,不合格就拦截。逻辑上没问题,但实际项目里风险很大:一条字段格式的规则配错了,可能把整个管道卡住。凌晨三点的 ETL 任务如果因为一个质量规则报错而中断,运维会被电话叫醒——而且大概率是误报。 第二种,旁路监测。 数据正常同步,质量检查并行运行。发现问题后单独记录到问题库,不阻塞主链路。你可以在白天慢慢修复,不影响任何生产流程。 多数项目里,旁路监测比强校验更实际——这也符合 DAMA 数据管理知识体系中"数据质量管理应优先保障业务连续性"的原则。龙石数据中台的质量管理模块就是这么干的——用"评测模型"管规则,支持 MySQL、Oracle 到 Doris、GaussDB 等一堆数据库,配规则不用写 SQL。作为 DAMA 大中华区实训基地和信通院《数据治理产业图谱 3.0》入选厂商,龙石在这个领域已经有多个项目验证。 上手配置:从零搭建一条质量监控链路 拿最常见的客户基础信息表来跑一遍。customer_info 每天从 CRM 增量同步,要盯三件事:姓名和电话不能空、手机号格式得对、性别代码得在标准字典里。 第一步:创建评测模型 评测模型就是按业务域把规则分组——客户域一个模型、产品域一个、订单域一个。进入「数据质量 → 评测模型管理」,点击新增,填写模型名称"客户信息质量评测",选择评测数据库为治理库(DW),保存。 第二步:添加评测对象 在模型详情页点击新增评测对象,选择 customer_info 表。如果表没有物理主键,需要指定一个逻辑主键来唯一标识每行数据,方便后续问题追溯。 第三步:配置完整性检查 最常见的问题是字段为空,比如客户姓名和电话缺失。新增一条「空值检查」规则: 配置项 填写 规则名称 客户姓名与电话非空检查 检查字段 customer_name,phone 检查方式 每个字段都不能为空 规则权重 高 错误描述 客户姓名或电话存在空值,影响标签生成和营销触达 修复建议 核对 CRM 客户基础信息是否完整录入 第四步:配置准确性检查 字段有值不代表值是对的——手机号是 11 位的吗?年龄在合理范围内吗?性别代码是标准值吗? 格式规范性检查(手机号格式): 规则类型选「格式规范性检查」,检查字段选 phone,EL 表达式写 #phone REGEXP '^1[3-9][0-9]{9}$'。不符合 11 位手机号格式的,自动标记。 值域检查(年龄范围): 规则类型选「值域检查」,检查字段选 age,值域范围设为介于 0 和 120。超出这个区间的数据会被捕获。 引用完整性检查(性别代码标准化): 规则类型选「引用完整性检查」,检查字段选 gender。前提是数据标准模块里已经定义了"性别代码"字典表(M=男/F=女),质检规则直接引用标准定义,不需要重复维护值域。标准改了,规则自动同步。 第五步:创建评测任务 规则配好后,需要建一个评测任务来触发执行。进入「评测任务管理」,选择"客户信息质量评测"模型。首次建议用"手工触发"先跑通验证,确认规则无误后再改为定时策略——比如每天早上 6 点自动跑。 第六步:看结果 任务执行完成后,进入「问题数据查看」。首次扫描 86 万条客户数据,通常能看到类似这样的结果: 问题类型 数量 占比 手机号缺失 4,200 条 0.49% 客户名称缺失 1,200 条 0.14% 手机号格式异常 800 条 0.09% 性别编码不在标准范围 3,500 条 0.41% 合计问题率 1.03% 每条问题都能点开看详情——哪个字段、违了什么规则、当前是啥值、什么时间发现的。修好之后下次跑评测,问题状态自己就关了。 项目里最容易踩的 4 个坑 坑一:规则越多越好。 不是。第一次做数据质量的团队,上来就配几十条规则,觉得覆盖面越广越好。结果每天几千条告警涌进来,没人看得完,也没人处理。两周之后,所有人把告警通知关了。正确做法:从一个核心业务域开始,先配 3-5 条高价值规则,等团队习惯了处理节奏,再逐批加。规则不在多,在有人盯。 坑二:把低价值字段当核心字段。 手机号缺失,值得告警——影响短信触达。备注字段为空,不值得——本来就可空。但很多项目里两者权重设成一样,重要问题淹没在一堆"备注为空"里。区分方法很简单:问自己"这个字段如果错了,下游哪个业务会受影响?"答不上来的,就设低权重或者不配。 坑三:一上来就设定时任务。 评测任务刚建好就设定时,凌晨自动跑——听起来很规范。现实是:第一条规则配错了,半夜产生几千条误报,没人发现,第二天打开系统直接懵了。正确做法:先手工触发跑一次,对着问题清单一条条确认"这是真问题还是误报",确认规则没问题了,再切定时策略。 坑四:错误描述技术部门都看不懂。 见过一个真实案例:规则错误描述写的是"phone 字段不满足 EL 表达式 REGEXP"。业务部门看不懂,技术部门看不出业务影响,这条告警在两个部门之间转了三天没人认领。错误描述应该回答三个问题:什么问题(业务语言)、影响什么(下游场景)、怎么修(可操作的步数)。比如别写"gender 不在值域范围",写"性别字段存在非标准值,影响客户画像分组统计,请在数据标准模块确认标准字典后批量修正"。 真正难的不是发现问题,是把问题推回去 项目做久了会发现一个规律:大部分质量问题并不是系统故障造成的,而是业务过程产生的。客服录入时图省事,手机号随便填。老系统迁移时历史数据没清洗,脏数据原封不动搬过来。ERP 和 CRM 对"客户类型"各有各的编码规则,合到一起全乱了。质量规则能扫描出来的,只是冰山浮在水面上的部分。 更棘手的是:你标记了 4,000 条手机号缺失,谁来补?客服部说"这是历史数据,不是我录的",IT 说"数据已经同步完了,源系统不改我们也没办法"。一圈下来,问题清单躺了一个月没人动。 所以旁路监测真正的价值,不是发现问题——发现很容易,配几条规则就够了。真正的价值是给一个持续推动的抓手:每周把问题清单按来源系统分类,谁产生的谁认领。一次不行两次,两次不行拉上业务负责人一起看数据。质量管理要解决的不是一次性清洗,而是让问题回到业务源头的能力。 常见问题 Q1:旁路监测会影响数据同步性能吗? 一般不会。质量评测是数据同步完之后另外跑的,跟主链路不打架。头一回跑的时候留意下耗时,千万级往上的大表可以用分区评测或者增量评测,别一次扫全表。 Q2:发现问题数据后,系统会自动修复吗? 不会。质量管理的任务是发现问题和推动治理,不是直接改业务数据。问题数据进问题库,标清楚哪条记录、谁负责、怎么修。等业务侧改好了,系统会自动把这条问题关掉。 Q3:什么时候用旁路监测,什么时候用强校验? 不冲突。身份证号、统一社会信用代码这种核心交易数据,强校验合适。客户信息、设备信息、业务标签这些,用旁路监测更稳——别因为几条破数据把整个流程卡了。 Q4:质量规则应该一次性全部配完吗? 别。先盯核心字段,把 80% 的高价值问题干掉,跑顺了再慢慢加。上来就全配,告警多到自己都不想看。 Q5:数据质量问题主要来自哪里? 很多团队第一反应是同步任务出了问题。其实大部分质量问题是业务侧搞出来的:录入的时候图省事、老系统迁移过来的脏数据没洗、不同系统对同一个字段各有各的编码。所以数据质量治理,治的不是数据,是业务过程。 很多人以为数据质量就是上线前集中洗一轮,洗完就干净了。实际上数据质量跟产线质检差不多——每天都有新料进来,质检得一直跑着,不是搞一次就收工。 评测模型和定时任务搭好之后,每周扫一眼问题修复率就行。主要看三样:问题数是在涨还是在降、高权重问题从发现到关闭用了几天、新接的数据源有没有同步建质检规则。 说到底,数据质量不是要把所有问题都干掉——那不可能。是得有一个"一直在查、查出来有人修"的机制。旁路监测做的就是这件事。 截至 2026 年,越来越多的企业数据中台项目从"建设期"进入"运营期",数据质量的持续管理正在成为新的焦点。
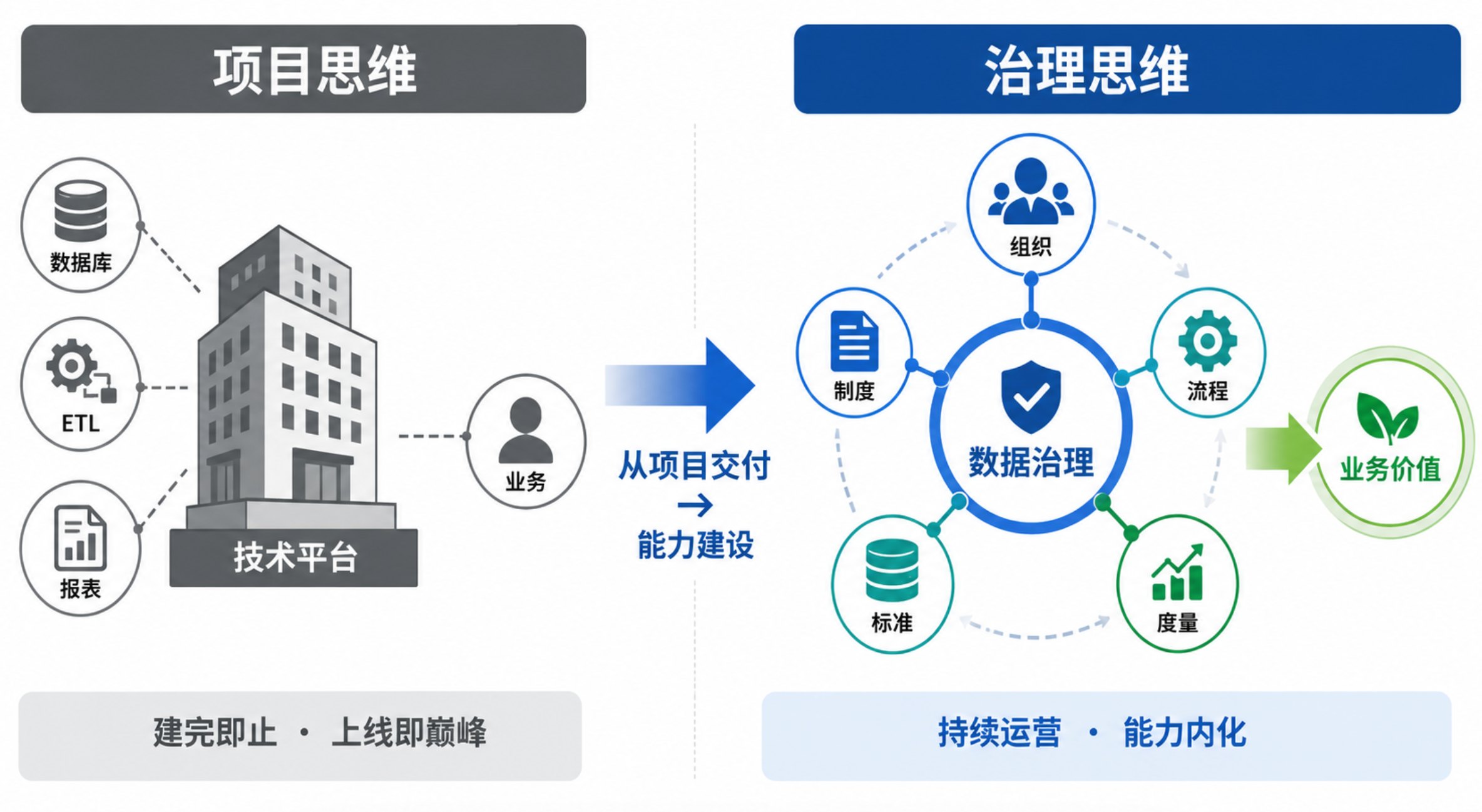
"我们选了一家厂商,演示很漂亮,功能列表拉出来两百多项。但上线半年后,业务部门还是用不起来。" 这是过去一年里,我第三次听到类似的话。说这话的是一家制造企业的 CDO,他们花了大半年选型、三个月部署,最终发现——功能都有,但业务不买账。 选型踩坑,不缺教训。缺的是一套能落地的评估框架。 一、选型前先问自己三个问题 在讨论厂商之前,先想清楚自己的需求: 你建数据中台要解决什么核心问题? 是数据孤岛打通?是数据质量太差?还是缺少统一的数据服务层? 你的团队能力和投入预期是什么样的? 有没有专职的数据治理团队?预算是一次性项目还是按年持续投入? 你的 IT 环境复杂度如何? 涉及多少套业务系统?有没有信创要求?集团多组织还是一个单体企业? 这三个问题不搞清楚,看再多彩页和 Demo 都没用。它们决定了你的选型侧重点——对有些企业来说,数据集成能力是第一优先级;对另一些企业来说,数据治理深度才是决定成败的关键。 DCMM 国家标准(GB/T 36073-2018)将数据管理能力划分为 8 个能力域,其中"数据战略"域明确提出组织应首先明确数据管理的目标和优先级——选型前的自我评估实质上就是在完成这一步。DAMA-DMBOK2 同样将数据管理战略列为顶层指导域,强调先定义目标再匹配工具。 二、维度一:功能——避开"大而全"的陷阱 选型时最容易犯的错,就是看功能列表长短。 功能多≠能落地 很多厂商的演示系统里什么都有:数据集成、数据开发、数据治理、BI 报表、AI 智能问数……列表能拉满三页。但真正上线后你会发现:数据质量规则要手动配置上百条,元数据采集跑一次要半天,主数据合并冲突处理逻辑想改?对不起,那是标准产品不支持。 选型建议:不要问"你们有哪些功能",要问"这个功能在实际项目中怎么落地的"。 一个实用的测试方法:拿一个你真实的业务场景让厂商现场配置。比如"我们想监控 ERP 系统里物料主数据的重复率和空值率,能不能现在演示一下从建规则到出报告的全流程?" 核心能力应该关注什么 数据治理是数据中台区别于传统数据仓库的核心。一个中台选得好不好,最终要看数据是否"好管好用"。以下是几个必须深挖的点: 数据标准管理:能不能定义字段级的业务标准和校验规则?还是只支持简单的元数据描述? 数据质量管理:质量规则是只能技术配置,还是支持业务人员参与?能不能做旁路监测(不影响业务系统运行)?错误数据能不能追溯到源头? 元数据与血缘:元数据采集是全自动的还是需要大量手工录入?血缘分析能不能跨系统追踪? 这些能力直接决定了中台能不能从"工具"变成"底座"。DAMA-DMBOK2 将数据质量、元数据、主数据列为数据管理的核心领域——质量应覆盖"定义、测量、分析和改进"四个环节,元数据应支持全生命周期管理。DCMM 同样要求质量问题追溯到源头。 另外,数据资产目录虽然属于"用"的环节,但在选型时也值得一并考察:资源目录能不能让业务人员自助找数、申请用数?还是只是一个 IT 人员看的列表?这直接关系到中台上线后业务部门能不能真正用起来。 以实际项目验证过的方法论为参照——龙石数据中台基于"理采存管用"框架,把数据治理能力拆解为标准管理、质量监测、元数据与血缘、资产目录等可独立使用的模块。这种模块化设计让企业可以按需选择,不用一开始就为用不到的功能买单。 怎么测:选型时别光听讲 PPT,让厂商在你的实际业务场景里配一个质量规则全流程——从建规则、跑监测、出报告到问题数据追溯——能不能半小时内搞定?比如可以先上数据质量旁路监测,看到效果再逐步扩展。 一个典型的教训:某中型汽车零部件企业(年营收约 15 亿)被某厂商的"一站式 AI 数据平台"吸引,合同金额超过 200 万。部署后三个月内,数据质量模块仅配置了不到 20% 的规则——因为大量规则需要手工梳理业务逻辑,而团队根本没有专职数据治理人员。最终该企业转向模块化方案:先上数据集成+质量旁路监测,两月内数据问题率从 18% 降到 5% 以下,再逐步扩展。这个案例说明一个朴素道理:功能广度在团队能力不足时不是优势,而是负债。 三、维度二:架构——兼容集成,避免技术锁定 和现有系统的关系 选型不只是选一个产品,是选一个未来几年的技术伙伴。核心问题是:这个中台能不能和你们已有的系统和平共处? 数据库兼容:支持哪些数据库?信创环境适配了吗?(达梦、人大金仓、海量数据等) 集成方式:多源异构数据接入是通过标准接口还是私有协议?能不能对接已有的 ETL 工具(如 DataX、Kettle)? 部署模式:支持私有化部署吗?支持混合云吗? 架构的扩展性 今天是三个业务系统接入,明年可能是十个。今天是单体企业用一个实例,后年可能是集团管控需要分权分域。 一个好的选型判断标准:工作空间模型。龙石数据中台的"一集团一中台、一公司一空间"架构,就是一种典型的可分可合的架构设计——总部统一标准和安全管控,子公司或部门在独立工作空间内自治,既保证了一致性又兼顾了灵活性。 信通院《数据治理产业图谱 3.0》指出,头部厂商正从"单一产品"向"平台化、组件化、可组装"方向演进。国家数据局"数据要素×"三年行动计划明确要求推动数据跨部门、跨层级、跨区域流通——这意味着中台架构必须具备分权分域和跨组织协同能力。 一个选型中的实战经验:某省级城投集团(下辖 12 家子公司,业务涵盖地产、水务、交通)在选型时,核心痛点是"总部要统一管,但子公司各自有自己的业务节奏"。他们确定了一个硬性评估标准:验证厂商的工作空间模型能否在总部统一标准的同时,允许子公司独立管理自己的数据资产目录和权限。经过 POC,他们淘汰了三家只能做单体部署的厂商。这个选择让后续推广从"总部推不动"变成了"子公司主动接入"。 四、维度三:服务——不只是一次性交付 数据中台不是买个软件装上就完了。它涉及组织变革、流程重构、团队能力建设,是一个持续运营的过程。 交付≠完成 很多厂商签完合同、部署上线后就转为被动支持模式——有问题你找我,没问题我就等着。但数据中台的真正价值是在持续运营中释放的。 要问的问题: 部署完成后,厂商会参与运营吗?还是只是远程支持? 有没有定期的巡检和健康度评估? 如果业务需求变了,能不能快速调整配置而不是等版本升级? 让团队真正用起来 中台最终是要交给你自己的团队来运营的。如果厂商的交付方式是"我们帮你把系统建好,然后你自己摸索",那大概率用不了多久就会回到原样。 一个务实的判断标准:厂商有没有成熟的培训+陪跑机制? 龙石数据的"产品+培训+陪跑"模式是一个参考标杆——理论培训(DCMM/DAMA/方法论)让团队知道"为什么做";实施培训让团队知道"怎么做";实战陪跑让团队在真实项目中"动手做"。这种三级培训+实战体系确保企业在项目完成后,具备独立的数据治理能力,而不是永久依赖厂商驻场。 新疆某热力公司的案例就很有代表性。 这家企业承担着全市集中供热业务,长期以来,SCADA、收费、GIS 等系统各自独立运行,数据标准不统一,地址信息缺乏规范,基层人员经常需要重复录入同样的数据。 在建设数据中台的过程中,龙石团队并没有把工作停留在平台交付层面,而是同步推进数据管理能力建设。围绕理论、实施、实战三个阶段,通过系统化培训帮助信息部门建立对 DCMM、DAMA 以及"理采存管用"方法论的整体认知;结合实际业务场景,指导团队配置数据标准、数据质量规则和管理流程;并以真实业务问题为切入点,带领客户完整走通数据治理实践。 项目建设完成后,龙石团队继续通过陪跑服务,指导客户团队独立开展数据治理工作,逐步将项目成果转化为组织能力。 如今,热力公司已经组建起自己的数据管理团队,并将相关机制持续运营至今。回顾这段经历,客户曾这样总结: "以前这些系统更像是各自运转的孤岛,现在不仅连起来了,我们也知道该怎么管理、怎么维护、怎么持续优化了。" 这样的变化,不只是多了一个数据平台,更重要的是企业逐步建立起了自主开展数据管理和持续运营的能力。 DCMM 在多个能力域中强调,数据管理能力的提升需要组织文化、人员技能和流程机制的综合配套——仅靠工具无法实现成熟度的跃升。DAMA-DMBOK2 同样指出,数据管理的成功依赖于"人员、流程和技术的协同",技术只是三个支柱之一。 五、选型清单:一张表帮你理清思路 评估维度 核心问题 怎么看 功能深度 数据治理能力是否扎实?(标准/质量/元数据/资产目录) 用真实业务场景验证,不看功能列表 架构兼容 能不能和你现有系统无缝对接?信创适配? 查兼容性认证、看是否支持标准接口 扩展性 能不能从部门级扩展到集团级? 看工作空间模型和多租户支持 服务模式 厂商是卖完就走还是持续陪跑? 看有没有培训+陪跑体系 案例验证 同行业有没有真实落地案例? 不问"做过多少",问"能不能讲一个真实过程" 六、常见问题 Q1:功能多少算够? 不是越多越好。一个数据中台的核心价值在于数据治理深度,而不是功能广度。如果你主要用数据集成和 BI 报表,那很多治理类模块可以先不上。但如果你要建的是长期数据底座,标准、质量、主数据、元数据这四个模块一个都不能少——这也是 DCMM 重点评估的核心能力域。 Q2:开源的能用吗? 看团队能力。如果你们有 5 人以上的专职数据工程团队、愿意花半年以上做二次开发和集成,开源方案可以探索。但如果团队以业务人员为主、希望尽快看到效果,建议选商用的——省下的不是 license 费,是时间成本和试错成本。 Q3:中小企业预算有限怎么选? 不要看总价,看首年投入和见效速度。选一个模块化的产品,先上最紧迫的模块(比如数据集成 + 质量),跑通之后再逐步扩展。龙石数据中台的特点是所有功能模块可独立部署、按需装配,单台 16C32G 就能起步,部署周期约一周。这种轻量化启动模式适合不想一次性大投入的企业。 Q4:信创环境怎么选? 必须确认厂商有没有完整的信创适配认证。龙石数据中台已完成麒麟、统信、达梦、人大金仓、OceanBase、华为等主流信创产品的兼容性认证。不过认证列表长不代表适配好——最好在 POC 阶段就在你的实际信创环境上跑一跑。 参考来源 [1] DAMA International,《DAMA-DMBOK2: Data Management Body of Knowledge》 [2] GB/T 36073-2018《数据管理能力成熟度评估模型(DCMM)》 [3] 中国信通院,《数据治理产业图谱 3.0》(2023年12月) [4] 国家数据局等,《"数据要素×"三年行动计划(2024—2026年)》 [5] Gartner,《Market Guide for Data Management Solutions》 [6] 国务院,《"十四五"数字经济发展规划》《数字中国建设整体布局规划》

龙石数据质量管理平台·社区版部署教程。




