

一、场景介绍 销售总监老李周一早会前打开ERP系统,想快速查一组数据:"各区域本月销售额完成率是多少?和上个月环比变化怎么样?再拉出近六个月的月度趋势看看。"他打开BI工具点了半天,发现需要的维度分散在三个不同的报表里,做交叉分析得先导出Excel再手动合并。他给IT部门发了条消息,很快收到回复:需求已收到,排期大约三天后给结果。下周一的事情,周一才能拿到数据,老李看着手机叹了口气。 这不是老李一个人的问题。在大多数企业的实际工作场景中,业务人员想查询分析数据的路径是固定的:提需求、等排期、IT写SQL(Structured Query Language,结构化查询语言)、返回结果、发现不对、再沟通、再等。一个简单的问题来回几天是常态,复杂一点的交叉分析等一两周也不罕见。数据明明就存储在系统里,但业务人员就是拿不到、用不起来——技术门槛把数据的使用权牢牢锁在了IT部门手中。 这个问题背后更深层的矛盾在于:企业花大量资源建设数据平台、打通数据孤岛、汇聚数据资产,最终的目的是让数据服务于业务决策。但如果业务人员每一次查数据都必须经过IT翻译,数据中台建设得再好也只是IT团队的后台工具,距离真正赋能业务还差最后也是最关键的一步——让不懂SQL的人也能直接用数据。 二、前置条件:AI读懂数据的四项基础 AI智能用数(即通过自然语言对话的方式查询和分析企业数据)不是在空白系统上装一个聊天界面就能跑通的。一个用户输入"本月华东区销售额排名",AI需要完成一系列动作:理解用户意图、定位相关数据表、确认字段含义、生成查询语句、返回结果并解读——这个链条的每一步都依赖于数据治理底座的支撑。说得更直白一点:AI不是魔法,它需要知道企业有哪些数据、数据是什么意思、能不能信得过。以下四项基础能力,是AI用数能否跑通的前提。 2.1 数据资产目录——让AI知道"有哪些数据" 数据资产目录(即对企业全部数据资源的系统性编目和索引)在AI用数场景下的角色发生了根本变化。过去,资产目录更多是一份给管理层汇报的"全景图"——展示企业有多少张表、多少项指标、覆盖了哪些业务域。但在AI用数场景中,资产目录变成了AI的导航地图。当用户用自然语言问"本月华东区销售额",AI需要在资产目录中完成定位:销售额数据存在哪张表里、华东区对应哪些字段、这些表和字段之间是什么关系。目录全不全、目录里的元数据描述准不准,直接决定了AI能不能找到正确的数据。如果核心业务表根本没有纳入目录,AI的表现就是"未找到相关数据"——这不是模型能力不行,而是模型根本不知道数据在哪。正如数据目录领域的研究文献所指出的,数据目录是数据资产化的重要入口(arXiv 2402.05211),在AI驱动用数的场景中,这一入口的作用被进一步放大。 2.2 元数据管理——让AI理解"数据是什么意思" 元数据(Metadata)即"关于数据的数据",通俗地说就是数据的"使用说明书":这个字段叫什么名字、从哪个业务系统来、在业务中代表什么含义、数据类型和取值范围是什么。举个例子,一个字段名叫customer_name,如果不标注元数据,AI只知道这个字段存的是字符串。但如果标注了元数据——"此字段为ERP客户管理模块中的签约客户全称,与CRM系统中的company_name字段对应同一个业务实体"——AI就能在用户问"客户签约情况"时准确关联到这个字段。当同一个概念在不同系统中的叫法不同(比如ERP系统叫"客户名称",CRM系统叫"签约主体",财务系统叫"往来单位"),元数据层负责统一这些语义差异,为AI提供一个一致的"翻译层"。没有这个翻译层,AI永远读不懂企业数据的真实含义。 2.3 语义模型与数据标准——让AI跨系统理解业务 数据标准统一了核心业务实体的编码规则和口径定义。但更关键的是语义层面——不同业务系统对同一个概念的"口径"可能完全不同。以"销售额"为例:ERP系统按含税签约金额计算,财务系统按不含税实收金额计算,CRM系统按销售机会预估金额计算。三个系统明明都在说"销售额",数字却对不上。如果这些口径差异没有在语义模型层面统一对齐,AI就只能忠实地汇总它能找到的数据——而它找到的数据本身口径就不一致。这就是为什么制造企业在用大模型查"华东区销售额"时,模型返回3200万、财务系统显示2800万的典型案例:不是模型算错了,是模型取得的数据口径源头就不统一。语义模型的价值就在于为AI提供一个统一的业务语义定义层,让"销售额"在企业内部有唯一且明确的含义。 2.4 数据质量——让AI输出的结果可信 数据质量(Data Quality)即数据的准确性、完整性、一致性和及时性,在AI用数场景中是最先暴露的问题,也最容易被人误判为"模型不行"。大语言模型的一个特征是对输入数据的"信任"——它不会主动质疑数据来源的可靠性,脏数据(缺失值、错误记录、重复数据)会被模型当作事实全盘接受,然后生成流畅但可能完全错误的分析结果。根据Data-Centric AI(以数据为中心的人工智能)的研究观点,AI系统的效果上限由数据质量决定,而非单纯由模型能力决定。在传统数据分析场景中,分析师面对一份脏数据至少还能凭经验识别异常值;但在AI自动查询分析的链路中,脏数据绕过人工审核直接进入结果,修复成本反而更高。龙石数据中台采用旁路监测模式应对这一挑战:数据正常入库不阻塞业务流转,质检规则在旁路并行扫描,发现问题后自动标记、告警并生成质量工单,在不影响业务时效的前提下持续提升数据质量的可见性和可管理性。 三、配置实战:让AI听懂销售问题 以下配置流程基于龙石AI用数智能体的管理端功能,覆盖从创建场景到发布上线的完整路径。每一步均可独立执行,读者可按顺序逐步操作。文中涉及的术语在首次出现时标注了中文解释。 3.1 步骤1:创建用数场景 目的:为"问数据"智能体定义工作上下文——关联哪个数据源、使用哪套指标体系、遵循什么样的分析规则。一个场景就是一个对话沙盒,用户进入不同场景就进入不同的数据工作区。 操作:进入智能体管理→数据知识管理→创建场景。填写三项核心信息:场景名称(如"销售数据分析"),场景描述(如"覆盖订单、回款、退货、客户维度,支持区域/产品/人效多维度分析"),关联业务领域。场景创建完成后,系统为该场景开辟独立的数据知识空间。 3.2 步骤2:接入元数据 目的:让AI知道该场景下可查询哪些数据表、每张表有哪些字段、每个字段的业务含义是什么。 操作:在数据知识管理中配置元数据源,系统自动采集关联数据库中的表结构、字段名称和字段类型。采集完成后,运营人员需为每个字段逐项补充业务含义说明——不只是写"字符串类型、长度50",更要写清楚"这个字段在业务中代表什么、从哪个系统来、计算口径是什么"。同时设置字段启用状态:核心业务字段设为"可查询",敏感字段(如客户联系方式、身份证号等)设为"不可查询",实现字段级别的数据权限控制。 3.3 步骤3:提示词模板与召回测试 目的:引导大语言模型按照企业规范生成SQL和回答。提示词(Prompt)即发送给大模型的结构化指令文本,定义了AI的角色、行为边界和输出约束。 操作:平台内置了默认的提示词模板和召回测试机制,一般情况下直接使用即可。在提示词管理中可以查看和微调,但新手上路不必从头编写——默认模板已覆盖角色设定和基本的SQL生成规范。配置完成后,在测试界面输入几个真实的业务问题(如"本月各区域销售额排名"),观察AI返回的结果是否符合预期。如果结果偏差较大,再针对性地调整提示词或重新检查元数据标注,不必一开始就追求"完美"。测试覆盖单表查询、多表关联、聚合统计等几个典型场景即可。 3.4 步骤4:预设高频问题 目的:对企业内最高频的业务查询问题提前配置标准查询语句,确保这部分问题的回答准确率达到100%。 操作:收集业务部门最常问的销售数据问题,按分类录入预设问题库。常见分类包括区域销售分析(如"本月各区域销售额排名""各区域完成率对比")、产品分析(如"各产品线销量排行""产品毛利率分布")、人效看板(如"各团队人均产出""销售个人业绩排名")、趋势分析(如"近六个月月度销售趋势""同比环比变化")。每个预设问题配置对应的标准查询语句和预期回答格式。用户在前端使用时可点击预设问题直接查询,无需手动输入。 3.5 步骤5:发布上线 目的:将配置好的智能体和场景从管理端发布到应用端,面向业务用户开放使用。 操作:配置智能体的前端展示信息——名称(如"销售数据助手")、图标、描述和开场白(如"请输入您想了解的销售数据问题")。配置场景切换选项,使用户可以在不同业务场景之间灵活切换。确认用户权限分配:按角色设置数据库、表、字段级别的访问范围(如销售一部只能看到对应区域的客户和订单数据,销售总监可以看到全部数据)。设置用户配额(如每人每日200次查询),控制大模型调用成本。所有配置确认无误后,点击发布。 四、配置模板(核心模块) 以下配置模板汇总了步骤3.1至3.5中涉及的关键配置项,供读者在实际操作时参照使用。每个配置项均标注了推荐填写内容和配置说明。 配置项 填写内容 说明 场景名称 销售数据分析 按业务域命名,用户在前端切换场景时可见 场景描述 覆盖订单、回款、退货、客户维度,支持区域/产品/人效多维分析 描述场景覆盖的数据范围和可分析的维度,帮助用户理解该场景的适用边界 关联数据源 sales_db(含订单表、回款表、客户表、区域表) 选择该场景下可查询的数据库和数据表,未关联的数据源对AI不可见 元数据接入 自动采集表结构,逐字段补充业务含义说明 每字段须标注业务含义,仅靠字段名AI无法正确理解数据含义 字段权限 客户名称、签约金额→开启;客户联系方式→关闭 敏感字段设为不可查询,从源头阻断数据泄露风险 提示词模板 使用平台默认 平台内置了角色设定和SQL生成规范,新手上路直接用默认即可 预设问题 "本月各区域销售额排名""近6月月度销售趋势""客户回款率分析""各产品线销量排行" 高频问题预置标准查询,该类问题准确率可做到100% 用户权限 销售部门全员→查询权限;销售总监→全部字段访问权限 按角色分配数据访问范围,遵循最小化原则 用户配额 每人每日200次查询 控制大模型Token消耗成本,可根据岗位调整 智能体外观 名称"销售数据助手",开场白"请输入您想了解的销售数据问题,如:本月各区域销售额排名" 增强用户辨识度,开场白引导用户发起查询 五、验证结果:自然语言查询实战 配置完成并发布上线后,业务人员打开"销售数据助手"智能体,即可以自然语言对话的方式查询和分析销售数据。以下展示三个典型查询示例,呈现AI用数在实际业务场景中的效果。 查询示例一:单维度排名统计。 用户输入"本月各区域销售额排名",AI经过意图识别→数据表定位→SQL生成→结果返回的完整链路,输出华东、华南、华北、西南等各区域的销售额排名表格,同时自动生成一张柱状图直观呈现各区域对比,并配以文字解读:"本月销售额最高为华东区(1,280万元),其次为华南区(965万元),西南区环比增幅最大(+12.3%)。整体完成率为82%,与上月同期相比增长5.2个百分点。" 查询示例二:多维度趋势分析。 用户输入"近六个月月度销售额趋势,按产品线分类",AI返回一张趋势折线图,六条产品线(A/B/C/D/E/F)各自呈现近六个月的月度销售额变化曲线,下方附带明细数据表。文字解读自动提炼关键特征:"六条产品线中,B产品线和D产品线呈现持续上升趋势,B产品线近六月累计增长34%;C产品线在第四个月出现明显下滑(环比-18%),建议关注原因。" 查询示例三:交叉维度分析。 用户输入"分析一下上季度客户回款率,按区域和大客户/中小客户分类",AI返回分组柱状图——横轴为区域,每组两根柱子分别代表大客户回款率和中小客户回款率。文字解读标注关键发现:"整体回款率82%,其中大客户回款率(91%)显著高于中小客户(74%)。华北区大客户回款率最低(79%),建议重点关注该区域大客户的回款跟进。" 上述查询结果的共同特征是:数据表格提供精确数值,可视化图表提供直观对比,文字解读提炼关键洞察——用户在不需要理解任何SQL语法或数据结构的前提下,通过自然语言对话完成了过去需要IT协助数日才能完成的分析工作。龙石AI用数智能体在返回数据结果的同时,自动生成自然语言描述对数据的关键特征进行提炼与解释,降低了业务人员理解数据结果的门槛。 六、避坑指南 AI用数在实际落地过程中,有三个高频踩坑点。以下逐一拆解现象、根因和解法。 坑一:元数据不全,AI"读不懂"数据。 现象:智能体配置完成、成功发布上线后,用户输入"本月销售额",AI回复"未找到相关数据",或者查询了错误的表返回了毫不相干的结果。根因:元数据接入不完整——数据表确实接入了,但字段的业务含义没有标注。AI只知道字段名叫sales_amount、类型是decimal(18,2),但它不知道这个字段代表的是"含税签约金额"还是"不含税实收金额",不知道它对应的是哪个统计口径,甚至不确定它在不同表中是不是同一个含义。在这种情况下,AI要么拒绝回答,要么给出一个看似合理但实际错误的答案。解法:元数据接入环节必须逐字段标注业务含义,不能只停留在字段类型和长度这些技术元数据层面。要把每个字段在业务中的含义、来源系统、计算口径写清楚,这一步做得越扎实,后续AI用数越可靠。这不是一次性工作,后续新增的数据表和数据字段也需要同步维护更新。 坑二:数据口径不统一,AI输出"看着对、实际错"。 现象:销售总监用AI查"本月销售额"得到3200万,觉得数据还不错。但财务部门出具的月度经营报告显示销售额2800万,差距400万。AI给出的数据"看着对"——格式规范、数字精确、图表美观——但"实际错"——和权威数据源对不上。根因:同一个"销售额"指标在不同的业务系统中口径不一致。ERP系统按含税签约金额计算,财务系统按不含税实收金额计算,CRM系统按销售机会预估金额计算。AI只是在忠实地汇总它能找到的数据,但这些数据源自不同口径,汇总本身就没有意义。解法:在数据标准层面统一核心指标的口径定义,明确"销售额"在企业内的唯一计算规则。如果多个口径在业务上都有存在的必要性,则必须用不同的指标名称加以区分(如"含税签约销售额""不含税实收销售额"),确保AI引用的每个指标在语义上单一、明确、无歧义。语义模型的建设是这道门槛的关键——它决定了AI是"理解业务"还是"堆砌数据"。 坑三:只配工具不建运营机制,"上线即终点"。 现象:智能体上线首月使用活跃,业务人员觉得新鲜纷纷试用。三个月后再看数据,日活跃用户大幅下滑,少数仍在使用的用户偶尔提问发现回答不对,不知道找谁反馈,默默放弃。智能体从"新工具"变成了"僵尸系统"。根因:AI用数不是一次性配置项目,而是一个需要持续运营的能力平台。没有用户反馈收集机制、没有问答质量监控、没有人持续优化提示词和元数据标注——智能体上线后不会自己变聪明,它只能停留在配置时的初始水平。解法:建立"用户反馈→工单处理→知识库更新→模型优化"的运营闭环。具体而言:用户对智能体回答结果可点赞或点踩,点踩记录自动生成反馈工单推送至数据治理团队;运营人员复核处理后,将优化结果更新至提示词模板或元数据标注;定期分析高频失败问题,系统性改进薄弱环节。运营闭环是AI用数从"能用"走向"好用"的关键机制。 七、小反转:真正决定效果的不是配置 看到这里,你可能会认为AI用数就是按照上面的六个步骤逐一配置、反复调优。配置本身确实不复杂——创建场景、接入元数据、编写提示词模板,有经验的运营人员几天之内就能完成部署。但真正决定AI用数效果的,不是提示词写得有多精妙、模型参数调得有多细致,而是配置背后数据治理的成熟度。 资产目录不完整,AI就找不到数据——这和提示词质量无关。元数据没有标注业务含义,AI就读不懂数据——这和模型能力无关。数据标准不统一,AI输出的结果就是"看着对、实际错"——这和查询逻辑无关。数据质量无人管理,AI给出的分析结论就不可信——这和算法精度无关。AI用数的上限,不由大模型的能力决定,由企业数据治理的成熟度决定。龙石AI用数智能体的一个核心设计前提是:数据治理到位后AI用数效果才好——治理的底子,不能省。 八、案例验证:一个已经跑通的样本 江苏某国企数科运营着一个数据要素流通平台,汇聚了大量公共数据与市场化数据资源。平台上线后,数据有了、功能全了,但面临一个典型的"最后一公里"问题:用户找数靠关键词硬搜,用数靠自己摸索,运营团队想收集用户需求却缺乏系统化手段——三大断层(找数难、用数难、运营难)导致平台价值没有充分释放。 龙石数据为平台部署了AI用数智能体,构建了"感知-匹配-演进"三位一体的智能入口。在技术层面,基于语义检索和模糊检索双模引擎理解用户的自然语言查询意图,自动引导用户从查找数据到申请使用的全流程。运营层面是这次部署中更值得关注的亮点——智能体持续分析用户的搜索失败记录和浏览行为中断点,自动识别潜在的数据需求并生成需求洞察报告,这些洞察直接驱动了数据产品的上架、优化和迭代,形成了"需求驱动供给"的良性循环。 上线后的效果从两个维度得到验证。效率维度:平台基础咨询工单量显著下降,用户从提出问题到获取数据的耗时大幅缩短。价值维度:系统持续挖掘出多个真实用户需求,其中部分高价值需求已进入产品开发流程,数据产品的复用率明显提升。运营团队的反馈很直白:"以前推数据产品像蒙着眼睛打靶,智能体给了我们一杆瞄准镜。"这个案例的启示在于:AI用数的价值不仅是降低查询门槛,更在于打通了从"用户要什么"到"平台供给什么"的需求驱动链路。 九、常见问题(FAQ) Q1:AI用数的准确率到底能达到多少?是不是和通用ChatGPT差不多? AI用数的准确率取决于两个变量:数据治理的质量和问题本身的复杂度。简单场景(如按条件查询、单表统计、排名排序等),准确率可以做到接近100%;复杂场景(跨多表关联推理、涉及模糊业务概念的查询)会有一定误差。关键区别在于:企业AI用数不是开放域问答,而是在企业自身数据资产范围内做查询和分析——治理到位的元数据和数据标准,能大幅缩小AI的理解偏差。通用的ChatGPT不了解你企业的数据结构和业务口径,而企业AI用数的上下文由你自己的数据知识库定义,两套系统的性质不同,不宜直接类比。 Q2:我们公司用的是Oracle/SQL Server,不是MySQL,能用吗? 可以。AI用数智能体适配MySQL、达梦、Oracle、SQL Server等多类主流数据源,底层数据库类型不影响自然语言查询能力。在提示词模板的SQL约束规范中,将语法类型设置为与你实际使用的数据库对应的方言即可。如果企业同时使用多种数据库,可为不同场景分别配置对应的SQL语法约束。 Q3:数据不出域怎么保证?如果是私有化部署,大模型放在哪? 龙石AI用数智能体支持客户自备本地大模型(如DeepSeek或千问3),所有数据查询和推理分析在本地服务器上完成,企业数据不出域、不上云。大模型部署在客户自有服务器上,数据流转的全链路控制在企业内部网络范围内,符合数据安全合规要求。 Q4:我们的数据资产目录还没建全,能不能先用起来? 不需要等"完美"再启动。建议的策略是:先选定一个业务价值最高的用数场景(比如销售数据查询),把这个场景相关的几张核心表的元数据做扎实,配置好提示词和预设问题,先跑通再横向扩展。反过来看,AI用数的需求本身也会驱动数据治理的加速——当你发现某张表查询结果不可信时,自然会推动它的数据标准和质量管理。治理和用数可以并行推进、相互促进,而不是先做完一个再做另一个。 Q5:业务人员问的问题太口语化怎么办?比如"最近卖得怎么样"这种模糊问题。 这正是混合检索引擎发挥作用的地方。AI用数智能体的语义检索和模糊检索双模引擎能够理解"卖得怎么样"背后用户可能想查询的是销售额、增长趋势、完成率等指标。同时,预设问题功能把最高频的业务问题提前配置为标准查询,确保模糊问法也能命中准确结果。配合问题推荐功能——系统根据当前提问自动推送相关的待探索问题——引导用户逐步聚焦分析方向,让模糊的查询意图在交互过程中逐步明确。 Q6:多个部门使用同一个场景,怎么控制数据权限? 通过智能体权限管理,可以按角色进行数据库、表、字段三个级别的精细化权限控制。例如,销售一部只能看到华东区的客户和订单数据,销售二部只能看到华南区的数据,销售总监可以看到全部区域的数据。权限分配遵循最小化原则——每个用户只能查询被授权的数据范围,从机制层面杜绝越权访问。 Q7:AI给的结果万一错了,业务人员怎么判断? 这恰恰是数据解读和元数据标注的价值所在。AI返回结果时附带三层辅助判断信息:第一,文字解读——提炼数据的关键特征,便于用户快速理解结果含义和发现异常;第二,数据来源说明——标注数据取自哪个系统、哪个表,让用户知道结果的数据基础;第三,工单反馈机制——用户对结果不满意可一键提交反馈工单,运营人员复核处理后反馈修正结果。这三层机制共同构成了"可信用数"的保障体系,让用户在使用AI结果时有据可查、有错可纠。 十、方法论收尾 AI智能用数本质上是"理、采、存、管、用"五阶方法论中"用"这一环的自然延伸。它不是一个独立的新系统或新项目,而是数据治理水到渠成之后的能力升级。 值得强调的是:不是"等治理做完美了再上AI用数",而是AI用数的需求反过来会推动"理"和"管"两个环节的加速。当业务人员用自然语言问数据问不准的时候,自然会暴露出数据标准不一致、元数据标注缺失、数据质量有问题——这些问题的根因和解决路径,都在"理采存管用"的前四环里。AI用数就像一面镜子,把治理层面的问题照得一清二楚。 对于已经按照"理采存管用"方法论推进数据治理的企业来说,AI用数不是另起炉灶的新投入,而是已有建设成果的价值释放。工具到位了、数据治理了、业务人员能自己查数据了——这才是数据中台建设的最终目的:让数据不仅是技术团队管理的资产,更是业务人员能用起来的工具。 参考来源: Data-Centric AI, Andrew Ng et al. DCMM 2.0 数据管理能力成熟度模型(GB/T 36073-2025) DAMA-DMBOK 2.0 数据管理知识体系指南, DAMA International ArXiv 2402.05211, "Data Catalogs as a Gateway to Data Assetization"
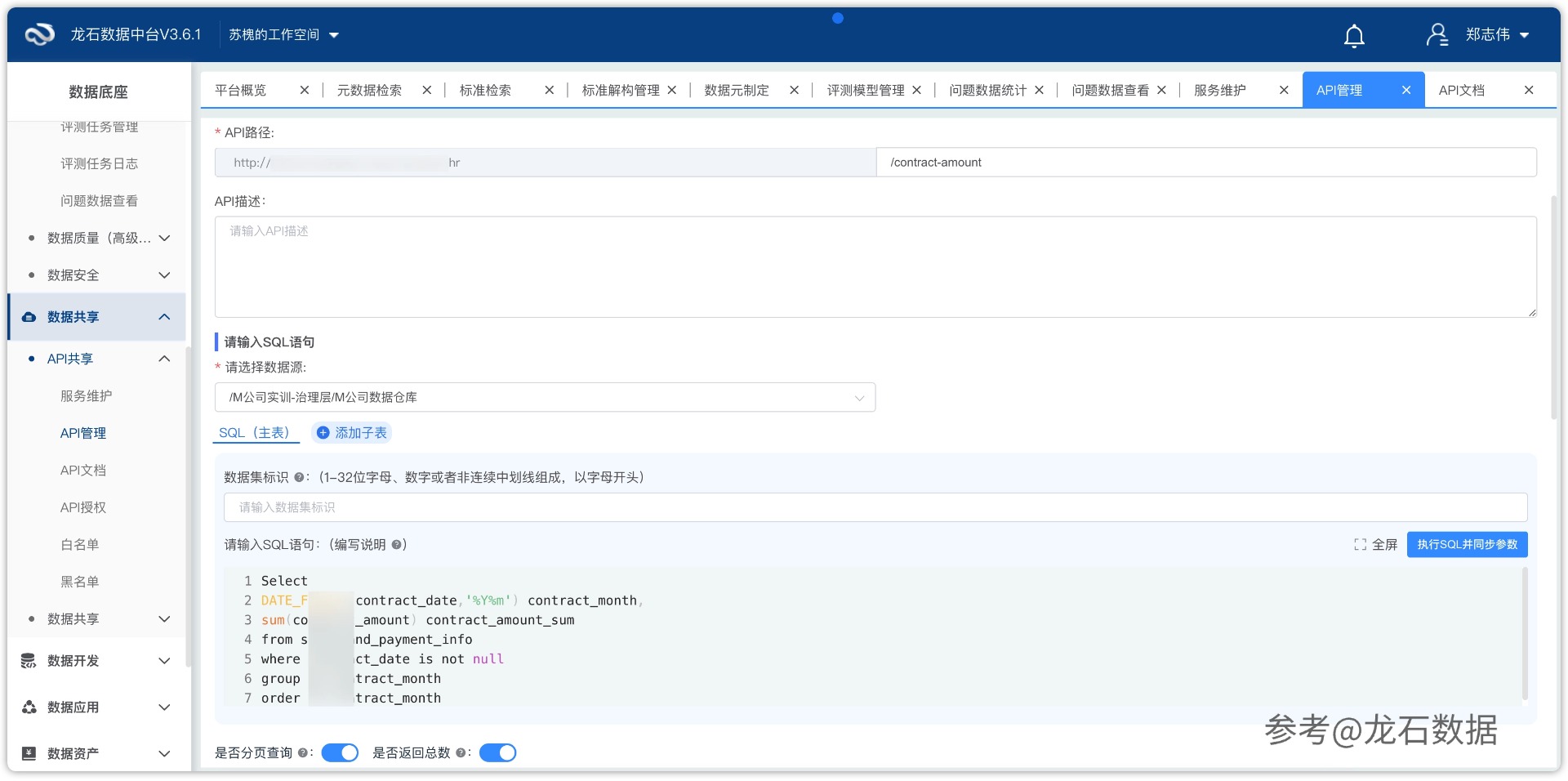
第一章 场景——数据就在那儿,但用不了 周二上午十点,运营部门的小王在企业微信上发来一条消息:"张工,我们这周要做客户复购率分析,需要客户订单表、商品信息表和会员积分表,字段清单我发你。"附件里列了三十多个字段,横跨CRM(客户关系管理)系统、ERP(企业资源计划)系统和营销活动平台三个独立数据库。张工看了一眼消息,心里默默列了一下工作清单:先确认这三个系统的数据库只读账号还在不在、分别登录查询表结构和字段名是否匹配、找开发排期写一个RESTful API(表述性状态传递接口)服务把数据整合出来、配一套鉴权机制防止未授权访问、再写一份接口文档给小王对接——这套流程走下来,保守估计两天。而小王那边,复购率分析的报告周五就要交。 这个场景在多数企业的IT部门几乎每天都在上演。数据治理的前几步——梳理数据资源、采集汇聚、建仓存储、质量管控——都在推进,但到了最后"用出去"这一步,往往卡在了一个手工开发的瓶颈上。让业务部门直接连数据库是不现实的(安全风险和权限管控都不可控),把数据导出成Excel文件传递又丧失了实时性和可追溯性,而走正规的API开发流程,开发和测试周期又太长。API(应用程序编程接口,Application Programming Interface)是当下最灵活的跨系统数据共享方式,因为调用方不需要知道底层数据库的结构,只需要按约定好的请求格式发送一个HTTP请求就能获取数据,数据库账号密码完全不暴露。但手工开发API意味着每个数据共享需求都要经历"需求评审→代码开发→安全审计→接口文档→联调测试"的完整软件工程流程,效率低、安全控制靠人工保障容易遗漏。 龙石数据中台的数据共享模块在设计上正是针对这一瓶颈。它对应"理、采、存、管、用"五阶方法论中"用(促共享重应用)"阶段的核心能力——选择数据源后通过可视化界面编写SQL(结构化查询语言,Structured Query Language,一种用于管理和查询关系型数据库的标准编程语言)生成API,再通过鉴权(身份验证,验证调用者是否具备合法的访问凭证)、IP白名单(来源限制,仅允许指定IP地址的请求通过)、流量控制(调用量限制,约束同一时间的并发数和单日的总调用次数)三道防线保障访问安全,整个配置过程不需要写一行代码。 第二章 前置条件——API发布前要准备好什么 在开始一键发布API之前,需要完成以下两个前置准备,确保配置过程顺畅无阻。 一、共享库(DS层)数据源已接入 确认数据源接入中,共享库的数据源已配置并连接正常。数据中台采用五层分层架构对数据进行递进式治理:来源库(SRC,Source)直接从业务系统接入原始数据;贴源库(ODS,Operational Data Store)保存与源系统结构一致的镜像数据;治理库(DW,Data Warehouse)完成数据清洗、标准化和模型设计;应用库(ADS,Application Data Store)存放面向具体业务场景的汇总结果数据;共享库(DS,Data Sharing)是数据中台对外提供数据共享服务的统一出口。自助API默认从共享库DS层读取数据对外提供服务,因为DS层的数据已经过了完整的数据质量校验和标准化处理,是数据治理后的"成品"数据。但不仅限于DS层——根据实际业务需要,也可以选择治理库DW层(需要标准化但无需对外统一出口的数据)或应用库ADS层(面向具体业务场景的汇总数据)作为API的数据源。检查路径为「数据集成→数据源接入」,确认所需数据源的连接状态为"正常"。 二、了解目标数据表结构 明确要共享的表名、字段清单,以及哪些字段需要脱敏处理(如身份证号、手机号、银行卡号等个人敏感信息)。自助API在配置SQL时支持主子表嵌套返回——主查询返回主表数据,子查询返回关联的子表数据,最终以嵌套JSON结构输出。同时平台提供字段转换规则引擎,支持值映射(如将代码值"F"转换为"女")、日期格式化、正则表达式、默认值填充以及字符串脱敏等多种后处理能力。提前梳理好敏感字段清单,可以在后续第三步"转换规则设置"中一次性完成配置,避免API上线后发现数据脱敏遗漏再回退修改。 关键配置前置条件速查 前置条件 确认位置 说明 共享库数据源已接入 数据集成→数据源接入 共享库DS数据源连接正常 了解表结构和敏感字段 数据治理→元数据管理 明确哪些字段需脱敏处理 第三章 操作步骤一——创建API服务与自助API 3.1 创建API服务 第一步是创建一个API服务。API服务是多个API的逻辑分组容器,你可以把它理解为一个"服务文件夹"——同一个业务域下的多个API(如客户域下的客户信息查询、订单查询、积分查询等)统一归属到一个API服务下进行管理。进入「数据共享→API共享→服务维护」,点击"新增服务"按钮打开创建窗口。 在创建窗口中需要填写两个名称:服务名称(英文,如customer)和服务显示名称(中文,如"客户数据服务")。服务名称会作为API访问地址的前缀——假设数据中台部署在http://192.168.1.100:8080,服务名称为customer,则该服务下所有API的访问地址都以http://192.168.1.100:8080/customer/开头。服务名称要求全平台唯一,建议按业务域命名,字母开头、长度控制在32位以内。服务显示名称仅用于运维人员在管理界面中识别,对调用方不可见。 创建服务的同时即可配置流控管理,这是访问控制的第一道防线。流控包含两个核心指标:并发数(同一时刻系统正在处理的请求数量上限,数值范围1-9999,不填写则无限制)和日最大访问量(一天内系统处理的总请求数上限,数值范围1-9999,不填写则无限制)。这两个指标分别从"瞬间冲击"和"持续消耗"两个维度保护后端数据库。配置完成后点击"上线"按钮使服务生效——注意,创建服务不等于服务上线,服务上线后该服务下的API才可被调用;服务下线后该服务下所有API均不可调用,再次上线后立即恢复(配置和授权关系均不会丢失)。 API服务维护配置表 配置项 填写内容 说明 服务名称 英文,如customer 作为API访问地址前缀,字母开头,长度1-32位 服务显示名称 中文,如"客户数据服务" 管理界面识别用,调用方不可见 并发数 1-9999(不填视为无限制) 服务级并发数上限,控制同一时刻的并发请求量 日最大访问量 1-9999(不填视为无限制) 服务级日调用总量上限,控制单日总请求数 3.2 新增自助API 创建好API服务后,下一步是新建具体的API。进入「数据共享→API共享→API管理」,点击"新增自助API"。自助API(Self-Service API)是通过自定义SQL语句直接从数据库查询数据并返回结果的API,属于零代码开发模式——配置者只需编写SQL和设置基本参数,平台自动生成完整的RESTful接口,省去了传统开发中"写Controller→写Service→写DAO→写测试用例"的全部编码工作。目前平台支持的数据库类型包括MySQL、Oracle、SQLServer、PostgreSQL、DM8(达梦数据库)、Doris(Apache Doris分析型数据库)以及Vastbase_G100(海量数据库)等主流数据库。 自助API采用六步引导式配置流程,下面逐一说明。 第一步:设置API基本信息 配置项 填写说明 API名称 自定义API名称(中文),如"客户订单查询接口",便于管理识别 请求方法 GET(查询类接口)/ POST(提交数据或复杂查询场景) 请求类型 GET方法无需设置;POST方法可选application/json等格式 鉴权模式 签名模式(HMAC-SHA1动态签名)/ 简易模式(仅校验AppKey)/ 不鉴权(详见第四章) API路径 URL访问路径,全平台唯一,如/customer/order/query API描述 API用途说明,便于调用方理解接口功能 第二步:配置查询SQL语句 选择数据源(推荐选择已接入的共享库DS层数据源,也可根据业务需要选择治理库DW层或应用库ADS层,检查路径:「数据集成→数据源接入」),然后编写SQL语句。SQL中可以使用${参数名}占位符来引用查询参数——当调用方发起API请求时,URL中传递的参数值会自动填入SQL占位符位置。例如SQL语句写为SELECT * FROM customer_order WHERE customer_id = ${customerId},调用方请求/customer/order/query?customerId=12345时,实际执行的SQL会替换为SELECT * FROM customer_order WHERE customer_id = '12345'。编写完SQL后点击"执行SQL"按钮,系统会自动识别SQL中的参数占位符并展示在"输入参数"和"返回参数"区域中,参数的类型和示例值由系统根据数据库元数据自动推断。 自助API支持主子表嵌套返回的高级特性。主表查询和子表查询通过"数据集标识"进行关联:主表设置一个英文标识(如student),子表在查询参数中引用主表的数据集标识作为前缀(如${student.no}),平台会自动按关联键组织嵌套JSON结构。以学生信息系统为例,主表student_info查询学生基本信息,数据集标识设为student,SQL为select * from student_info where no = ${no};子表student_profiles查询学生各科成绩,数据集标识设为score,SQL为select * from student_profiles where no = ${student.no}——返回结果会以如下嵌套JSON结构呈现: { "student": { "no": "2024001", "name": "张三", "class": "计算机科学2024级" }, "score": [ {"no": "2024001", "subject": "数据结构", "score": 92}, {"no": "2024001", "subject": "操作系统", "score": 88} ] } 第三步:转换规则设置 在返回参数列表中,对敏感字段或需要格式化的字段点击"添加规则"按钮。平台内置的转换规则类型包括:值映射(将代码值转换为可读中文,如性别字段F→女、M→男)、剪切字符串、日期格式化(如将时间戳1700000000转换为2023-11-15)、正则表达式提取、默认值填充(当字段值为空时自动填入默认值)、字符串补齐、字符串脱敏以及自定义脚本等。 脱敏(Data Masking,数据遮蔽)是共享场景下使用频率最高的转换规则。以身份证号脱敏为例:选择"字符串脱敏"规则,设置开始位置为4、结束位置为14、替换内容为*,则原始值320102199001011234经规则处理后输出为320**********1234——出生日期信息被遮蔽,但仍保留了地区码和校验位供必要时进行区域统计或格式校验。 第四步:测试API 填写输入参数的测试值,点击测试按钮,系统将在右侧展示完整的请求URL、响应状态码和返回数据结果。测试环节需要重点验证三个方面:SQL逻辑是否正确(返回的数据是否符合预期筛选条件)、参数映射是否准确(入参值是否被正确替换到SQL中)、转换规则是否生效(脱敏字段和格式化字段输出是否符合规则设定)。 第五步:流量控制 为该API单独设置并发数和日最大访问量。API级流控的优先级高于服务级流控——当API级流控设置了独立阈值时,该API以API级阈值为准,不受服务级阈值约束;当API级未设置时,继承服务级流控配置。建议对核心业务API(如订单查询、支付状态查询)单独设置更严格的API级流控,保证关键业务的资源独占;对辅助性API(如字典查询、配置查询)可以复用服务级的默认流控阈值。不填写代表无限制,生产环境建议两项均设置合理阈值。 第六步:下载API文档 配置完成后,平台自动生成一份完整的API接口文档,内容包括请求方法(GET/POST)、请求类型(Content-Type)、鉴权模式、输入参数清单(参数名、类型、是否必填、示例值)、返回参数清单(字段名、类型、说明)、返回示例(JSON格式的样例数据)。调用方无需人工沟通,参考文档即可完成对接开发,大幅降低跨团队的沟通成本。 自助API六步配置速查 步骤 操作 关键配置 说明 第一步 API基本信息 API名称、请求方法、鉴权模式 GET用于查询,POST用于提交或复杂查询 第二步 查询SQL 数据源、SQL语句、数据集标识 支持${}参数占位符和主子表嵌套 第三步 转换规则 脱敏、值映射、日期格式化 对敏感字段和格式化字段添加规则 第四步 测试API 测试参数值 验证SQL逻辑、参数映射、转换规则 第五步 流量控制 并发数、日最大访问量 API级流控优先级高于服务级 第六步 下载文档 自动生成 含请求/返回参数和样例数据 3.3 了解其他API类型(背景补充) 除了自助API之外,龙石数据中台还提供了两种辅助型API类型,用于覆盖"已有API纳管"和"复杂流程编排"两类场景。 穿透API(Proxy API):企业往往已经有一些现成的第三方API在运行,这些API分散在不同的系统中,管理起来很不方便。穿透API的作用是把已有的第三方API注册到数据中台统一纳管——不需要修改原API的任何代码逻辑,平台作为代理层实现地址转换(调用方访问平台统一地址,平台透明转发到真实API地址)、统一鉴权(在平台层叠加鉴权策略)、调用日志(自动记录每次调用的请求和响应详情)。新增穿透API时,请求方法、请求类型、鉴权模式、代理地址等参数必须与原API完全一致,否则代理转发会失败。 编排API(Orchestration API):当单个自助API无法满足需求时——比如需要一次请求同时调用多个数据源的接口并融合返回结果,或者需要按条件分支执行不同的API调用链——编排API提供了拖拽式可视化画布来组装复杂的API流程。编排组件库包括:Restful API调用、WebService(一种基于SOAP协议的网络服务接口标准)调用、数据库表查询/输出/更新、JSON/XML报文互转、条件判断、流程分支以及Java自定义逻辑等。编排API适用于跨系统数据聚合、主子表跨多库的事务性保存、跨系统业务流程触发等复杂场景。举例来说,一个"创建订单"的编排API可以在一次请求中同时完成在订单库插入订单记录、在库存库扣减库存、在用户库检查并更新用户等级——三个数据库操作要么全部成功、要么全部回滚,保证数据一致性。 第四章 操作步骤二——配置访问控制策略 访问控制是API共享安全的基石。龙石数据中台提供三道防线构成纵深防护体系:鉴权(验证调用者身份——"你是谁")→ IP白名单/黑名单(控制访问来源——"从哪来")→ 流量控制(限制调用频次——"用多少")。三道防线既可以独立使用也可以灵活组合,适配从公开数据到敏感交易数据的不同安全等级需求。 4.1 第一道防线:API鉴权——验证"你是谁" 鉴权(Authentication,身份认证)回答的是"谁在调用这个API"的问题。进入「数据共享→API共享→API授权」,平台采用统一的AppKey + SecretKey(应用密钥对)授权模式:系统为每个调用者自动生成一对唯一的AppKey(应用标识)和配对的SecretKey(应用密钥),AppKey作为调用者的身份标识在API请求中传递,SecretKey由调用方妥善保管用于生成请求签名,不通过网络传输。 平台提供三种鉴权模式,在新增或编辑API时选择: 鉴权模式 技术原理 适用场景 安全等级 签名模式 使用HMAC-SHA1(基于哈希的消息认证码算法,Hash-based Message Authentication Code with SHA-1)对请求参数动态生成签名摘要。每次请求的签名都不同(因为包含了时间戳和随机数),可有效防止重放攻击——攻击者截获一个请求后无法直接重复使用,因为过期的签名会被服务端拒绝 交易数据、个人敏感信息(如身份证号、手机号、银行卡号)、财务数据等 ★★★ 简易模式 仅校验请求中携带的AppKey是否在平台中存在且处于有效状态,不校验请求参数是否被篡改 内部系统之间的非敏感数据查询、低频调用场景 ★★☆ 不鉴权 不采取任何身份验证措施,任何人知道API的完整URL地址即可发起调用 公开数据(如天气、节假日信息)、测试环境调试阶段 ★☆☆ 配置建议:涉及用户个人信息的API必须使用签名模式;内部系统间的非敏感数据查询(如部门列表、组织架构)可使用简易模式降低对接复杂度;测试阶段的API可临时选择不鉴权,但务必同时开启白名单将访问来源限定在测试服务器的IP范围。API上线后可以随时修改鉴权模式——服务下线→修改鉴权模式→重新上线即可生效,已有的授权关系不丢失。 4.2 第二道防线:IP白名单/黑名单——控制"从哪来" 进入「数据共享→API共享→白名单 / 黑名单」。白名单和黑名单从网络层面对调用来源进行准入控制,是鉴权的有效补充——鉴权回答"你是谁",白名单/黑名单回答"请求从哪个网络地址来的"。 白名单(Allowlist):开启后,仅允许白名单列表中列出的IP地址发起请求,不在白名单内的IP一律被拒绝访问。白名单的防护逻辑是"默认全部拒绝,只放行已知IP"——这是一种最小权限原则的实践。在配置白名单时需要注意:如果API前面有负载均衡器(如Nginx、F5等)、API网关或反向代理,务必把网关/代理服务器的出口IP也加入白名单,否则经过网关转发的请求虽然来自合法调用方,但因为到达平台的IP是网关IP而非原始调用方IP,会被白名单拦截。 黑名单(Blocklist):将非法或异常的IP加入黑名单后,来自该IP的所有调用请求将被直接拒绝。黑名单的典型使用场景是动态防御——当监控到某个IP在短时间内发起大量鉴权失败请求(疑似暴力破解AppKey)、或某个IP的请求量异常飙升(疑似爬虫或攻击脚本),将该IP加入黑名单快速阻断攻击。黑名单的作用与白名单互补:白名单做"准入控制",黑名单做"攻击响应"。 组合策略建议:推荐采用"白名单为主、黑名单为辅"的配置策略。先通过白名单将API的访问来源精确限定在已知的业务系统IP和网关IP范围内,再通过黑名单动态封禁来自这些已知IP中出现的异常调用行为。两者叠加使用可以同时覆盖"防止未知来源访问"和"已知来源中的异常行为处置"两个安全维度。 4.3 第三道防线:流量控制——限定"用多少" 流量控制(Rate Limiting,速率限制)从调用频次维度保护后端服务的稳定性。流量控制分两个层级: 层级 控制指标 配置位置 粒度说明 服务级流控 并发数 + 日最大访问量 API服务维护 → 流控管理 整个服务下所有API共享配额 API级流控 并发数 + 日最大访问量 新增/编辑API → 流量控制 单个API的独立配额 并发数控制的是"同一时刻系统正在处理的请求数量上限",它的防护目标是瞬间流量洪峰——比如某个业务系统在整点批量触发了几百个API调用,并发数限制确保同时进入数据库的请求不会超过后端数据库的连接池容量。日最大访问量控制的是"一天内系统处理的总请求数上限",它的防护目标是持续低频但高总量的异常调用——比如某个调用脚本因为代码Bug写成了死循环,以每秒1个请求的速度低调运行,并发数永远不会触发,但持续24小时就是86400个请求,日最大访问量可以在总量层面拦住这种"温水煮青蛙"式的消耗。 两个指标从不同维度保护系统,建议在生产环境中同时设置合理的阈值。优先为交易类API(下单、支付等直接关联业务结果的接口)设置较低的日最大访问量,为查询类API(数据列表、统计报表等只读接口)设置较高的日最大访问量或复用服务级默认值。不填写代表无限制,仅建议在测试环境或内部工具类API中使用。 三道防线配置速查 防线 机制 解决的问题 配置路径 关键操作 第一道 鉴权(AppKey + SecretKey) 验证调用者身份合法性 API共享→API授权 创建AppKey/SecretKey,选择鉴权模式 第二道 白名单/黑名单 控制请求来源IP范围 API共享→白名单/黑名单 添加/删除IP地址,开启/关闭开关 第三道 流量控制(并发数+日最大访问量) 限制调用频次 服务维护/API管理 设置服务级和API级阈值 第五章 验证结果——发布后的监控与调用 5.1 调用测试 API发布并上线后,可以通过三种方式进行调用测试。第一种是使用平台内置的测试功能——在API管理列表中找到目标API,点击"测试"按钮,输入参数值后直接查看返回结果,这是快速验证最便捷的方式。第二种是使用Postman——一款流行的API调试工具——将平台生成的API文档中的请求地址、请求方法和参数填入,发送请求验证。第三种是在命令行中使用cURL工具发起HTTP请求验证,适合自动化测试脚本集成。 以下是一个典型的cURL调用示例(以签名模式为例,签名参数由平台提供的SDK工具包自动计算生成): curl -X GET "http://192.168.1.100:8080/customer/order/query?customerId=12345" \ -H "AppKey: your_app_key_value" \ -H "Timestamp: 1719654321" \ -H "Signature: (由HMAC-SHA1算法计算生成的签名值)" 验证时需要重点检查三个方面:返回数据的字段完整性(所有预期字段是否都出现在返回结果中)、数据准确性(查询条件和返回值的对应关系是否正确)、脱敏效果(敏感字段的输出是否符合脱敏规则设定)。如果发现SQL逻辑有问题,可以直接编辑API修改SQL后重新测试,无需像传统开发流程那样走"改代码→部署→重启服务"的流程。 5.2 调用分析——三维度监控 进入「数据共享→API共享」,平台从三个维度提供API调用数据的可视化监控分析,帮助运维人员实时掌握API的使用情况: 分析维度 入口 展示内容 服务维度 API服务调用分析 每个API服务的每日调用量(成功次数/失败次数分别统计)、历史调用总量、今日实时调用量、日调用量趋势折线图 用户维度 API用户调用分析 每个AppKey调用者的今日调用量(成功/失败数)、历史调用总量、日调用量趋势——用于识别哪个调用方的用量异常增长 API维度 API调用分析 每个API的今日调用量(成功/失败次数)、历史调用总量、日调用量趋势——用于定位哪个API是热点接口 三个维度的分析互相补充:服务维度的趋势图帮你发现某个业务域的调用量是否在持续增长(需要扩容),用户维度帮你发现某个调用方的调用行为是否异常(如某个AppKey的失败率突然从2%飙升到40%,说明该调用方可能对接有问题),API维度帮你发现哪些API被调用最频繁(可能需要做缓存优化或SQL调优)。 5.3 API质量监控 除调用量统计外,平台还提供"API集监控"功能用于持续的API质量检测。将需要监控的多个API加入一个测试集后,配置以下三种监测规则: 可用性监测:定期向API发送测试请求,检查响应状态码是否为200(HTTP协议中的成功响应代码),判断API服务是否正常运行。 正确性监测:检查响应报文(HTTP响应正文)中是否包含预期的关键内容——例如在返回JSON中验证是否包含"code":"success"字段——确保API不只"能通",而是"通得对"。 响应时间监测:检测API的响应耗时是否在设定的毫秒阈值内,超出阈值即判定为性能异常。 当任一监测规则触发异常时,平台自动通过微信、短信、邮件三种渠道向指定联系人发送告警通知,告警信息中附带异常原因的初步诊断(例如"响应超时,耗时3200ms,超过阈值2000ms"、"返回状态码500,疑似后端数据库连接失败"),帮助运维人员快速定位问题根因。 第六章 配置速查模板 本章将全文分散在各章节中的配置项整合为一张速查表,方便读者在实际操作时对照参考。 配置维度 配置项 填写内容 说明 服务维护 服务名称 英文,如customer 作为API地址前缀,字母开头,长度1-32位 服务显示名称 中文,如"客户数据服务" 管理界面识别用,调用方不可见 并发数 1-9999 服务级并发数上限,不填无限制 日最大访问量 1-9999 服务级日调用总量上限,不填无限制 自助API基本信息 请求方法 GET / POST 查询用GET,提交或复杂查询用POST 鉴权模式 签名/简易/不鉴权 敏感数据用签名,内部用简易,测试用不鉴权+白名单 数据源 共享库DS/治理库DW/应用库ADS 推荐选DS层,也可按需选DW或ADS层 SQL语句 SELECT ... WHERE field = ${param} 支持${}占位符绑定查询参数 最大返回记录数 正整数,如10000 防止单次查询返回数据过多导致内存溢出 数据集标识 字母开头,如student 主子表嵌套时主表标识,子表引用${主表标识.字段} 转换规则 脱敏 位置(开始/结束)+替换内容 身份证:位置4-14,替换为* 值映射 原始值→目标值 如F→女、M→男 日期格式化 格式字符串 如yyyy-MM-dd 默认值填充 默认内容 字段值为空时自动填入 流控(服务级+API级) 并发数 1-9999 同一时刻正在处理的请求数上限 日最大访问量 1-9999 一天内总请求数上限 访问控制 白名单 IP地址列表 仅允许白名单IP访问(开启后生效) 黑名单 IP地址列表 拒绝黑名单IP访问 API授权 AppKey / SecretKey 系统自动生成 每个调用方分配一对,AppKey用于身份标识,SecretKey用于签名 第七章 避坑指南与方法论收尾 7.1 避坑指南 坑一:测试时选"不鉴权",上线后忘记切回签名模式 在测试阶段,很多操作人员为了让调试过程更顺畅,选择了"不鉴权"模式,测试通过后填写上线检查清单时漏了"鉴权模式确认"这一项,直接把API发布上线。结果API在公网环境中没有任何身份验证措施,任何人知道了API地址就能直接通过浏览器或脚本拉取数据。这种情况的严重性取决于数据敏感度——如果是公开的天气数据还好说,如果是客户订单数据或个人敏感信息,后果就是数据泄露。正确的做法是:从新建API的时候就明确安全等级策略并立即选择对应的鉴权模式。测试环境如需降低鉴权门槛,可以用"简易模式+白名单限制测试IP"的组合替代裸奔的"不鉴权"模式。如果确实需要在测试阶段用"不鉴权",务必在测试完成后的上线检查清单中把"切换鉴权模式"作为必检项。 坑二:流控只配了并发数,没配日最大访问量 并发数和日最大访问量是对应两种不同攻击形态的防护指标,不能互相替代。并发数挡的是"洪峰型"攻击——攻击者在极短时间内发起大量并发请求,希望打满数据库连接池让服务瘫痪。日最大访问量挡的是"渗透型"消耗——攻击者或Bug脚本用不高不低的频率持续请求,比如每秒1次,看上去很温和,但24小时不间断就是86400次调用,如果单次返回数据1MB,一天就被拖走近10GB数据。很多运维人员觉得"我设置了并发数就够了",实际上并发数对这种"低速持久"行为完全没有反应——每次只有1个并发,远低于阈值。两项指标缺一不可,生产环境务必两项都设置。 坑三:白名单配了业务服务器的IP,忘了加API网关的IP 白名单开启后,白名单列表中的IP是唯一被允许发起请求的地址。如果API是通过API网关或反向代理(如Nginx、Kong、Zuul)对外暴露的,实际到达数据中台的TCP连接源IP是网关服务器的IP,而不是原始调用方业务服务器的IP。很多运维人员在配置白名单时只加了业务服务器的IP,结果网关代理过来的请求全部被拦截——从网关那边看请求超时,从数据中台这边看白名单拒绝日志里全是网关IP的拦截记录。排查的时候经常要来回对日志对齐时间戳才能发现是白名单漏配了网关IP。正确做法:在配置白名单时,把API调用链上所有中间节点的出口IP都列进去——包括业务服务器IP、网关服务器IP、负载均衡器IP等。 7.2 小反转——从"开发两天"到"配置十分钟" 回到第一章开头的那个场景。张工在没有数据中台之前,每次对外共享一个数据接口,需要经过"确认数据源→找开发排期→写Controller/Service/DAO代码→配鉴权机制→写接口文档→联调测试→部署上线"的全流程,按最顺利的情况估算也要两天。现在借助龙石数据中台的数据共享模块,流程简化为"进入资产目录→找到目标表→新建自助API→编写SQL语句→选择鉴权模式→开启白名单→设置流控→测试发布",八个步骤全程在可视化界面中完成,不需要写一行代码,全流程稳定控制在十分钟以内。而且这不仅是一次性的效率提升——后续的调用量统计、调用方管理、质量监控、异常告警全部由平台自动运转,张工不再需要被动地等业务部门来问"接口能不能用""为什么返回慢了""这个月调了多少次",所有数据在监控面板上一目了然。从"有人找才响应"变成了"系统自动管",这才是数据共享模块解决的核心问题——不只是省了两天开发时间,而是把数据共享这件事从"项目制的手工作坊"变成了"平台化的标准流水线"。 7.3 方法论收尾 龙石数据中台遵循"理、采、存、管、用"五阶方法论。前四个阶段——"理"清数据战略与业务方向、"采"集汇聚多源异构数据、"存"入分层模型的数据仓库、"管"控数据质量与标准规范——所有的投入和建设,最终都要在"用"这一阶段兑现业务价值。API共享模块正是"用"阶段的核心能力载体之一:它不是在简单地"把数据扔出去",而是在"服务维护→鉴权授权→黑白名单访问控制→双层流量管控→多维度调用分析→持续质量监控"的一整套机制框架下,实现数据在"用得出去"和"管得住、看得清"之间取得平衡。 在江苏某数据局的共享交换平台中,全市百余个政务节点、近4万个交换任务、千余个API服务稳定运行,库表交换量累计近千亿条,API实时交换支撑跨省通办业务实现毫秒级数据核验;在某211大学的智慧校园项目中,基于数据中台搭建的数据超市上线后,跨部门数据申请从以往的"天/周级"线下审批模式缩短到"分钟级"在线自助获取,人力处、学生处、教务处等数十个部门的数据共享效率显著提升。这些案例背后验证的核心逻辑是:数据共享的价值不在于"技术有多复杂",而在于"访问有多简单、管控有多精细"。让数据在安全可控的前提下高效流动,才是数据中台建设的最终目的。 FAQ 1. 三种鉴权模式怎么选?签名模式、简易模式、不鉴权各自适用什么场景? 签名模式基于HMAC-SHA1算法对每次请求参数动态生成签名摘要,每次请求签名不同,可有效防止重放攻击(攻击者截获一次合法请求后不能直接重复使用),适用于交易数据、财务数据、个人信息等敏感场景。简易模式仅校验AppKey是否存在且有效,不验证请求内容是否被篡改,对接复杂度低但安全等级居中,适用于内部系统之间的非敏感数据查询或低频调用。不鉴权不采取任何身份验证措施,适用于公开数据或测试环境,但必须同时开启白名单保护以限制访问来源范围。三种模式可由调用场景的数据敏感度和网络环境综合决定。 2. 白名单和鉴权能同时开启吗?不鉴权的API开启白名单后安全吗? 可以同时开启。鉴权验证"调用者是谁"(身份认证),白名单验证"请求从哪来"(来源限制),两者是互补的安全维度,不存在互斥关系。同时开启时,请求必须同时满足"AppKey合法(或签名验证通过)"和"来源IP在白名单内"两个条件才能通过。不鉴权的API开启白名单后,虽然不验证调用者身份,但只有白名单中的IP才能发起请求——适合完全信任的内网环境(内网IP本身就是一种身份背书)或对外提供只读公开数据的场景。 3. 并发数和日最大访问量分别控制什么?不填写代表什么? 并发数控制同一时刻系统正在处理的请求数量上限,防护目标是瞬间流量洪峰(如定时任务批量触发调用)。日最大访问量控制一天内系统处理的总请求数上限,防护目标是持续低频但高总量的异常调用(如脚本Bug导致的长时间循环调用)。两个指标从瞬间峰值和持续总量两个维度互补防护,不能互相替代。不填写代表无限制,建议生产环境两项均设置合理阈值。 4. 自助API和穿透API有什么区别?什么时候用哪个? 自助API是通过自定义SQL从数据库直接查询数据生成全新的API,属于零代码新建模式,API的逻辑在数据中台内部运行。穿透API是将已有的第三方API注册到数据中台统一纳管,不改原API逻辑,平台作为代理层提供地址转换、统一鉴权、调用日志等附加能力。如果数据存储在龙石数据中台的共享库中,用自助API直接在平台上创建;如果已有现成的外部API需要统一管理、监控和鉴权,用穿透API纳管。 5. API服务下线后已有的调用方会怎样?重新上线能恢复吗? 服务下线后,该服务下所有API将立即停止响应,调用方会收到HTTP连接失败或超时错误(具体取决于网关配置)。再次点击"上线"按钮后API调用立即恢复正常——不会丢失任何配置信息,不会影响已有的AppKey/SecretKey授权关系,也不会清空调用统计历史数据。服务下线是一个可逆的管理操作,常用于维护窗口期或紧急安全处置场景。 6. 自助API支持哪些数据库类型?查的是哪个库的数据? 自助API支持MySQL、Oracle、SQLServer、PostgreSQL、DM8(达梦数据库)、Doris(Apache Doris分析型数据库)、Vastbase_G100(海量数据库)等主流数据库。查询的数据源在创建API时自由选择——推荐选择共享库DS层,因为DS层是数据中台五层架构(SRC→ODS→DW→ADS→DS)中对外提供数据共享服务的统一出口,DS层的数据已经过完整的质量校验和标准化处理。 7. 如何监控API的可用性和正确性? 进入「数据共享→API共享」中的"API集监控"功能,将需要监控的多个API加入一个测试集,配置三种监测规则:可用性监测(检查响应状态码是否为200,确保服务正常运行)、正确性监测(检查响应报文中是否包含预期关键内容,如"code":"success",确保API逻辑正常)、响应时间监测(检测响应耗时是否在设定的毫秒阈值内)。任一规则触发异常时,平台自动通过微信、短信、邮件三种渠道向指定联系人发送告警,告警信息附带异常原因便于快速定位。 8. 编排API能做什么自助API做不到的事? 编排API的核心能力是服务聚合与流程编排。它可以一次请求协调调用多个独立的自助API或外部API并融合返回结果(如同时查订单信息和用户信息合并返回),可以按条件判断走不同分支(如根据订单金额是否大于阈值决定走不同的审批流程),可以在编排画布中嵌入自定义Java逻辑处理复杂计算,可以实现跨多库的事务性操作(如订单创建同步扣减库存和更新用户积分,三个操作要么全部成功要么全部回滚)。自助API本质是"一个SQL→一个API"的一对一映射,编排API是"多个API+流程控制+事务管理→一个聚合API"的多对一编排。 本文为操作实践指南,所述操作路径和配置参数基于龙石数据中台产品公开功能。文中案例数据来自公开的项目建设成果通报及相关文献资料,供读者参考。 参考来源: DAMA International,《DAMA数据管理知识体系指南(第二版)》(DAMA-DMBOK2),机械工业出版社,2020年。 GB/T 36073-2025《数据管理能力成熟度评估模型》(DCMM 2.0),国家市场监督管理总局、国家标准化管理委员会,2025年发布。
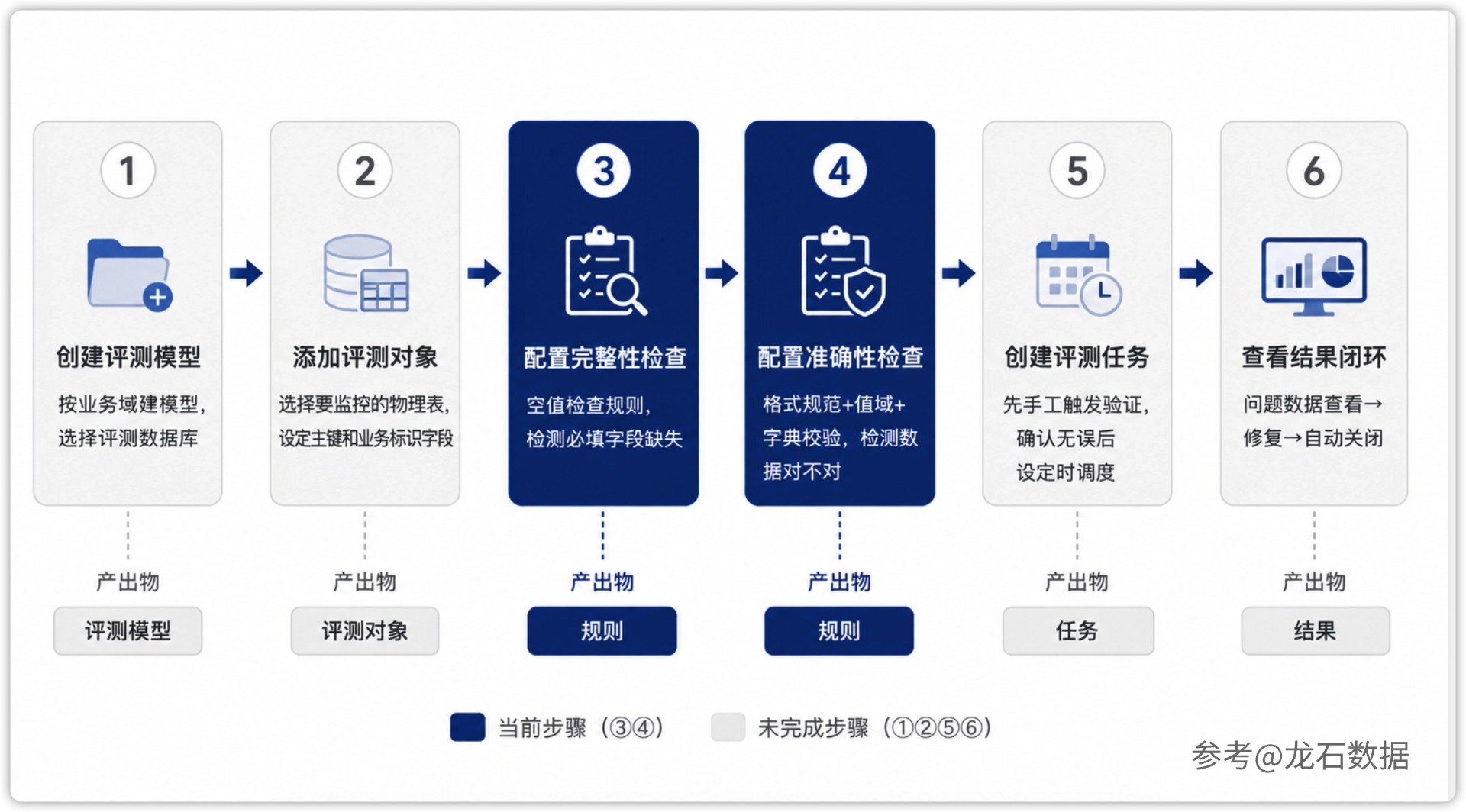
一、场景钩子 业务部门的运营同事对着BI报表犯了难:上周出的客户分析报表,不同页面展示的客户数量对不上,营销部门据此做的短信推送要么发给了空号,要么漏掉了关键客户。追溯原因后发现,CRM(客户关系管理系统,Customer Relationship Management)同步过来的客户信息表中,联系方式字段空了1,200多行,手机号有800多条格式明显异常——有的8位、有的12位,还有的夹杂着座机号码。业务负责人直说:"这数据谁敢用?能不能在数据入库的时候自动扫一遍,把有问题的找出来?" 这不是个别现象。企业数据中台每天汇聚多个业务系统的数据,源系统的录入规范、历史数据质量、接口传输稳定性,任何一个环节都可能引入脏数据。如果每一批数据都要靠人工写SQL去排查,效率低、覆盖面窄,而且查完这批下批又来了。更务实的做法是建立一套自动化的旁路监测机制——数据正常入库,质量检查并行扫描,发现问题的同时不阻断业务链路。配好几条规则,系统就能每天自动把问题数据标记出来。 二、前置准备:理解旁路监测 在动手配置规则之前,有必要厘清一个关键概念:旁路监测与强校验的本质区别。强校验模式在数据入库前执行检查,不合格的数据被拦截、无法写入。这种模式逻辑上没有问题,但在实际项目中风险很大——凌晨的ETL(数据抽取、转换、加载,Extract-Transform-Load)任务可能因为一条正则表达式配错而卡住整条数据管道,导致所有下游报表和业务系统当日无数据可用。旁路监测则采用不同的策略:数据正常完成入库,质量评测任务在入库后独立并行运行,扫描结果生成问题清单、触发告警或工单,但不阻断数据流转。这一设计符合DAMA(国际数据管理协会)DMBOK2(《数据管理知识体系指南》第二版)中"质量管理应优先保障业务连续性"的原则。 龙石数据中台的质量管理模块采用旁路监测模式——不侵入现有数据链路、不阻断数据入库、支持从发现到修复再到验证的完整闭环。龙石是DAMA大中华区实训基地,也是中国信通院《数据治理产业图谱3.0》入选厂商。 在确定监测模式之后,还需要一个衡量"什么叫高质量数据"的标准框架。GB/T 36344-2018《信息技术 数据质量评价指标》定义了六个评价维度:完整性、准确性、一致性、规范性、时效性、可访问性。其中,除可访问性外,其余五个维度直接影响数据在业务中的应用效果,也是日常质量监控中最常配置规则的维度。下文的操作演示将依次覆盖完整性(字段是否为空)、规范性/准确性(手机号格式是否合规)、一致性(性别编码是否在标准字典范围内)三个核心维度。 三、操作步骤:配置一条完整的质量监控规则 以下配置以CRM客户信息表customer_info为例。该表每天从CRM系统增量同步到DW(治理层数据仓库,Data Warehouse治理层)中,业务要求自动检查三件事:客户姓名和手机号不能为空、手机号格式符合中国大陆手机号规范、性别代码必须在标准字典规定的取值范围内。以下八个步骤均可在龙石数据中台的「数据质量」模块中独立完成。 第一步:创建评测模型 评测模型是按业务域组织质检规则的容器,一个模型对应一个评测库,内部可挂载多个评测对象和若干条规则。进入「数据质量 → 评测模型管理」页面,点击"新增模型",模型名称填写"客户信息质量评测",评测库选择治理库(DW)。评测库的选择决定了后续规则扫描的数据范围,模型创建后若修改关联评测库,已配置的规则需要重新绑定——因此建议在创建之初就确认好评测库,避免后期返工。 第二步:添加评测对象 在新建的评测模型中新增评测对象,选择customer_info表作为被评测的数据表。被评测的表必须具备物理主键或逻辑主键。逻辑主键是指业务层面能够唯一标识一条记录的字段组合,例如客户编号、合同编号等——当数据库表中没有设置物理主键时,可以通过指定逻辑主键来确保每条问题数据可被精确定位。此外,还需要设置业务标识字段,指定一个业务含义明确的字段(如customer_name),这样在后续的问题数据列表中,每条记录会优先展示客户姓名,而不是难以辨认的技术ID,方便业务人员快速识别是哪条客户记录出了问题。 第三步:配置空值检查规则(覆盖完整性维度) 在评测对象下新增规则,规则类型选择「空值检查」,检查字段勾选customer_name和phone,检查方式选择"每个字段都不能为空"。这种规则解决的是"数据有没有"的问题——确保核心业务字段不缺失。配置规则参数时,有三项内容需要认真填写: 配置项 填写内容 说明 规则权重 高 客户姓名和手机号是营销触达的核心字段,缺失直接影响业务效果 错误描述 客户姓名或联系电话存在空值,影响客户画像生成、营销分组和短信触达 用业务语言说明什么问题、影响什么场景 修复建议 请核对CRM系统中对应客户的基础信息是否完整录入,补全后重新同步 给出可操作的具体步骤,而非仅描述状态 错误描述的撰写有一个实用原则:回答三个问题——什么数据出了什么问题(用业务语言而非技术字段名)、影响了下游哪个业务环节、应该怎么修。这条原则适用于所有规则类型的错误描述撰写。 第四步:配置格式规范性检查规则(覆盖规范性/准确性维度) 规则类型选择「格式规范性检查」,检查字段选择phone。格式规范性检查与空值检查的区别在于:空值检查回答"有没有",格式规范性检查回答"对不对"。这里使用EL表达式(Expression Language,一种简单的表达式语言,用于在平台上进行轻量级规则配置,无需编写Java代码)来定义手机号的校验规则。在表达式输入框中填入: #phone REGEXP '^1[3-9][0-9]{9}$' 这条表达式的含义是:phone字段的值必须是以1开头、第二位为3到9之间的数字、后面跟随9位数字的11位手机号格式。EL表达式支持直接复制使用,配置完成后可先在页面上点击「表达式测试」输入几个样例值验证逻辑是否正确。规则权重设为"高",错误描述写为"客户手机号格式不符合中国大陆手机号规范,影响短信触达和客户回访",修复建议写为"请核对CRM源系统中客户手机号的录入格式,按11位手机号规范修正后重新同步"。 第五步:配置引用完整性检查规则(覆盖一致性维度) 规则类型选择「引用完整性检查」,检查字段选择gender(性别)。引用完整性检查又称字典校验,用于验证字段的取值是否在预先定义的标准字典范围之内。前提是数据标准模块中已经定义了"性别代码"标准字典:M代表男、F代表女。在规则配置中关联该字典后,系统会自动比对customer_info表中gender字段的每一个值是否在{M, F}的合法范围内。引用完整性检查的一个关键特性是:当数据标准模块中的字典定义发生变更时(如新增了"U=未知"的取值),所有引用该字典的质检规则会自动同步更新,不需要逐条手动修改。规则权重设为"中",错误描述写为"客户性别编码不在标准字典范围内,影响客户分群和画像标签的准确性",修复建议写为"请核对CRM源系统中对应客户的性别信息,按标准字典(M=男/F=女)修正后重新同步"。 第六步:抽检验证 三条规则配置完毕后,不要急于创建正式评测任务。先在评测模型页面点击「抽检」功能,系统会在评测表中随机抽取少量数据进行规则试跑,快速验证各项规则的参数配置是否正确。抽检结果会即时展示匹配到的问题数据数量和明细,如果发现误报(如格式正确的手机号被判定为异常),可以当场调整EL表达式或规则参数。这一步骤虽然简单,但能有效避免将规则错误留到正式评测时才发现。 第七步:创建评测任务并调度 确认抽检结果无误后,进入「评测任务管理」页面创建评测任务,关联刚配置的"客户信息质量评测"模型。首次执行必须选择手工触发——手动跑一次全量评测,逐条查看结果,判断是真实质量问题还是规则配置导致的误报。确认问题清单合理之后,再将执行策略切换为定时模式。平台支持四种执行策略:手工触发、定时执行(指定一个具体时间点)、重复执行(按固定间隔周期性运行)、Cron表达式(一种Linux系统中的定时任务表达式,支持灵活定义执行时间规则,如"0 6 * * *"表示每天早上6点执行)。日常运维推荐采用重复执行-按天策略,设置在每天早上6点自动扫描前一天的增量数据,与业务使用数据的时间窗口错开。 第八步:查看结果与问题闭环 评测任务执行完成后,进入「问题数据查看」页面,可以按评测主题、评测模型、规则类型、问题状态、发现日期等多个维度进行筛选和查看。每条问题数据会展示违规字段、违反的规则、当前实际值、发现时间、状态等信息。问题闭环的完整流程是:系统扫描发现问题数据→自动标记为"待处理"状态→数据责任人认领并推动源系统修复→修复后下次评测任务自动重新扫描→验证通过后状态自动关闭。整个闭环过程中,问题的产生、分配、修复、验证都有记录可追溯。 四、执行与结果 以上述三条规则对某客户数据仓库中的86万条customer_info记录执行首次全量评测,实际产出结果如下:手机号缺失4,200条(占比0.49%),客户名称缺失1,200条(占比0.14%),手机号格式异常800条(占比0.09%),性别编码不在标准字典范围3,500条(占比0.41%),四项合计问题数据9,700条,整体问题率约1.03%。这个结果说明即便在运行多年的业务系统中,数据质量问题也并非个例——百分之一的异常率在百万级数据量下就是近万条需要处理的问题记录。 每条问题数据都可以点开查看详情:哪个字段违反了哪条规则、当前的实际值是什么、问题发现于何时。修复完成后,下一次评测任务会自动重新扫描对应记录,验证通过后问题状态自动关闭。这种"发现-标记-修复-验证-关闭"的闭环机制,让数据质量治理从一次性的人工排查变成了持续运转的日常机制。 五、项目实战中的四个常见坑 坑一:规则越多越好——认为质量监控就是要把能想到的检查项全部配上。 这个假设忽略了一个基本事实:告警的价值取决于被关注和处理的程度。实际项目中常见的情况是,团队第一次使用质量模块时热情高涨,一口气配置了三四十条规则,覆盖了几乎所有字段。第二天早上打开系统,几千条告警扑面而来,团队花了两天时间也只处理了不到三分之一。到第二周,通知被静音,第三周,质量模块实质上已被弃用。正确的做法是:先选择一到两个核心业务域,配置三到五条覆盖面广、业务影响大的高价值规则(如客户姓名空值、手机号格式、订单金额范围),跑通"发现→认领→修复→验证"的完整闭环,团队适应了节奏之后再逐批扩展规则覆盖范围。 坑二:把低价值字段等同于核心字段——没有区分"应该检查的"和"值得检查的"。 并非所有字段的缺失或异常都会对业务产生同等影响。手机号缺失直接阻断营销触达,确实值得告警;但备注字段(remark)为空,本身就是一个可空的自由文本字段,对其配置空值检查只会制造噪音。区分方法很简单:面对一个候选字段,问一句"这个字段的值出错了,下游哪个具体的业务环节会受影响?"回答不上来的字段,大概率不值得配置监控规则。 坑三:规则刚建好就设定时任务——主观认为抽检验证通过就等于规则完美。 抽检只覆盖少量样本,无法完全暴露规则在大规模数据下的表现。假设团队周五下午配置了五条规则并完成抽检,顺手设定了"每天晚上0点自动执行"的定时策略,然后下班。周末两天,系统每天凌晨定时触发评测,产生数百条误报告警堆积在系统中,周一早上团队面临的是需要逐条甄别的混乱局面。正确的流程是:规则配置完成后,第一步手工触发全量评测,第二步逐条确认问题数据的真实性,第三步剔除误报并调整规则参数,第四步确认问题清单无异常后再切换为定时策略。 坑四:错误描述用技术语言写——认为"phone字段不满足EL表达式REGEXP"这样的描述足够清楚。 技术团队可能看得懂"phone字段不满足NOT NULL约束",但业务部门看到这样的描述完全无法判断问题的严重性和处理优先级。即便是技术团队,也很难从"不满足REGEXP"中看出这条数据对业务的具体影响。正确的写法是用业务语言回答三个问题:是什么问题("客户手机号格式不符合11位手机号规范")、影响什么("导致短信触达失败,客户无法收到营销通知")、怎么修("请核对CRM源系统中客户手机号的录入格式,按11位标准修正")。好的错误描述应该让业务人员一眼看懂问题严重性,让技术人员立刻知道去哪里修。 六、小反转:真正难的,不是发现问题 按照上述步骤配置三五条规则,几十分钟就能让系统自动扫描出近万条问题数据。但真正棘手的事情在扫描完成之后才浮出水面。你标记了4,200条手机号缺失、3,500条性别编码异常,这些数据谁来补?客服部门说"这些历史数据是前任同事录的,跟我没关系",IT部门说"源系统的录入校验我们加不了,那是业务系统厂商的事",而业务部门说"数据质量问题不解决,我们的报表永远不准"。 大部分数据质量问题并非系统故障导致的,而是业务过程的产物——录入时图省事跳过了非必填字段、历史数据迁移时未做清洗、不同系统的编码规则长期不统一。质量监控规则能扫描出来的,往往只是冰山浮在水面的一角,水面之下还沉积着大量历史遗留的脏数据。 旁路监测的真正价值并不在于发现问题的能力——配几条规则就能做到的事,门槛很低。它的价值在于提供了一套持续推动问题修复的抓手:每周生成按来源系统分类的问题清单,明确"哪个系统产生的数据出了什么问题、影响范围多大、建议谁来修复";用数据说话——"本季度CRM系统产生的质量问题占全量的67%,主要集中在客户联系方式缺失"——这比任何口头的"数据质量很重要"都更有推动力。质量管理最终要解决的,不是一次性的数据清洗,而是建立一种让问题能够回到业务源头并得到修复的能力。 七、附:十二类质检规则一览 上文以客户信息表为例,演示了空值检查、格式规范性检查、引用完整性检查(字典校验)三类质检规则的配置方法。龙石数据质量模块共内置十二类质检规则,全部支持可视化配置,无需编写SQL或代码。其余规则的使用方式类似——选择规则类型、指定检查字段、配置校验参数、填写业务化的错误描述与修复建议: 规则类型 用途 典型场景 空值检查 校验必填字段是否存在空值 客户姓名、手机号不能为空 数据缺失检查 检测数据归集或共享过程中的数据丢失 源库1,000条记录,目标库仅950条 唯一性检查 检测是否存在重复数据记录 同一个学号在表中出现两次 值域检查 校验字段取值是否在合理范围内 交易金额必须大于0、年龄在0-120之间 格式规范性检查 校验字段格式是否符合规范 手机号、身份证号、邮箱格式 引用完整性检查 校验字段值是否在标准字典范围内 性别只能是男/女、省份代码在行政区划字典内 一致性检查 跨表比对数据是否一致 CRM与订单系统的客户信息保持一致 逻辑检查 验证多字段之间的逻辑关系 毛利率是否等于(收入-成本)/收入 交叉比对检查 多表联合验证数据一致性 订单状态、出库记录、物流信息三方校验 SQL检查 通过自定义SQL实现深度验证 已发货订单的承诺送达日期是否逾期 关联关系检查 验证表间的引用关系完整性 每个员工有且仅有一张工卡记录 自定义扩展 对接外部API服务进行专项校验 调用第三方地址校验接口验证地址有效性 八、常见问题 Q&A Q1:旁路监测会影响数据同步的性能吗? 通常不会。质量评测任务在数据同步任务完成后独立运行,与数据同步链路不争抢计算资源。对于千万级以上的首次全量扫描,建议使用过滤条件(如按日期范围或分区字段)限定评测范围,或采用分批评测的方式降低单次负载。后续的增量评测只扫描当日新增数据,性能压力远小于首次全量。 Q2:系统发现质量问题后,会自动修复数据吗? 不会。质量管理模块的职责是发现问题和推动治理,而不是直接修改业务数据——擅自修改源数据可能引入更严重的业务风险。问题数据被扫描出来后,进入问题库并标注所属规则、当前值和修复建议。业务侧在源系统中完成数据修正并重新同步后,下一次评测任务会自动重新扫描对应记录,验证通过后问题状态自动关闭。 Q3:什么时候用旁路监测,什么时候用强校验? 两者并不冲突,适用于不同场景。身份证号、统一社会信用代码等对数据准确性要求极高、且错误可能引发合规风险的核心字段,适合在入库环节采用强校验。客户信息、设备日志、业务标签等数据量大、更新频繁、个别脏数据不影响核心业务的场景,更适合旁路监测——既不让少数问题数据卡住整条数据链路,又能持续发现并推动修复。 Q4:规则配错了导致大量误报,怎么快速修正? 评测模型管理页面支持对已有规则进行编辑和禁用操作。如果已经产生了大量误报告警,建议先使用「清除所有问题」功能清理垃圾数据,然后修改规则参数(如调整EL表达式或放宽值域范围),修改完成后重新手工触发全量评测进行验证。这也是第七步强调"首次执行必须手工触发"的原因——给规则留出验证和调整的窗口。 Q5:业务表新增了字段,已有规则需要重新配置吗? 如果新增字段与已有规则无关,不需要任何改动。如果新增字段需要纳入质量监控,直接在对应的评测模型中新增一条规则即可,不需要重建评测模型或修改已有规则。评测模型的规则之间相互独立,支持按需灵活增减。 Q6:评测任务执行到一半失败了怎么办? 在评测任务管理页面查看失败任务的执行日志,定位具体失败原因。常见的三种情况:一是数据库连接超时,检查网络连通性和数据库连接池配置;二是规则中引用的字段在表中已被删除或重命名,需要同步更新元数据中的表结构信息,然后修正规则中引用的字段名;三是EL表达式存在语法错误,回到规则编辑页面使用抽检功能提前验证表达式的正确性。 九、方法论收尾 数据质量管理的目标,并不是一次性把所有问题都清理干净——这在企业数据环境中几乎不可能做到。更务实的目标是:在不影响业务正常运行的前提下,让数据质量问题能够持续被发现、被跟踪、被修复。规则不在多,从一个核心业务域的三到五条高价值规则起步,跑通闭环之后再逐批扩展。这一思路体现了数据治理的核心理念:不是项目验收时的一次专项行动,而是融入日常运营的持续性工作。 龙石数据中台的质量管理模块正是围绕这一理念设计——旁路监测保障业务连续性、可视化配置降低使用门槛、闭环追踪推动持续改进。在实际落地中,江苏某大数据中心通过这套机制沉淀了超过5,000条质量规则,累计评测超10亿条数据,问题修复率达到95%;华东某数据局沉淀了1,000余条监测规则,问题修复率超过93%,数据目录合格率从6.34%提升至94.74%。 规则持续运行,质量持续提升——数据治理才能真正成为日常工作的一部分。 十、参考来源 GB/T 36344-2018《信息技术 数据质量评价指标》,国家市场监督管理总局、中国国家标准化管理委员会 DAMA International,《DAMA数据管理知识体系指南》(DMBOK2),机械工业出版社 中国信通院,《数据治理产业图谱 3.0》,2024
一、一家制造企业的报表困境 某制造企业的数据工程师老张,接到老板一个看似简单的需求:"帮我出一份各事业部Q2客户合同金额Top10的报表。"数据中台已经接入了CRM(客户关系管理系统)和ERP(企业资源计划系统),网络通了,管道流量也正常,老张觉得写个SQL半小时就能交差。 结果他折腾了一下午,报表还是出不来。问题不是数据没接到,而是两个系统在说不同的"数据语言":CRM里客户名称写的是"XX科技股份有限公司",ERP里写的是"XX科技股份"——少了"有限公司"四个字,SQL的GROUP BY直接把同一个客户拆成了两条记录。CRM的合同金额是含税价,ERP里是不含税价,同一份合同两个数字,财务和销售各执一词。CRM用"A/B/C"标注客户等级,ERP用"战略/重点/普通",同一个分类维度三种写法。老张不是没数据,而是被"数据方言"困住了。 这个场景在很多建了数据中台的企业里反复出现。数据接进来了,管道的流量也正常——但如果大家说的是不同的"数据语言",中台只是一个更大的混乱仓库。 很多团队在做数据中台项目时,精力主要花在"接数据"和"跑通流程"上,数据标准管理被放在项目后期甚至直接跳过。标准不是没有——文档里有,Excel里有,共享盘里有——但它们从来没有真正进入过数据的流转链路。数据标准的制定只是序曲,真正让标准在数据流转中扎根,才是数据治理从"建完"走向"用起来"的关键一步。这个"扎根"的过程,在数据治理的专业领域有一个专门的术语,叫落标。 本文从龙石数据中台的标准模块操作入手,拆解标准配置→字段映射→质量稽核三个维度的实操路径,让标准不再是静态文档,而是数据流转中每天自动执行的规则。 二、落标到底是什么意思 在深入操作之前,有必要先厘清一个概念:什么叫"落标"。 落标,就是把文档里定义的数据标准(字段名、数据类型、值域范围、代码集),转变成数据流转中实际执行的校验规则。标准写在文档里是"纸面标准";标准挂接到物理表的字段上、在数据入库或使用环节自动校验,才算"落标"。举一个直观的对比:文档里写"性别字段取值应为男/女",这是纸面标准;平台在数据接入时自动检查gender字段是否只有M(男)/F(女)两个合法值、超出就标记为问题数据并推送给责任人,这才是落标。 从DCMM(数据管理能力成熟度模型,国家标准GB/T 36073-2025)的视角来看,情况更加清晰。DCMM在数据标准能力域中明确区分了"制定标准"和"执行标准"两个层次。很多企业卡在2级(受管理级),不是因为缺少标准文档——实际上不少企业连国标行标都整理得很齐全——而是因为标准没有进入执行链路。文档在那里,数据跑起来的时候没人去核对。DCMM的评估本质上是在问:你的标准,是在数据流转中被实际遵守的,还是只存在于制度文件里? 把这个过程拆解为三个可操作的动作: 定义:在平台中配置数据元(Data Element),即数据的基本单元,规定字段名、数据类型、值域范围、代码集等属性——对应"标准制定"模块; 挂接:把定义好的标准关联到物理表的字段上——对应"关联字典"和"字段映射"功能; 稽核:用自动化规则持续检查实际数据是否符合标准——对应"引用完整性检查"等质量稽核规则。 龙石数据中台在"理采存管用"方法论中,将"管"数据环节完整覆盖了标准落标的全部动作:标准登记(国标/行标/地标/团标/内部规范)→ 标准制定(数据元+代码集)→ 元数据管理(字段挂接)→ 质量稽核(自动化校验)。四个模块协同运转,而非各自孤立。 三、分步操作:让标准在数据中台上跑起来 以下按照真实的操作流程拆解五步。每一步均附配置表(配置项/填写内容/说明),可直接在龙石数据中台上操作执行。 3.1 第一步:标准登记——把外部标准"搬"进平台 功能位置:数据治理 → 标准登记 标准登记的职责,是将国标(GB/T)、行标、地标、团标及企业内部规范登记到数据中台,构建统一的"标准库"。这个动作把分散在不同文档、不同部门的标准集中到一个可检索、可引用的平台上,为后续的标准制定和稽核提供"原材料"。 配置表1:五类标准登记入口 标准类型 典型内容 内置分类依据 用途场景 国家标准(GB/T) GB/T 4754-2017 国民经济行业分类 ICS国际标准分类 行业分类、行政区划等通用标准 行业标准 GA/T 2000.x 公安信息代码 国家行业标准分类 特定行业垂直领域的编码规范 地方标准 省级/市级数据元标准 地方标准分类 地方政务数据的特定编码 团体标准 行业协会发布的团体规范 ICS分类 行业联盟或协会的补充标准 规范管理 企业内部现有的编码表、命名规范 按业务主题自定义分类 企业自定义的业务规则和惯用编码 操作要点:标准附件支持上传Word或PDF格式的原始文件;支持"代替已有标准"操作,用于标准版本更替场景;标准发布后才能在后续模块(标准制定、关联字典、质量稽核)中被检索和应用。 标准登记之后,真正的"消化"工作在标准解构——将标准文件中的代码集和代码项拆解为平台可识别的结构化数据。 配置表2:标准解构三种方式 方式 适用场景 操作 手工新增 少量代码项(几十条以内) 逐条添加代码值、代码名称,支持模板导入 复制 标准版本更替,大部分代码集不变 将原标准代码集复制到新标准下,再修改差异项 导入 大量代码集或代码项 下载导入模板,按模板填入多个代码集后批量导入 注意:解构后的代码集需要提交审核,审核通过后才可用于后续的数据质量稽核和数据清洗。标识符全局不可重复,否则保存时会报错。 3.2 第二步:数据元制定——定义数据的"身份证" 功能位置:数据治理 → 标准制定 → 数据元制定 数据元(Data Element)是数据的基本单元,相当于数据的"身份证"——规定了它的名字、类型、长度、可以取什么值。每一个需要标准化的数据字段,都需要通过数据元制定功能定义一套完整的属性。这些属性是后续字段映射挂接和质量稽核的依据——标准是否可执行,取决于数据元的定义是否完整。 配置表3:数据元制定的核心属性 配置项 填写内容示例 说明 数据元来源 CRM系统 / 财务部 该数据元最初产生于哪个系统或部门 数据元分类 人员类 / 机构类 / 位置类 / 金融类等 参照GB/T 19488.2-2008,共9大类。如客户姓名归入"人员类",统一社会信用代码归入"机构类" 是否核心数据元 是 / 否 唯一标识关键实体(如客户ID)、直接用于关键决策(如合同金额)、多系统共享引用(如组织机构代码)——满足其一即可标记为核心 约束类型 强制型 / 推荐型 强制型:来源系统必须遵守当前定义;推荐型:可参考执行 业务含义 "自然人在公安户籍部门登记的正式姓名" 用业务语言描述,让非技术人员也能理解这个字段代表什么 归属管理部门 人力资源部 由哪个部门负责维护该数据元的定义和解释(注意:归属部门≠来源部门) 权威系统 HR系统 对该数据元定义、创建、维护和废止负责的系统 标准属性 引用标准规范 / 自定义代码集 / 自定义规范 三选一:①引用外部标准(如GB/T 4754行业分类)②自定义一组代码值(如订单状态DRAFT/SUBMITTED/APPROVED)③自定义格式规范(如"以EH开头+6位数字") 值域范围 1-120 数据元所有可能的、有效的取值集合。如年龄不可能小于0或大于120 数据类型 字符型/数值型/日期型等11种 字符型C、数值型N、货币型Y、日期型D、日期时间型T、逻辑型L、备注型M、通用型G、双精度型B、整型I、浮点型F 数据格式 an5 / n..17,2 / an3..8 an5(aannn)表示定长5个字母数字字符前2字母后3数字;n..17,2表示最长17位小数点后2位 度量单位 CNY / m / kg / pc 为数值型数据提供无歧义的计量标准,如人民币元CNY、米m、千克kg 操作要点:制定后需发布才能生效。平台支持"相似度对比"功能——当新增数据元时,系统自动检索已存在的数据元,避免重复创建相同含义的标准定义。数据元模板设置功能允许用户自定义界面中显示哪些属性字段,适配不同项目的管理粒度要求。 3.3 第三步:代码集维护——让编码变成可读的业务语言 代码集维护是对标准解构产物的管理,也支持自定义组织内部代码集。一个代码集本质上是一组"代码值"与"代码名称"的映射表——把系统里存储的缩略代码翻译为人类可读的业务名称。 配置表4:代码集示例 标准分类 代码集名称 代码值 代码名称 来源 国家标准 性别代码 0 未知的性别 GB/T 2261.1 1 男 2 女 9 未说明的性别 国家标准 国民经济行业分类 A 农、林、牧、渔业 GB/T 4754-2017 自定义 订单状态 DRAFT 草稿 企业自定义 SUBMITTED 已提交 APPROVED 已审批 操作要点:代码集支持导出为SQL脚本和Excel文件两种格式,便于线下评审或导入其他系统。标准检索功能支持跨标准类型搜索(如在一个搜索框里同时查国标和行标),代码集检索可按标准名称或代码集名称快速定位。代码集内的代码项支持批量启用、禁用操作,用于标准迭代期间的分阶段上线。 3.4 第四步:字段映射挂接——让标准"挂"到数据字段上 这是落标的核心动作。前面的标准登记、数据元制定和代码集维护,本质上都属于"纸面标准"的准备——真正让标准和实际数据表发生关联的,是字段映射挂接。 功能位置:数据集成 → 数据源接入 → 数据库设置 → 物理表管理 → 查看表结构 → 关联字典 配置表5:字段映射挂接 配置项 填写内容 说明 目标物理表 customer_info 需要挂接标准的数据表 目标字段 gender 需要标准化的字段(如性别字段) 关联字典 从国标/行标/地标/团标/规范/制定标准中选择 选择已解构的代码集——如选择"性别代码"字典表 关联效果 0→未知, 1→男, 2→女 系统在展示数据时自动将存储值转换为业务名称 关键机制说明: 第一,关联字典后,在数据质量模块的问题数据查看界面中,系统会自动将原始代码值翻译为业务名称。比如gender字段存的是"1",界面展示为"男"——让业务人员也能直接看懂问题数据,而不需要先查代码表。 第二,与关联字典同步的是业务标识字段配置。当把customer_name设为业务标识字段后,问题数据列表中优先展示客户姓名而非一个ID值。这一点在实际使用中非常重要——"客户ID=1024的gender字段不达标"和"XX科技股份有限公司的性别字段不达标",后者让业务部门能够直接认领问题。 第三,需要特别说明的是,关联字典在数据中台上是一个"翻译"层——它改变的是数据在界面上的展示方式,不修改原始存储值。真正的标准合规检查——"这个字段的值到底对不对"——在下一步的质量稽核中执行。 3.5 第五步:质量稽核配置——从"挂接"到"检查" 功能位置:数据治理 → 数据质量 → 评测模型管理 前四步解决了"标准是什么"和"标准挂在哪儿"的问题。第五步解决的是"数据到底有没有遵守标准"——以已定义的数据标准为参照,配置自动化质量稽核规则,持续检查实际数据。 配置表6:引用完整性检查规则配置 配置项 填写内容 说明 评测模型 客户信息质量评测 按业务主题组织规则的容器,一个模型下可包含多条规则 评测对象 customer_info表(治理库DW) 实际数据所在的物理表 规则名称 性别代码引用完整性检查 规则名称建议包含"字段名+检查类型",便于问题追踪时快速定位 规则类型 引用完整性检查 龙石数据中台提供12类质检规则。引用完整性检查专门用于校验字段值是否符合引用的标准代码集 检查字段 gender 需要稽核的字段 引用类型 标准代码集 从国/行/地/团/规范和制定的标准中选择已解构的代码集 键值匹配 代码 / 名称 选择按代码值匹配还是按代码名称匹配,取决于物理表中实际存储的是什么 规则权重 高 影响问题数据的排序和处理优先级 错误描述 "性别字段存在非标准值(当前值'X'不在GB/T 2261.1性别代码标准范围内),影响客户画像分组统计" 用业务语言回答三个问题:①什么问题②影响什么③指向修复方向 修复建议 请在数据标准模块确认标准字典后,在源系统CRM中批量修正 可操作的具体建议,而非"请检查"式的空泛指引 关键特性:引用完整性检查规则直接引用数据标准模块的代码集定义。这一设计的实际价值在于——当国家标准更新(比如新增了一个代码值),质检规则自动同步,不需要手动逐条修改规则。这是标准定义→标准执行的关键联动链路。 配置表7:评测任务调度建议 配置项 推荐值 说明 首次执行 手工触发 先手动跑一次,对着问题清单逐条确认"真问题还是误报",确认无误后再设自动 日常监控 重复执行→按天,每天6:00 每天凌晨自动扫描前一天的增量数据 注意事项 规则配好后先用"抽检"按钮验证 避免半夜定时任务因规则参数错误产生大量误报 四、两种差异化场景的快速展开 以上是企业侧客户主数据的标准落标场景。标准模块的能力不仅适用于企业数据治理,在政务和工业场景中同样有效。 4.1 政务场景:有标贯标,无标立标 某区大数据中心面临"制度规范缺失、标准体系分散、质量问题频发"的局面,数据共享时各部门对同一个字段的理解不一致导致审批流程反复打回。该中心按照"有标贯标、无标立标"的原则推进标准建设:国家标准(GB/T)已有的直接通过标准登记功能引用,不需要重新定义;没有现成标准的,通过数据元制定功能自定义区级数据元标准。经过多轮迭代,共制定200余项区级数据元标准,发布了《数据标准管理实施细则》,沉淀了5,000个质量规则,200个高频数据资源准确率达到100%。 4.2 工业场景:标准先行,集成才有意义 某大型化工企业MES(生产执行系统)、ERP、CRM三套系统物料编码不统一,销售预测与生产排产长期脱节。项目团队做的第一件事不是接数据,而是建立企业级数据标准体系——统一物料、产品、工序等核心业务对象的编码规则和指标口径。通过标准登记导入化工行业标准,结合企业现状通过"规范管理"自定义内部规范,再通过数据元制定为每个字段建立完整的属性定义。标准体系建好后,后续数据集成才有了共同的参照系。实施后库存周转率提升28%,订单交付及时率提升至91%。 五、稽核执行后的实际效果 以客户信息表为例,部署引用完整性检查规则后首次全量扫描,通常会看到类似的问题分布:性别字段可能有800余条含非标准值(如"未知""0""X"),占总量约0.1%;客户等级字段可能有1,200余条不在标准代码集中——ERP存的是"A/B/C",而标准定义了"战略/重点/普通"三种规范写法。 龙石数据中台在多个项目中通过标准自动落标机制,将字段合规率从60%提升到95%以上。核心变化不在于多了几条稽核规则,而在于标准不再只是文档——它变成了每天自动执行的校验逻辑。业务部门新增数据、接入新系统时,标准一致性由平台自动保障,治理团队不需要手工核对每一批新入库的数据。 六、项目避坑:三个最常踩的坑 标准落标操作的路径看似清晰,但在实际项目中仍有几个容易踩进去的坑。 坑一:把标准定义当成标准执行 这是最常见的情况。团队花了两周把国标、行标全部登记完了,数据元也定义了几十个,代码集也导入了。配置完成,文档归档,项目汇报时PPT上写着"数据标准体系已建立"——但实际数据接入后,没有人去配置关联字典,也没有建稽核规则。标准在平台里安静地躺着,和每天跑的数据流完全脱节,除了阶段性汇报时被翻出来引用一下,没有任何实际作用。解法很明确:标准建设必须三步闭环——①定义标准 → ②字段挂接(关联字典) → ③配置稽核规则(引用完整性检查)。三个动作缺一不可。做完②和③之后,标准才真正进入了数据流转的日常轨道。 坑二:标准登记贪多求全 项目初期一口气把能找到的国标、行标、地标全部登记解构了,解构审核周期被拉得很长,治理团队被标准维护工作淹没,真正需要用的那几条标准反而被淹没在海量条目里。标准不在多,在真的有人在用。建议先从当前最影响业务的2-3个核心数据域入手——比如客户域、产品域、订单域。一个域跑通全流程(登记→解构→数据元→挂接→稽核),再扩展下一个域。 坑三:错误描述写成了技术语言 稽核规则的错误描述直接写成"gender字段不满足引用完整性检查,标准代码集GB/T 2261.1无匹配值"。数据治理团队的人看得懂,但业务部门的负责人看不懂——问题流转到业务侧后被搁置,因为没人知道这条报错到底在说什么、影响什么、谁来修。解法是把错误描述翻译成业务语言,明确回答三个问题:什么问题("性别字段存在非标准值")、影响什么("影响客户画像分组统计")、怎么修("请在数据标准模块确认标准字典后,在源系统CRM中批量修正")。一条好的错误描述,应该让业务负责人看到后就知道该找谁、该干什么。 七、小反转:标准落标不是增加工作量,而是降低长期成本 写到这里,可能会有读者产生一个疑问:数据已经在跑了,我还要花时间去定义数据元、配代码集、建稽核规则,这不是在给一个已经运转的系统"加负载"吗? 实际情况正好相反。我们来看一个真实例子:某建筑装饰集团旗下有200余家子公司,同一根"镀锌方管40×60"在三个不同系统里有三种不同的编码和名称。每接入一个新系统、每出一张新报表,治理团队都要做一轮手工的字段映射和数据清洗。标准缺失的代价不是一次性投入,而是持续放大——系统越多、数据量越大,手工对齐的成本越高。这些重复性劳动没有积累效应,不会因为做了十次就自动消失。 标准落标本质上是在降低长期运维成本。标准在前端定义好,后续数据接入时自动对齐;稽核规则在流转中自动执行,问题数据在源头就被标记。治理团队的时间从反复做"字段映射"和"问题追溯"中释放出来,转向真正有价值的资产建设和数据运营。标准落标的投入是一次性的体系建设成本,而它节省的是每个月都在重复发生的运维开销——这才是完整的经济账。 八、常见问题(Q&A) Q1:标准代码集和自定义字典有什么区别?什么时候用哪个? 标准代码集来自国家标准或行业标准等权威来源,通过标准登记→标准解构功能进入平台。自定义字典是组织内部自行定义和维护的代码集(如订单状态、客户等级等业务特定取值)。选择原则很简单:有外部权威标准的字段优先引用标准代码集——既减少维护工作量(标准更新由平台跟踪),也提升数据对外共享时的互认程度。没有现成标准的业务字段,用自定义字典。 Q2:数据标准制定后,多久能在稽核中生效? 数据元制定并发布后,在配置引用完整性检查规则时即可被选中引用。如果已经建立了评测任务并设为定时执行,规则保存后下一次任务调度窗口就会生效——通常是下一个凌晨的6:00。 Q3:稽核规则多久跑一次合适?会不会影响系统性能? 首次建议手工触发跑通验证,确认规则无误后改为按天定时执行(推荐每天凌晨6:00)。质量评测是数据同步之后独立运行的旁路任务,不阻塞数据入库流程。对于千万级以上的大表,建议通过评测对象的过滤条件限定数据范围或分批评测,避免单次任务运行时间过长。 Q4:历史存量数据怎么批量做标准映射? 如果存量数据的字段值与标准代码集不一致(如历史数据中性别存的是"男/女"文本而标准代码集存的是"1/2"编码),建议在数据清洗流程中增加一个转换步骤——通过清洗流程开发组件将历史数据映射到标准代码值上。需要说明的是,关联字典只做"翻译"展示,不修改原始数据存储值,因此不能依赖关联字典来解决存量数据与标准不一致的问题。 Q5:国家标准更新后,已配置的映射和稽核规则会受影响吗? 标准登记模块支持"代替已有标准"操作——新标准发布后,将原标准代码集复制到新标准下,修改差异项,审核通过后新标准生效。引用完整性检查规则如果引用的是旧标准代码集,需要手动更新为新标准代码集版本。这一环节建议在标准变更时同步检查关联的稽核规则,避免旧的质检规则继续按老标准运行。 Q6:编码规则中的流水号达到最大值后会怎样? 龙石数据中台的编码规则管理中设置了流水号最大值。当流水号达到最大值后,会从"流水码起始值"重新开始循环。如果该编码字段设置了不允许重复的约束,重新生成时会报错——此时需要调整最大值范围或重新规划编码规则。 九、落标的终局:从"人工核对"到"自动运转" 数据标准的制定是序曲,落标才是治理的正文。 这一整套操作路径——标准登记→标准制定→字段挂接→质量稽核——背后是龙石数据"理采存管用"方法论中"管数据"环节的核心实践。DCMM(数据管理能力成熟度模型,GB/T 36073-2025)在数据标准能力域中明确区分了"制定标准"和"执行标准"两个层次,而理采存管用把DCMM的评估框架变成了可操作的工程路径:不是把标准写成文档放在共享盘里等待下一次审计,而是让标准在数据流转中每天自动执行。 真正让标准扎根的,从来不是一次性的标准定义工作,而是一个持续运转的机制——标准有地方管理、字段有标准可依、数据有稽核对标、问题有责任闭环。平台让这个机制自动化运转,治理团队从"人工核对"中解脱出来,把精力投入到体系建设和资产运营中去。这才是数据标准落标的终局。 参考来源: DCMM(GB/T 36073-2025)数据管理能力成熟度模型、GB/T 19488.2-2008 电子政务数据元 第2部分:公共数据元目录、GB/T 2261.1 人的性别代码、GB/T 4754-2017 国民经济行业分类
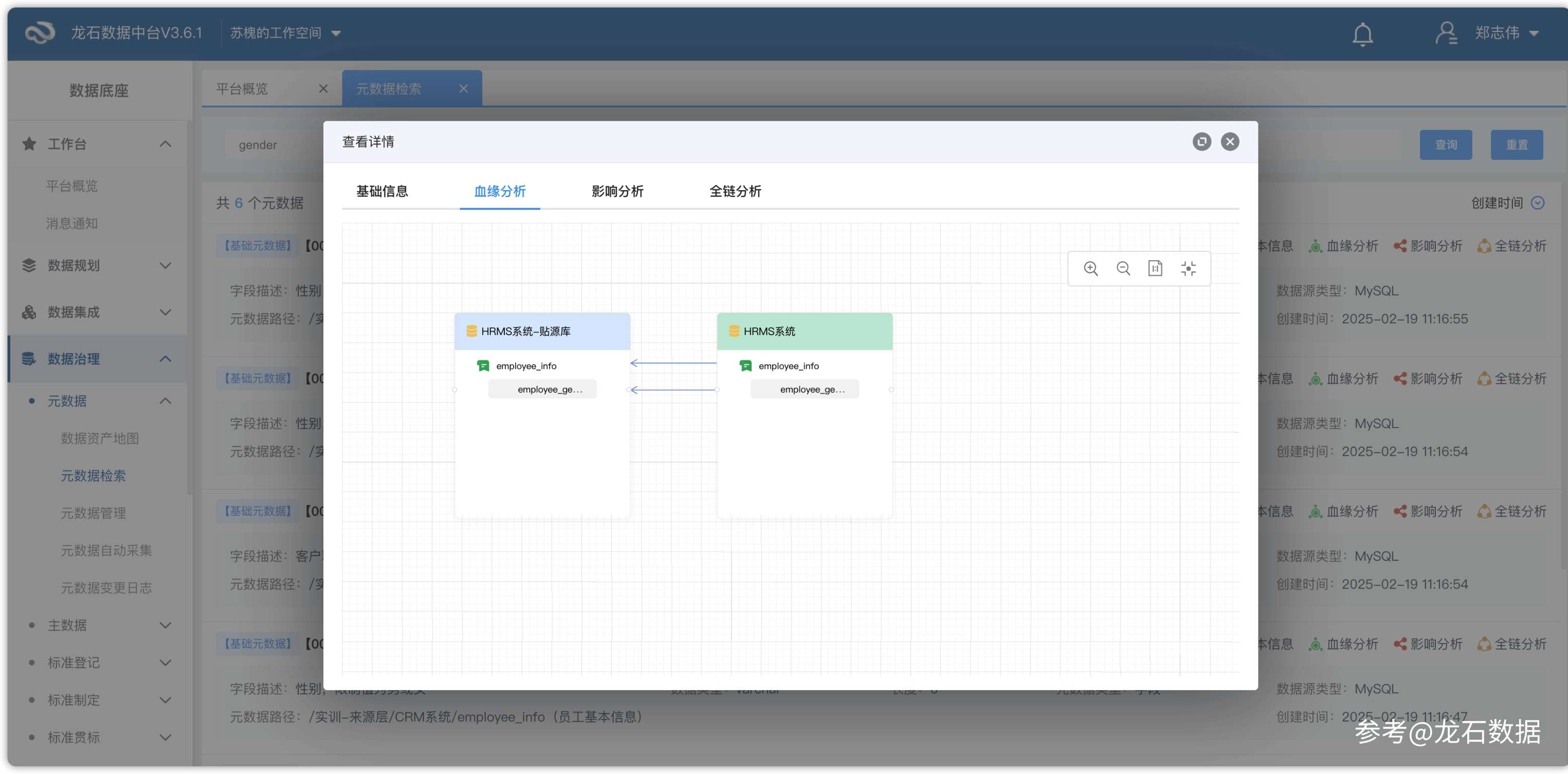
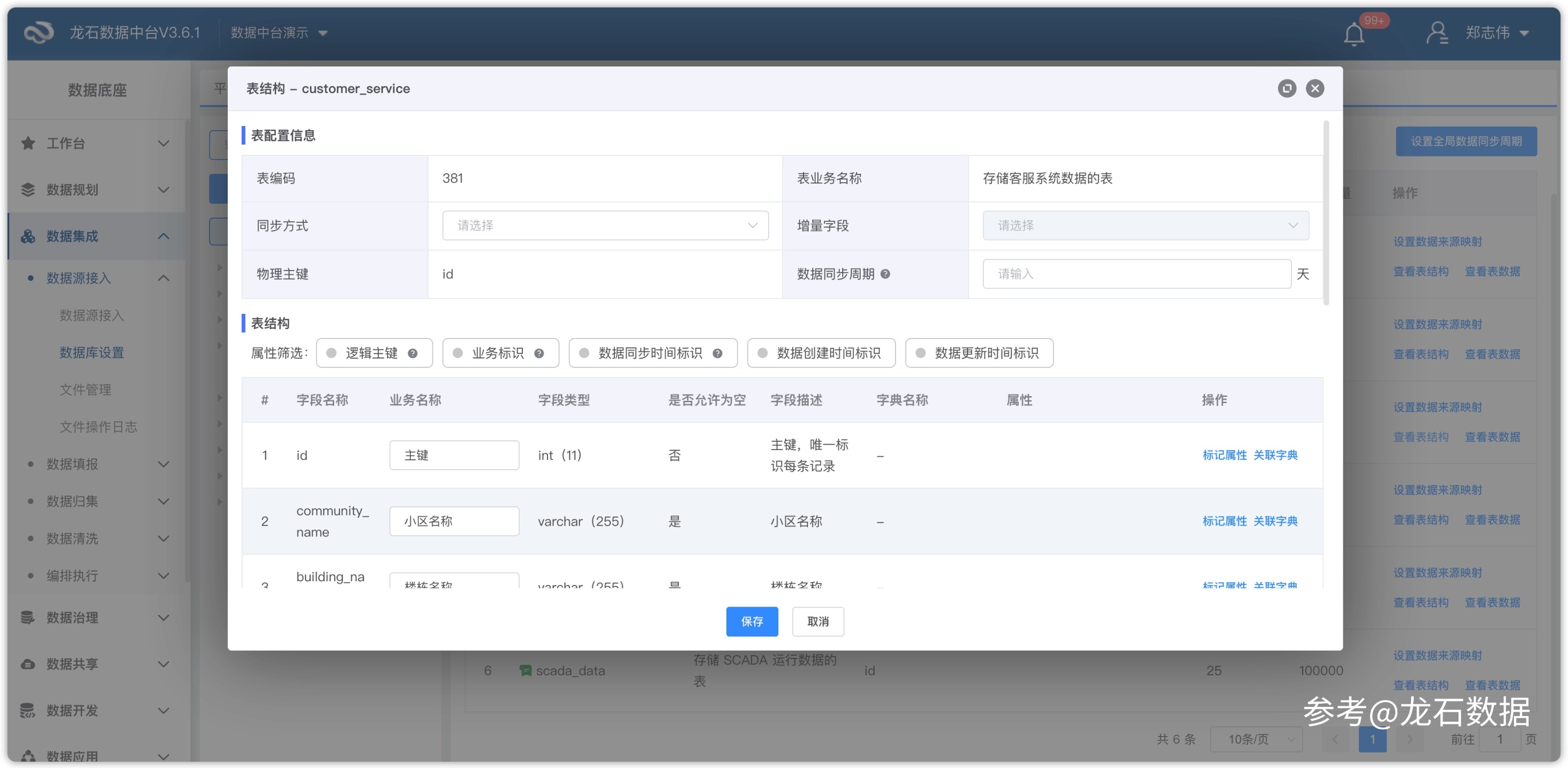
一、场景:几百张表的"黑箱" 周一下午三点,数据工程师老张接到业务部门一个需求:市场部要做一份客户运营分析,需要知道"客户订单金额"这个指标的数据来源——从哪个业务系统出的、经过哪些加工步骤、中间有没有口径变化。听起来是个合理的需求,但老张打开公司的数据中台资产目录后,看到的是几百张以技术命名规则命名的表——ods_sap_mseg_2024、dwd_tms_order_detail、ads_crm_cust_agg——字段注释有一半是空的,没有任何一张图能告诉他"数据从哪里来、经过了什么处理"。 老张没办法,只能手工翻项目文档、翻ETL脚本、在钉钉上问当初做集成的同事。有些表是两年前接的,负责的同事已经转岗,文档也没有及时更新。他花了整整一个下午才勉强梳理出三张核心表的上下游关系,而市场部还在催。这个场景并不罕见——在很多数据团队里,元数据(Metadata,即"关于数据的数据",描述数据从哪里来、是什么含义、经过了哪些处理)长期处于"没人管"的状态,数据中台接了几十个系统之后,只有当初做集成的几个人知道里面到底有什么。业务人员想查数,要么翻文档,要么@数据团队"帮我查一下"。数据资产上线了,但数据资产的"说明书"是缺失的。 这不是工具的问题,是元数据管理没跟上。DAMA(国际数据管理协会)将元数据管理列为数据管理的核心知识领域,而解决问题的第一步,就是让元数据从"手工维护"变成"自动采集"。 二、原理:元数据管理的两个核心能力 元数据管理的目标说起来简单:弄清楚企业有哪些数据、数据在哪里、数据之间是什么关系。但落地到工程层面,它依赖两个核心能力——自动采集和血缘分析。 自动采集是指系统自动抓取数据库表的结构信息:表名、字段名、字段类型、字段长度、主键、索引、分区信息等。传统做法是数据工程师逐表手工录入,一个中型企业动辄几百上千张表,维护成本极高且容易遗漏。如果将元数据比作"数据的地图",自动采集就是让系统代替人工去"测绘"——接入数据源后,系统自动盘点库表结构,不需要人工逐表录入。血缘分析则是追踪数据从源系统到目标指标的完整加工链路——数据从哪个业务系统来、经过了哪些ETL(Extract-Transform-Load,数据抽取转换加载)处理、最终流向了哪个报表或指标。有了血缘,当上游一张表结构变更时,可以在几分钟内定位到所有受影响的治理层表、应用层指标和下游报表,而不是靠经验猜测。 DAMA-DMBOK 2.0(《数据管理知识体系指南》第二版)将元数据管理列为11个知识领域之一,DCMM(数据管理能力成熟度评估模型,国家标准 GB/T 36073-2025)评估也将元数据作为数据架构和数据治理两个能力域的核心考察点。龙石数据中台在"理采存管用"方法论的"管"环节落地元数据管理——数据源接入后通过 AI 自动发现元数据与血缘关系,而非仅依赖手动配置,血缘关系在数据归集任务执行时同步解析,形成全企业的数据地图。 三、分步配置:从接入到血缘分析 下面以典型的业务场景为例,从头到尾走一遍在龙石数据中台中配置元数据自动采集和血缘分析的完整流程。每一步都可以独立执行,读者可以按需跳转到需要的章节。 步骤1:数据源接入——让中台"看见"数据 元数据采集的第一步是让数据中台能够访问到数据源。进入「数据集成 → 数据源接入」,创建数据源分类(如"业务系统数据库"),然后选择数据库类型并填写连接配置。龙石数据中台支持 MySQL、Oracle、SQLServer、PostgreSQL、DM8、Doris、GaussDB 等十余种关系型数据库,以及 FTP 文件服务器、API 接口等多种接入方式。接入成功后,中台即可读取该数据源下所有库表的元数据结构。 配置项 填写内容 说明 数据库名称 如"ERP_生产库" 自定义命名,便于后续识别和管理 数据库类型 MySQL / Oracle / DM8 等 按实际源库类型选择 数据库分层 来源库 SRC 业务系统数据库选"来源库",贴源库 ODS 选"贴源库" 主机地址/端口 如 192.168.1.100:3306 确保中台服务器与数据源网络互通 用户名/密码 数据库只读账号 建议使用只读权限账号,降低安全风险 步骤2:元数据自动采集——系统替你"盘点" 数据源接入后,进入「数据集成 → 数据库设置」,对物理表进行元数据属性配置。这一步的核心动作不是手动录入,而是确认系统自动采集的元数据信息并补充业务属性。中台会自动抓取物理表的结构信息——表名、字段名、字段类型、字段长度、主键等——用户的工作是将这些技术元数据转化为业务人员能理解的"数据地图"。 在物理表管理页面,针对每张需要纳入元数据管理的表进行配置: 配置项 填写内容 说明 同步方式 全量同步 / 增量同步 全量每次同步整表数据;增量需设置增量字段(自增 ID 或时间戳) 增量字段 如 update_time 增量同步的判定依据,用于识别新增或变更的数据行 物理主键 如 order_id 数据库层面强制实施的唯一标识 逻辑主键 如 订单号+行号 业务层面能唯一标识一条记录的一个或多个字段组合 业务标识字段 如 customer_name 具有业务含义的标识字段,用于问题数据追溯时优先展示 数据同步周期 如 1天 数据从产生到入仓的时间周期 关联字典 如 性别代码集 将代码值(M/F)自动转换为业务名称(男/女),从国标、行标、地标、团标或企业规范中选择 对于临时表和日志表这类不需要对外暴露的数据,可以在「表设置」中将其标记为"忽略",元数据模块将不再显示,保持目录清爽。业务人员在资产门户检索时,不会被无关的技术表干扰。 步骤3:数据来源映射——标记"谁的数据" 元数据的价值不仅要回答"是什么数据",还要回答"谁的数据"。在「数据库设置 → 设置数据来源映射」中,将每张物理表关联到具体的来源部门。全表数据来自单一部门的选"全表映射",直接指定归属部门;一张表包含多个部门数据的选"字段映射",通过来源标识字段(如 dept_code)与组织架构中的部门进行关联匹配。 这一层映射做完后,数据质量模块就能按部门派发问题数据整改工单,数据资产管理也能按部门统计归集情况。数据源接入、元数据采集、来源映射三步走完,一张表的基本元数据画像就建立起来了。 步骤4:设置采集调度策略 元数据采集不是一次性的工作。业务系统的表结构会持续变化——新增字段、调整表结构、上线新模块——如果只跑一次采集就停下来,元数据很快就会过时。在数据归集任务配置中设置执行策略,让元数据保持持续更新。 配置项 填写内容 说明 执行方式 重复执行 首次验证建议用手工触发,验证链路跑通后切换为重复执行 定时类型 每天 02:00 避开业务高峰期,减少对源系统的影响 失败后禁用该任务 不勾选 允许失败后按策略重试,避免因一次异常就停止采集 任务优先级 5 数值越大优先级越高,多任务同时触发时按优先级调度 建议先用"手工触发"跑一次验证采集链路是否通畅,确认元数据采集结果正确后再切换为"重复执行-每日"。对于元数据变更敏感的场景,平台还支持物理模型检测功能——每天凌晨自动比对数据库实际元数据与物理模型的一致性,差异项以红色标注,确保元数据不会悄然过时。 步骤5:查看血缘关系——数据从哪来、到哪去 元数据采集完成后,进入「数据治理 → 元数据管理」,可查看已入库表的元数据详情以及数据血缘关系。血缘关系的维护存在两种方式:第一种是自动解析——如果通过平台来承载数据的全生命周期管理,包括集成、归集、共享等环节,数据中台在执行这些任务时会自动记录各环节的输入输出关系,形成从源系统到贴源层(ODS,Operational Data Store,操作数据存储层)、治理层(DW,Data Warehouse)、应用层(ADS,Application Data Service)的血缘图谱。第二种是手动维护——对于平台外完成的操作(例如通过外部脚本直接写入目标库、或在平台尚未覆盖的环节进行了数据加工),可以在元数据管理界面手动添加节点和连线来补全血缘关系,确保数据地图的完整性。 血缘分析的价值不止于"看",更在于"影响分析"。当上游某张源表的字段发生变更时,通过血缘图可以快速定位到所有受影响的治理层表、应用层指标和下游报表,把变更影响评估从手工翻脚本的"天级"缩短到分钟级。 四、多场景展开 场景1:新系统接入后的元数据批量补采 企业上线了新的 ERP 模块,一下子多了几十张表需要纳入管理。在「多表归集管理」中,可以一次性勾选所有新表,设置好来源映射和同步周期,系统自动完成元数据的批量补采。配合「数据库设置」中的"表设置"功能,将临时表和日志表标记为"忽略",确保元数据目录保持清爽,业务人员检索时不会被无关数据干扰。从几十张表的手工录入到一键批量补采,元数据管理的效率提升是数量级的。 场景2:异构数据库统一元数据管理 业务系统跑在 MySQL 上,数据仓库用 Doris,数据共享走 API——三套不同的技术栈。龙石数据中台支持十余种数据库类型的统一接入,所有接入的数据源在元数据管理模块中按统一的元数据模型进行管理。无论是 MySQL 的 varchar(255) 还是 Doris 的 VARCHAR(255),在元数据视图中都被归一化为"字符型、长度 255"。技术异构被元数据层屏蔽,分析人员不需要关心底层数据库是什么——这种能力在 DCMM 评估中对应数据架构域的"元数据管理"能力项,是企业数据管理成熟度的重要衡量指标。 五、执行与结果验证 完成配置后,从以下维度验证元数据管理的效果: 元数据完整性检查。进入「数据治理 → 元数据管理」,检查新接入表的元数据信息是否完整——表名、字段名、字段类型、字段长度、主键、注释是否均已采集到位。如果发现缺失项,返回「数据库设置」检查对应表的同步配置。 血缘关系验证。在元数据管理的血缘视图中,确认从源系统到中台各层的数据流向是否正确显示。选择一个字段追溯其上下游关系,验证血缘链条的完整性。 业务可用性测试。进入「数据资产 → 资源目录」,以业务名称(而非技术表名)进行搜索,确认业务人员能否找到对应的数据资产。如果搜索不到,需要检查「数据库设置」中的业务标识字段和关联字典是否已正确配置。 变更同步验证。在源库中新增一个测试字段,等待下一次定时采集任务执行完成后,刷新元数据管理页面,确认该字段已自动出现在元数据清单中。这一验证步骤对于周期性调度的稳定性至关重要。 江苏某流程制造企业(精细化工行业)在实施龙石数据中台后,MES(制造执行系统)中的批次数据、DCS(分布式控制系统)中的工艺参数数据统一接入,元数据自动采集和血缘分析——遵循 DAMA 数据管理知识体系(DMBOK 2.0)的最佳实践——让数据"从哪里来、经过了什么处理"一目了然。上海某大型化工企业通过数据中台建设统一物料编码、打通 OT(运营技术)与 IT 数据后,数据管理部实现了常态化元数据管理,库存周转率提升 28%。 六、避坑指南 在实际项目中,元数据管理常见的三个坑往往不是配置层面的问题,而是认知层面的偏差。 坑一:以为元数据采集一次性跑完就万事大吉。 错误假设:数据源接入后跑一次元数据采集,后续就不用管了。真实后果:业务系统每天都在变化——新增字段、调整表结构、上线新模块——三个月后元数据就过时了,业务人员又回到翻文档问同事的老路上。正确做法:将元数据采集任务配置为每日定时执行,并开启任务监控——执行失败或采集数据量异常时自动通知责任人,确保元数据始终与生产库保持一致。 坑二:只配技术元数据不管业务元数据。 错误假设:元数据管理就是记录表名、字段名、字段类型,技术属性齐全就够了。真实后果:业务人员打开资产目录看到的全是 ods_sap_mseg_2024 这类技术表名和 M/F 这类代码值,完全看不懂,元数据管理变成 IT 部门的自娱自乐。正确做法:在「数据库设置」中为每张表配置业务名称替代技术表名,为关键字段关联业务字典将代码值转换为业务中文,设置业务标识字段标注哪些字段有业务含义。业务人员看得懂的元数据才有使用价值。 坑三:元数据管理和数据标准各自为政。 错误假设:元数据管"有什么",数据标准管"应该是什么",两套独立运行。真实后果:元数据显示字段名叫 user_name,数据标准定义的是 customer_name,两边打架。数据质量检查时发现字段名不匹配,不知道该以哪个为准。正确做法:在字段映射环节引用已定义的数据标准,元数据自动校验字段是否合规,标准变更后元数据视图同步刷新,确保元数据和数据标准始终保持一致。 七、小反转:真正的问题不在配置层面 表面上看,元数据管理是一个配置问题——数据源接入、字段映射、血缘解析、调度策略配好就行。但在多个项目现场我们发现:真正让元数据管理失效的,不是配置没做到位,而是做完配置之后没有人持续用。很多企业把元数据当作 IT 部门的内部工作台账——配完了、截图留存了、汇报材料里有这一页了,就算完成了。 龙石的实践表明:元数据的价值释放不在"配好",而在"用好"。元数据不是给 IT 部门看的目录,而是让业务人员能自主找数、用数的"数据地图"。当业务部门提需求时,不是@数据团队"帮我查一下",而是自己打开资产门户搜索、浏览、申请——元数据管理才算真正落地。从"没人管"到"有人管",只完成了第一步;从"有人管"到"有人用",才是价值兑现。 八、常见问题(Q&A) Q1:元数据采集需要手动逐表录入吗? 不需要。龙石数据中台在数据源接入后自动采集库表结构和字段信息,技术元数据由系统自动抓取。用户只需要补充业务属性——业务名称、关联字典、来源部门。批量补采可通过多表归集一键勾选多张表,不需要逐表手工录入。 Q2:血缘分析能跨数据库类型追踪吗? 能。从 MySQL 源表到贴源层 Doris、治理层、应用层,不同数据库类型之间的数据流转链路都会被记录。前提是数据归集任务通过中台执行——中台在任务流转过程中记录每个环节的输入输出关系。目前 API 服务暂不支持血缘追踪,对于以 API 形式对外提供的数据服务,其下游消费链路无法自动纳入血缘图谱,需要手动维护。 Q3:源表结构变了,元数据会自动更新吗? 不会全自动实时感知,但可以通过定时调度策略保持同步。建议将元数据采集任务设为每日定时执行,任务跑完后元数据同步刷新。对于元数据变更敏感的场景,可利用物理模型检测功能自动比对数据库元数据与物理模型的一致性,差异项红色标注。 Q4:技术元数据怎么变成业务人员能看懂的? 在「数据库设置 → 物理表管理」中为每张物理表设置"业务名称"替代技术表名,为字段关联"业务字典"将代码值转换为业务名称,设置"业务标识字段"标注有业务含义的字段。做好这些映射后,业务人员在资产门户搜索时看到的是业务语言而非技术术语。 Q5:元数据管理和数据资产管理是什么关系? 元数据管理是数据资产管理的基础。元数据告诉用户"有哪些数据、数据在哪里、数据是什么意思",资产目录基于元数据组织数据的业务化展示。龙石数据中台在这两层之间实现了联动——元数据更新后资产目录自动刷新,不需要人工维护两份信息。 Q6:生产环境历史数据量大,首次全量元数据采集会不会影响业务系统? 建议在业务低峰期(如凌晨)执行首次全量采集,同时调整数据源连接池参数控制并发读取量,降低对源系统的压力。首次采集完成后,后续增量采集只处理新增和变更的表与字段,对源系统基本无影响。 九、方法论收尾 元数据管理是 DCMM 评估中数据架构和数据治理两个能力域的核心考察点,也是 DAMA-DMBOK 2.0 定义的 11 个知识领域之一。龙石数据中台通过"理采存管用"方法论的"管"环节,将元数据管理从文档里的理想落地为系统里的动作——自动采集让元数据不再依赖人工录入,血缘分析让数据链路从黑箱变成地图,技术元数据到业务元数据的映射让业务人员也能看懂自己的数据资产。 数据治理的终局不是供应商持续驻场,而是企业自己具备持续管理元数据的能力。从元数据"没人管"到"系统自动管"再到"人用得上",每一次实操演练都是向这个目标迈出的一步。 参考来源 [1] DAMA International,《DAMA数据管理知识体系指南》(DAMA-DMBOK 2.0),2017 [2] GB/T 36073-2025《数据管理能力成熟度评估模型》(DCMM 2.0),国家标准化管理委员会 [3] 中国信通院,《数据治理产业图谱 3.0》,2024
一、周五下午的同步困局 周五下午五点半,运维群里弹出一条消息:"今晚Oracle的几张表要同步到Doris,MySQL的订单表也要增量更新到数据仓库,SQL Server那边CRM的客户表还得全量刷一遍——哪位大佬帮我看看脚本怎么改?"发消息的老张已经在工位上坐了四十分钟,面前开着五个SSH终端窗口,每个窗口对应一套数据库的同步脚本。MySQL的订单库刚刚加了一个"优惠券类型"字段,对应的同步脚本需要同步修改SELECT列清单和INSERT字段映射;Oracle财务库的JDBC(Java数据库连接)驱动版本从8.0.28升到了8.0.33,连接池参数需要重新调试;SQL Server的CRM库换了一台新服务器,IP地址变了,六个脚本里散落的连接串都要逐一更新——老张粗略估算了一下,这一轮改完少说两小时,改完还得逐个试跑验证,今晚大概率要熬到九点以后。 这不是老张一个人的困境。他所在的公司数据架构是典型的"烟囱式"演进结果:MySQL存订单和交易流水,Oracle跑财务核算和总账,SQL Server管CRM(客户关系管理)系统,MongoDB存用户行为日志和点击流,PostgreSQL做报表中间库和临时分析表。每套数据库各自有一套同步脚本,累计超过2000行,有的用Python写的定时任务,有的是Shell脚本拼SQL,还有两套是前任运维留下的Kettle作业。每次上游业务系统加字段、换数据库版本、调连接池参数,运维就得逐套修改脚本——同样的问题在不同的脚本里反复出现,但每次都得从头排查一遍。 更让老张头疼的是增量同步。订单表有update_time可以做时间戳增量,用户行为日志表只有自增ID没有时间字段,而CRM的客户表连增量字段都没有——千万级的大表每次全量跑两个小时,还经常因为网络波动超时断开,断了就得从头再来。三套脚本、三种逻辑,没有任何统一的监控和告警,每次出了问题都是下游用数方先发现:"今天的报表数据没更新,帮忙看看同步是不是挂了?" 这不是个别现象。在多源异构数据库普遍存在的企业环境中,统一归集和增量同步是数据团队的刚需痛点,也是数据中台建设绕不过去的第一道坎。部分数据中台产品如龙石数据中台,其集成模块为这类场景提供了系统化方案——一个平台纳管全部数据源,同一套配置模型覆盖全量同步和增量时间戳同步。下面从实际操作出发,完整演示从数据源接入到增量同步配置的全过程。 二、原理小段:多源异构归集的"统一语言" 龙石数据中台遵循"理采存管用"五阶段方法论,数据集成对应"采"——聚数据的核心环节。面对MySQL、Oracle、SQL Server、MongoDB等多源异构数据库,中台的解决思路不是为每种数据库单独开发一套适配器,而是建立"数据源接入→同步策略→归集执行"三层抽象,将异构数据源的差异封装在统一的配置模型中。 第一层是数据源接入抽象。无论底层是关系型数据库还是NoSQL文档数据库,在平台上都统一抽象为主机地址、端口、数据库名称、用户、口令五个核心要素,再加上各数据库类型特有的属性参数——如关系型数据库的JDBC连接池配置、MongoDB的读选项和连接串格式。这层抽象让运维人员用同一套操作逻辑管理全部数据源,而不是在MySQL客户端、Oracle SQL Developer、MongoDB Compass之间来回切换。 第二层是同步策略抽象。全量同步、增量时间戳同步、增量日志同步(CDC,Change Data Capture,变更数据捕获)三种策略,在关系库表输入组件中通过"是否增量"一个开关加上增量字段、目标字段、偏移量三个参数统一配置,不需要为每种策略编写不同的脚本逻辑。平台在底层自动将配置翻译为对应数据库的SQL查询或日志解析指令。 第三层是归集执行抽象。批量归集(拖拽式画布,适合单表精细化处理)和多表归集(向导式勾选,适合多张结构类似的表批量同步)两种方式,共享同一套数据源接入体系和同步策略配置模型。运维不需要关心底层是MySQL的JDBC连接还是Oracle的OCI驱动,只要在画布上拖拽组件、配置参数、连线执行即可。 值得强调的是,龙石数据中台的集成模块在设计上将治理能力前置嵌入集成流程:数据源接入时同步创建元数据采集任务,字段映射时可引用平台已定义的数据标准字典,任务执行完成后自动触发旁路质量校验——数据正常入库,质量评测并行扫描,不给业务添堵。这种"集成即治理"的设计理念,让数据在进入中台的那一刻就开始被管理,而不是等数据堆成山再事后补救。 三、分步配置:数据源接入与增量同步 下面以一家典型企业的实际数据环境为例,演示从数据源接入到增量同步任务配置的完整操作过程。本文假设读者已有龙石数据中台平台的访问权限和相应模块的操作授权。 第一步:数据源接入——连接四种典型异构数据库 操作入口:登录平台后,进入「数据集成 → 数据源接入 → 数据源接入」,点击「新增」按钮进入数据源配置页面。 新增数据源时,先填写基础信息。下表为主配置项说明: 配置项 填写内容 说明 数据库名称 自定义,如"MySQL-订单库""Oracle-财务库" 命名建议包含数据库类型和业务含义,便于后续在组件中快速识别 数据库类型 下拉选择 平台覆盖关系型(MySQL/Oracle/SQL Server/PostgreSQL)、NoSQL(MongoDB)、国产数据库(达梦DM8/Doris/Vastbase G100/GaussDB/KingbaseES V8/GBase 8a)、大数据(Hive/HBase/Hadoop HDFS/Trino)、文件(FTP/FTPS)、对象存储(EDS)、消息队列(Kafka)、API等多类数据源 分类 选择已有分类 可按业务域、部门、数据分层等维度建立分类体系 部门 选择组织部门 来源库归属对应业务部门,治理库通常归属信息技术部门 数据库分层 来源库SRC / 贴源库ODS / 治理库DW / 应用库ADS / 共享库DS 业务系统的原始数据库选择"来源库SRC" 数据库分层是数据中台建设中的重要概念。引用DCMM 2.0(GB/T 36073-2025)数据架构域的管理要求,分层设计有助于明确数据流转路径和职责边界。各层用途如下: 分层 用途 数据来源 来源库SRC 业务系统的原始数据库,保持源端结构不变 业务系统MySQL/Oracle/SQL Server等 贴源库ODS 原始数据暂存区,结构与来源库一致,作为数据入仓的第一站 从SRC同步而来 治理库DW(Data Warehouse) 经过清洗、标准化、建模后的数据仓库,是企业级统一数据视图 从ODS清洗转换而来 应用库ADS(Application Data Store) 面向具体业务场景的数据集市,如营销数据集市、财务数据集市 从DW聚合计算而来 共享库DS(Data Sharing) 对外提供数据共享服务的出口层 从DW/ADS按需提取 接下来配置连接信息。以下为四种典型异构数据库的连接参数对照表: 配置项 MySQL Oracle SQL Server MongoDB 主机地址 192.168.1.100 192.168.1.101 192.168.1.102 192.168.1.103 端口 3306 1521 1433 27017 数据库名称 order_db ORCL(SID)或ServiceName CRM_DB order_logs 用户 sync_user sync_user sync_user sync_user 口令 **** **** **** **** 属性(扩展) JDBC连接池参数(如initialSize、maxActive) 连接方式选择SID或ServiceName 实例名(instanceName) 连接串格式:mongodb:// 连接池、游标批量读取行数等参数一般使用默认值即可,如有特殊需求可参考对应数据库的官方文档调优。数据源需确保与平台管理端服务器和归集执行机器之间的网络互通,防火墙规则需提前放行对应端口。 第二步:增量同步配置核心参数 数据源接入完成后,进入增量同步的核心配置环节。在批量归集流程开发中,拖入「关系库表输入」组件,双击打开属性面板,勾选「是否增量」后展开以下配置参数: 配置项 可选值 说明 增量字段 来源表中的数值型或时间戳字段 如自增主键 id(数值增量)或更新时间戳 update_time(时间戳增量) 增量方式 数值增量 / 时间戳增量 需与增量字段类型保持一致:数值型字段选数值增量,时间戳型字段选时间戳增量 目标库 选择已接入的目标库 用于存储增量比较基准的目标数据库连接 目标表 选择目标表 增量比较的参照表,系统将读取该表中对应字段的最大值作为基准 目标表字段 选择目标表的对应字段 与来源增量字段进行比较的字段,通常与来源增量字段同名 时间戳偏移量 秒(整数) 仅在时间戳增量模式下生效。系统以"增量字段最大值 - 偏移量"为基准与目标表比较,用于解决时间精度和系统延迟导致的数据遗漏 增量逻辑的底层执行方式如下: 数值增量:每次任务执行时,系统先从目标表读取对应字段的最大值(如 max(id)),然后在来源库执行 SELECT * FROM source_table WHERE id > {max_id},仅抽取主键大于目标表最大值的记录。这种方式适用于自增主键或严格单调递增的数值序列字段。 时间戳增量:系统以目标表增量字段的最大时间戳为基准,在来源库执行 SELECT * FROM source_table WHERE update_time >= '{max_time}'。需注意,这里使用"大于等于"而非"大于",原因在避坑指南中详述。 时间戳偏移量:若偏移量设置为10秒,则实际比较基准为 max(update_time) - 10秒。这意味着每次抽取的范围会向前多覆盖10秒的数据,确保上一轮因时间精度差异或系统延迟落在边界上的数据在下一轮被重新包含。多覆盖的数据在目标库做插入更新(Upsert)时会自动覆盖,不会产生重复。 第三步:批量归集流程开发——拖拽式画布设计 批量归集流程开发是龙石数据中台集成模块的核心操作界面,采用拖拽式画布设计,非技术人员经过简单培训即可上手。画布分为五个功能区:左侧为组件库,包含输入、输出、转换、脚本、文件传输、其他六类组件;上部为工具栏,提供撤销、重做、参数设置、保存、运行、回放、终止、查看日志、调试、预览数据等操作入口;中间为拖拽设计区域,通过组件间的连线控制数据流向;右侧为属性面板,双击组件弹出,用于配置该组件的详细参数;下部为运行日志区,实时展示任务执行的SQL语句、数据量和异常信息。 以下为构建一个典型增量同步流程的操作步骤: 从左侧组件库「输入」类中拖入「关系库表输入」组件到画布,双击打开属性面板,选择MySQL订单库数据源,填写SQL查询语句或直接勾选数据库表,然后勾选「是否增量」并配置增量字段、增量方式、目标库字段和时间戳偏移量(参数说明见上一步配置表)。 从「转换」类中拖入「字段选择」组件,将关系库表输入组件连线到字段选择组件。在字段选择属性面板中,勾选需要同步的字段、重命名字段(如将来源库的 cust_nm 映射为目标库的 customer_name)、调整字段类型和长度(如将MySQL的 varchar(100) 扩展为Doris的 varchar(300) 以容纳UTF-8中文)。 可选步骤:从「转换」类中拖入「数据清洗转换」组件,配置清洗规则。例如,对手机号字段应用正则表达式 ^1[3-9]\d{9}$ 进行格式校验,或使用EL表达式(Expression Language,表达式语言)进行字段值转换,如 ${field:phone.replaceAll("[-\\s]","")} 去除手机号中的分隔符和空格。 可选步骤:从「转换」类中拖入「数据过滤」组件,配置SQL过滤条件,如 status = 'active' AND created_date >= '2025-01-01',仅同步活跃状态且本年度创建的订单记录。 从「输出」类中拖入「关系库表输出」组件,连接数据过滤(或字段选择)组件的输出端。在属性面板中选择Doris目标库,指定目标表名,系统根据字段名自动匹配来源字段与目标字段的映射关系,用户确认或手工调整后保存。 点击工具栏「保存」按钮保存流程,点击「运行」执行一次以验证流程正确性,在下方日志区查看SQL执行情况和同步数据量。确认无误后,进入「批量归集任务管理」页面,为该流程配置定时执行策略:执行方式支持手工触发、重复执行(按天/周/月间隔)、Cron表达式(如 0 2 * * * 表示每天凌晨2点执行)、定时一次四种模式。 画布中的连线模式支持分发和复制两种:分发模式将上游数据随机分流到多个下游组件(用于并行处理分片数据),复制模式将上游数据全量拷贝给每个下游组件(用于同时写入多个目标库)。双击连线可以切换生效/失效状态,方便调试时临时断开某个分支。 四、执行与结果验证:使用对账功能确认同步结果 任务运行成功后,可用龙石数据中台「数据集成 → 对账」功能验证同步结果。对账功能支持来源库与目标库的数据量比对、字段值抽样核对,快速确认同步是否完整。选择对应的集成任务和源表/目标表,系统自动执行行数对比、抽样校验,并生成对账报告。对于增量同步任务,还可以限定增量时间范围,仅对账本次新增的数据。 对账通过后,集成任务执行期间平台已自动完成元数据采集,进入「数据治理 → 元数据管理」可查看新入库表的字段列表和血缘关系。资产目录也会同步更新,对应资源状态标记为就绪。 五、项目实战避坑指南 在实际项目中,多源异构数据库的增量同步看似流程清晰,但处处藏着细节陷阱。以下三个坑来自真实项目的实战经验。 坑一:时间戳增量数据遗漏——偏移量不是可有可无 一种常见的错误认知是:增量字段选了 update_time,每次取 max(target.update_time) 之后的数据,逻辑上不会遗漏。实际情况是,MySQL的 update_time 精度为秒级,业务系统在同一秒内可能有多条写入操作。当增量任务恰好在某秒的第500毫秒执行时,该秒内最后写入的几条记录的 update_time 等于当前秒的整秒值——系统将它们纳入了本轮抽取。但下一轮任务执行时,目标库的 max(update_time) 已经等于这一秒,这些记录的 update_time 既不大于也不小于目标时间,在"大于"比较逻辑下被跳过,造成永久性遗漏。真实的后果是:任务持续运行两周后,运维偶然发现目标库比来源库少了数百条数据,且无法通过增量任务自动修复,需要手动补数。 正确的做法是:在时间戳增量配置中设置「时间戳偏移量」,建议值10-30秒。偏移量让系统以 max(update_time) - 偏移量 为实际比较基准,每次向前多覆盖一段数据。上一轮边界上的数据在本轮会被重新抽取,配合目标库的插入更新(Upsert)写入方式,重复数据自动覆盖,不会产生数据冗余。偏移量是用可控的少量重复计算换取零遗漏的数据可靠性保障。 坑二:CDC对源库是"隐形杀手"——不是所有场景都适合 一种常见的错误假设是:CDC实时同步比批量增量"更先进",既然平台支持,就应该用上。实际情况是,MySQL的Binlog是全量记录所有数据变更的,当一个批量更新事务涉及百万行数据时,Binlog在短时间内产生数百MB的日志数据。这些日志数据需要实时传输到Kafka、再由Debezium解析、最终写入目标库——整个过程持续消耗源库的CPU、内存和网络带宽。真实的后果是:业务高峰期,MySQL的查询响应时间从50毫秒飙升到500毫秒以上,业务系统出现大面积超时告警,运维紧急停掉CDC任务后才恢复正常。 正确做法是:严格评估CDC的必要性。功能文档明确建议,除了"下游实时性要求秒级通知"和"千万级以上且无增量标识字段"两种情况,其他场景优先采用批量归集的时间戳增量。如果必须使用CDC,建议采用"先批量全量初始化,再CDC增量续传"的策略——先通过批量归集完成全量数据入仓(这个过程可控、可限速),再启动CDC捕获增量变更,避免CDC承担大规模历史数据的传输压力。同时设置监控告警,一旦源库负载超过阈值,自动降级为批量增量模式。 坑三:异构数据库字段长度——字符≠字节 一种常见的错误操作是:在自动建表时不设置字段长度扩展倍数,让系统按来源库字段长度1:1创建目标表。实际情况是,不同数据库对 varchar 的长度单位定义不同。MySQL的 varchar(100) 表示最多存储100个字符,Oracle的 varchar2(100) 默认表示100个字节(BYTE),Doris中 varchar(100) 也表示100个字节。UTF-8编码下,一个中文字符占3个字节,一个包含100个中文字符的字段在MySQL中恰好存下(100字符 = 300字节),但同步到Oracle或Doris的100字节字段时只能存下约33个中文字符,多余数据直接报错 value too large 并丢弃。真实的后果是:同步任务在跑了十几万行数据后突然中断,日志里满是字段超长错误,已入库的数据中大量中文字段被截断,需要清空目标表、调整字段长度后重新同步。 正确做法是:自动建表时根据业务数据特征设置字段长度扩展倍数。中文为主的字段(如客户名称、地址、商品描述)建议扩展3倍;纯英文和数字的字段保持1倍即可。在批量归集流程开发中,通过字段选择组件手工调整目标字段长度,将来源库的 varchar(100) 在目标库明确设置为 varchar(300)。上线前用包含最长实际值的样本数据做一次全链路同步测试,验证字段长度是否满足业务需求。 六、小反转:集成不是终点,治理刚起步 很多团队将数据集成理解为"把数据搬过去就完了"——源库的数据进了目标库,任务就完成了。但数据工作的现实是,搬完数据只是开始。 龙石数据中台在集成过程中同步完成了一些治理前置动作:数据源接入时可同步创建元数据采集任务,后续无需手工维护表结构信息;字段映射时可参考平台已定义的数据标准字典来统一口径。集成任务完成后,可以在数据质量模块中配置旁路监测——让质量评测在数据入库后并行扫描,发现问题打标记、生成整改工单,不阻塞正常入库。这种方式和"嵌入集成链路校验"有本质区别:嵌入校验一旦规则配置过严,整条数据链路就会中断;旁路监测则让数据正常入库,质量问题走整改流程闭环,在可用性和质量管控之间取得平衡。数据集成不是终点,它只是让数据被看见、被管理、被使用的起点。 七、常见问题 Q&A Q1:增量时间戳什么情况下用,有什么前置条件? 来源表需要有 update_time 更新时间戳字段或自增主键ID时使用,配置简单,对源库无额外负载,满足大多数业务场景。 Q2:多张异构数据库的表能不能整合到一个任务里? 不能直接在单个任务中跨数据库归集——一个批量归集流程的「关系库表输入」组件只能绑定一个数据源。但可以通过编排执行实现端到端串联:分别创建 MySQL→ODS、Oracle→ODS、MongoDB→ODS 的归集任务,然后在编排任务管理中将它们设置为并行或串行执行。 Q3:增量同步中断了怎么恢复? 批量归集流程开发中,工具栏提供「回放」功能,可重新触发最近一次执行。建议所有生产任务都配置监控告警,一旦任务失败或逾期未执行,通过站内消息、邮件或短信第一时间通知运维人员。 Q4:MongoDB的嵌套文档怎么同步到关系型数据库? 在批量归集流程开发中使用「MongoDB输入」组件,有两种处理路径。路径一:使用「输出字段表达式(JSON)」中的 JSON Path 语法提取,例如 $.user.name 提取用户名称。路径二:勾选「输出单一JSON字段」,将整个 MongoDB 文档序列化为一个 JSON 字符串写入目标关系库的文本列,后续在数据消费层按需解析。 Q5:集成任务怎么和质量管理联动? 在「数据质量」模块中创建质量评测模型后,将其关联到对应的集成任务。集成任务执行完成后,可以在质量模块中触发评测——平台以旁路模式对入库数据进行并行扫描,发现问题数据入问题库、生成整改工单,数据本身正常入库不受影响。 八、收尾:让数据流动不再成为瓶颈 从手工维护五六套异构数据库的同步脚本、每次修改字段和连接参数都需要逐个脚本排查,到一个平台纳管全部数据源、统一通过增量时间戳配置完成多源数据的增量归集——这个转变的本质不是工具的替换,而是数据工程能力的体系化。 龙石数据中台的"理采存管用"五阶段方法论为这体系化提供了清晰路径:理,摸清家底,通过数据源接入和元数据采集,全面盘点组织的数据资产分布;采,本文的核心——多源异构数据统一归集,通过增量时间戳等策略实现高效同步;存,分层建模(ODS→DW→ADS),让数据从贴源、到治理、到应用层层递进;管,将治理能力前置嵌入集成流程,元数据采集、数据标准参考、质量旁路监测协同运作;用,通过资产目录更新和数据共享服务,让归集来的数据被下游用户快速发现和使用。 在苏州某面料贸易企业的实践中,企业原本依赖多套定制接口对接ERP(企业资源计划系统)、PLM(产品生命周期管理系统)、MES(制造执行系统)和仓储系统,跨系统数据交互依赖人工操作或协调开发。部署数据集成平台后,各业务系统之间数据自动流转,新应用的上线周期大幅缩短。广东某质检院整合核心业务系统、OA(办公自动化系统)、官网及省级和国家抽检平台等多套异构系统,数据标准统一后检测效率显著提升,官网数据公示不再因手工同步而延迟。江苏某211大学的智慧校园项目中,数据底座利用批量归集将分散在各院系、部处的异构数据规范高效入仓,跨部门的数据申请从"天/周级"缩减到"分钟级",师生数据服务体验显著改善。 数据集成的价值,不在技术栈的复杂度,而在操作的简洁度。让多源异构数据顺畅地流动起来,第一步就是把集成本身从瓶颈变成基础设施。 参考来源: GB/T 36073-2025《数据管理能力成熟度评估模型》(DCMM 2.0),国家市场监督管理总局、国家标准化管理委员会,2025年发布。 DAMA International,《DAMA数据管理知识体系指南(第二版)》(DAMA-DMBOK2),机械工业出版社,2020年。
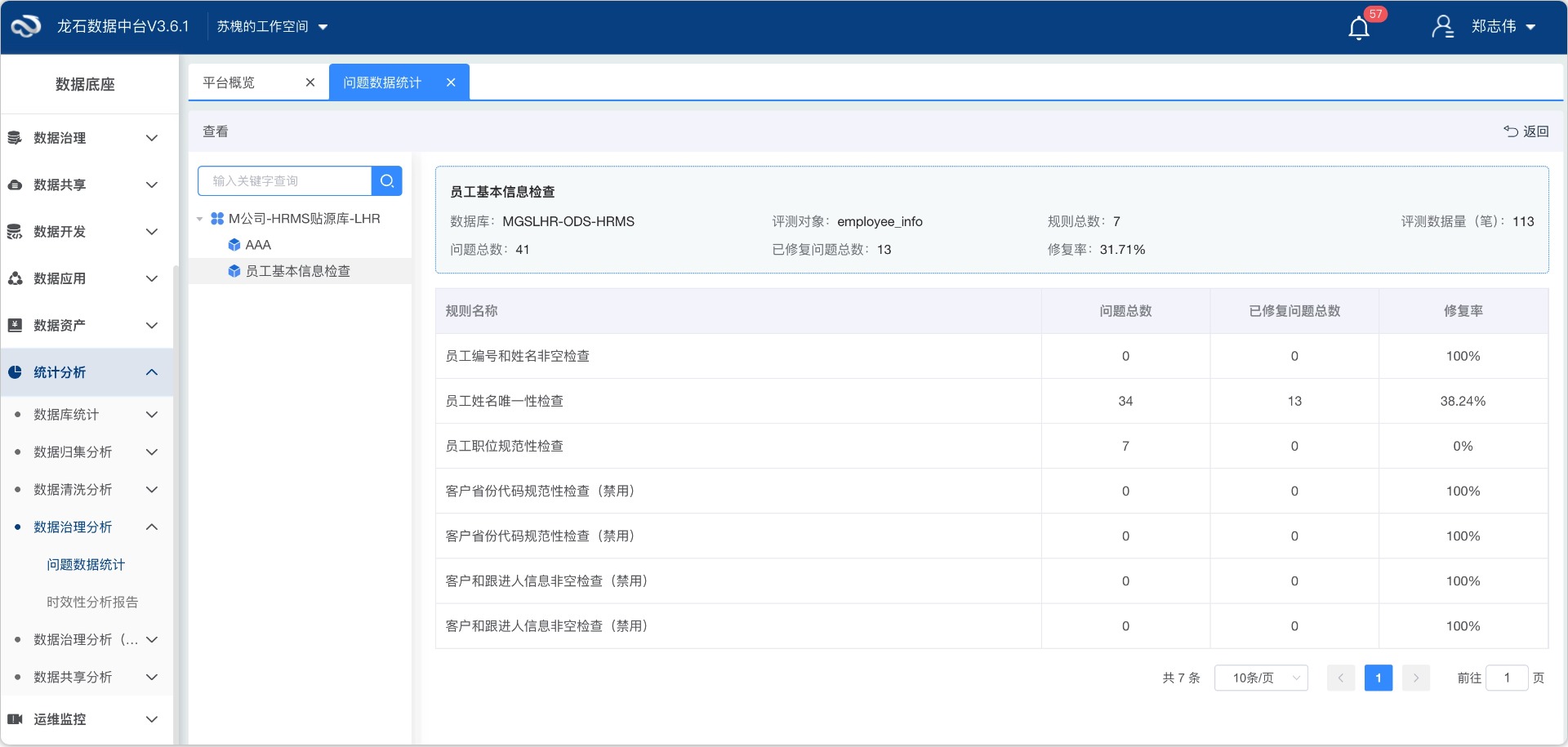
数据质量管理的目标,并不是一次性清理所有问题,而是在不影响业务运行的前提下,让问题能够持续被发现、被跟踪、被修复。规则不在多——从一个核心业务域的三五条规则起步,跑顺了再逐批扩展。规则持续运行,质量持续提升,数据治理才能真正成为日常工作的一部分,而不是项目验收时的一次专项行动。
数据集成不需要半夜爬起来改脚本。龙石数据中台将多源异构数据归集标准化为可视化操作——拖拽组件或向导式勾选,三步完成配置,此后每天自动运行。从手工脚本到自动化集成的转变,不是工具的升级,而是把数据工程师的时间从维护脚本中释放出来,去做更有价值的事情。

"我们选了一家厂商,功能列表拉出来两百多项。上线半年后,业务部门还是用不起来。" 这是过去一年里,不止一家企业的CDO说过的原话。选型时功能列表越看越满意,上线后却发现——数据是接进来了,但质量没人管;报表是能跑了,但指标口径各系统对不上;业务部门想自己找个数,翻了半天目录也找不到。 问题的根源不在功能多少,而在于:选型时只看了功能列表,没看架构层次的完整性。 数据中台不是单一产品,而是一个多层协同的系统。某一层的短板,会在上线后变成整个平台的短板。选型的核心,就是从五层架构的视角去评估——每一层缺了没有,以及层与层之间能不能联动。 一、选型前先问自己三个问题 在讨论厂商之前,有三个问题需要先想清楚。它们的答案决定了你在五层架构中应该侧重哪些层。 1. 你建数据中台要解决什么核心问题? 是数据孤岛打通?是数据质量太差?还是缺少统一的数据服务层?如果核心诉求是"让数据能在系统间流转",数据汇聚层的权重最高。如果诉求是"让数据能信得过、用得上",治理层和资产层才是关键。 2. 你的团队能力和投入预期是什么样的? 有没有专职的数据治理团队?预算是一次性项目还是按年持续投入?如果团队以业务人员为主、IT能力有限,运营保障层(培训、陪跑、监控)的重要性会被放大——平台再好,没人会用等于白建。 3. 你的IT环境复杂度如何? 涉及多少套业务系统?有没有信创要求?是单体企业还是集团多组织?这直接决定了汇聚层的接入能力和架构层的扩展性要求。一个只能做单体部署的平台,在集团场景下会很快碰到天花板。 这三个问题没有标准答案,但它们帮你建立了一个坐标系——接下来看五层架构时,每一层的重要性权重就有了依据。 这三个问题的背景,是国家数据要素战略的加速推进。国家数据局等17部门联合印发的《"数据要素×"三年行动计划(2024—2026年)》[4]明确提出,要推动数据的高质量供给与合规高效流通,在工业制造、商贸流通等12个重点领域释放数据要素乘数效应。与此同时,中国信通院《数据治理产业图谱3.0》[3]的调研显示,数据治理能力不足已成为制约企业数据价值释放的首要瓶颈——选型时对架构完整性的评估,正是应对这一挑战的基础性工作。 二、五层架构:一套穿透功能列表的评估框架 跳出功能列表的对比,从架构层次的角度看,一个完整的数据中台应该覆盖五个层次:数据汇聚层、数据治理层、数据资产层、数据服务层、运营保障层。 这五层对应了数据从"接进来"到"用起来"的完整链路。可以用龙石数据提出的"理采存管用"方法论来理解这个结构: 方法论 五层架构(示意) 该层要回答的核心问题 采 数据汇聚层 数据能不能接得住?——多源异构接入与实时处理 管 数据治理层 数据能不能信得过?——标准、质量、元数据、主数据、安全 存 数据资产层 数据能不能被找到和复用?——资产目录、血缘、标签 用 数据服务层 数据能不能安全地共享出去?——API、数据门户、访问控制 理 运营保障层 平台能不能持续运转?——监控、权限、组织、持续优化 注:"理采存管用"方法论与五层架构之间并非严格的一一对应关系。例如"理"的核心是战略、组织、制度与路线规划,运营保障只是其中的一部分;"存"更侧重数据开发和数仓建设,与资产层的侧重各有不同。上表仅提供理解五层架构的一个参考视角,而非精确映射。 五层之间不是并列关系,而是层层咬合的关系。上一层的产出是下一层的输入:汇聚层把数据接进来,治理层确保数据可信,资产层让数据可被发现,服务层让数据可被消费,运营层保障整个链条持续运行。 多数数据中台产品在汇聚层和服务层做得不错——接入数据源、发布API,这些是基础能力。但在治理层和资产层,差距就拉开了。而这两层,恰恰决定了数据中台是"数据仓库的升级版"还是"真正的数据能力底座"。这一判断与DAMA-DMBOK 2.0[1]的核心主张高度一致——DAMA将数据治理定位为数据管理活动的"核心职能",数据架构、数据质量、元数据、数据安全等知识领域均在数据治理的指导和约束下运转。五层架构中的治理层,正是将DAMA这一理论框架工程化落地的关键环节。 市场上已有部分数据中台产品将治理能力作为架构内核而非附加模块。例如龙石数据中台,其数据标准管理、元数据管理、数据质量管理和资产目录构成了治理层的四个支柱,且各模块可独立部署、按需装配——这种设计让企业不需要为用不到的功能买单。 三、没有孤立的层:五层协同才是真正的考验 各层独立看都可能及格,但加在一起可能运转不起来。选型中真正的区分度,在于层间联动。 以下是五个可以用来验证层间协同的场景: 汇聚→治理联动:数据从源系统接入后,能不能自动触发质量校验和标准落标?如果汇聚和治理是两套独立流程、需要分别配置,上线后的运维成本会很高。 治理→资产联动:治理层产出的元数据、血缘信息,能不能自动同步到资产目录?如果每次数据变更后需要人工更新目录,资产层很快就会过时。 资产→服务联动:资产目录中的数据资产,能不能一键发布为API?还是需要开发人员另外写接口? 服务→运营联动:API的调用情况能不能被监控、限流、审计?异常调用能不能自动告警? 运营→治理→汇聚联动:质量监控发现异常后,能不能自动生成工单、通知责任人、跟踪整改,最终反馈到汇聚层的接入策略? 实操建议:选型POC时,不要只测单层功能。拿一个真实的端到端场景——比如"从ERP接入物料主数据→自动校验质量→生成资产目录→发布API→在监控面板看到调用情况"——让厂商现场走一遍。能一口气跑通的,说明五层架构是内建的;跑不通需要各种变通和手工操作的,说明各层之间是拼凑的。 四、逐层拆解:每一层到底看什么 数据汇聚层:不只是能"接" 汇聚层是数据中台的第一关。选型时最容易犯的错误是被厂商的连接器列表长度迷惑——"支持100+数据源"听起来很美,但你需要问的是:支持的是你实际在用的那些吗? 三个必验点: 连接器覆盖:是否覆盖关系型数据库(MySQL、Oracle、SQL Server、PostgreSQL)、国产数据库(达梦、人大金仓)、消息队列(Kafka)、文件(CSV、Excel)、API等多种接入方式?工业场景下,是否支持OPC、Modbus等工业协议? 采集模式:是否同时支持批量全量、批量增量、实时CDC(Change Data Capture)?业务高峰期能不能做到不对源系统造成性能压力? 异构转换:不同系统的数据格式、编码、字段命名各不相同,平台能不能在接入环节完成转换和标准化? 常见陷阱:厂商演示时用MySQL到MySQL的同步,看起来很流畅。但你的实际环境可能是Oracle→达梦、SAP HANA→PostgreSQL,或者更复杂的多源异构场景。拿你环境中最复杂的那条链路去测。 考察参考:数据集成模块是否支持可视化ETL拖拽式操作,能否在分钟级完成百万级数据交换——这些是汇聚层工程化成熟度的直观指标。 数据治理层:选型的核心区分点 这是五层中最考验产品深度的一层,也是最容易被"功能列表上有"所掩盖的一层。很多产品的数据治理模块,实际只能做基本的元数据描述和简单的数据字典管理——远不足以支撑企业级的数据治理需求。 治理层需要从五个子维度逐一验证: 数据标准管理:平台能不能定义字段级的业务标准和校验规则?标准定义后,能不能在实际数据接入时自动执行落标稽核——也就是"定义的规则"真的能变成"执行的检查"?如果标准管理模块和实际数据流之间是脱节的,那就是一纸空文。 数据质量管理:质量规则是只能技术人员写SQL配置,还是支持可视化、业务人员也能参与?是否采用旁路监测模式——即在不侵入业务系统、不影响数据流转的前提下并行扫描?发现问题后,能不能追溯到源头、生成工单、跟踪整改闭环?如果质量模块只能"检测"不能"治理",价值就少了一大半。 元数据管理:元数据采集是全自动的,还是需要大量手工录入?血缘分析能不能跨系统追踪——从ERP的一张表追溯到数据中台的一个指标?技术元数据和业务元数据能不能关联起来,让业务人员看懂"这个字段在业务上是什么意思"? 主数据管理:能不能处理多源冲突归并(比如ERP里的"大理石A级"和CRM里的"A类石材"是不是同一个物料)?编码规则能不能灵活配置?主数据的变更能不能通过审批流程管控? 数据安全管理:是否支持数据分类分级?能不能自动识别敏感数据?脱敏策略是静态的还是支持动态脱敏?安全管控能不能覆盖数据的全生命周期——从采集、存储、加工到共享? 验证方法:不要问"你们有没有数据质量管理",要拿一个真实业务场景让厂商现场配置——从建质量规则、跑扫描、出报告到问题追溯,能不能在半小时内完成全流程。 治理层考察参考:以下以龙石数据中台为例,说明各项能力的落地形态,供评估同类产品时对照参考: 落标稽核:按照已定义的数据标准,自动检查接入数据是否符合规范要求(而非只在文档里写标准)。 旁路监测:数据正常入库,质量检查在旁路并行扫描,发现问题时打标记、告警或生成工单,不阻断业务数据流转。 自动采集元数据:系统自动抓取数据库表结构、字段信息和数据流转关系,无需人工逐表录入。 全链路血缘追踪:从源系统的一张表到中台的一个指标,中间经过了哪些加工步骤,可以完整追溯。 这些能力可以作为评估同类产品的参照基准。 数据资产层:数据能不能被找到和复用 资产层是数据中台"从管到用"的桥梁。一堆高质量的数据如果找不到、看不懂,就跟没有一样。 三个验证点: 资产目录的业务化程度:打开资产目录,看到的是技术表名(ods_sap_mseg_2024),还是业务化的描述("SAP物料移动明细表")?业务人员能不能用"上月销售额"这种自然语言搜到对应的数据资产? 血缘与标签:能不能从资产目录上直接看到数据的来源系统、经过了哪些加工、被哪些应用引用?能不能给资产打业务标签,实现多维度检索? 资产运营:有没有资产发布、上架、申请、审核的流程?能不能看到哪些资产被高频使用、哪些长期无人问津——从而指导数据治理的优先级? 常见陷阱:很多平台的"资产目录"本质上是数据库表的列表视图,多了一个搜索框而已。真正的资产目录应该是一个面向业务的数据地图——让非技术人员也能找到、看懂、申请使用需要的数据。 考察参考:数据资产目录是否支持编目、发布、上架、申请审核的完整流程,是否以业务视角(而非技术视角)组织数据资产——这是判断资产层成熟度的关键。 数据服务层:安全可控地"给出去" 数据的价值在于流动。服务层决定了数据能多快、多安全地到达消费端。 三个验证点: 服务化程度:数据能不能通过API、文件、消息等多种方式对外提供?还是只能通过数据库直连(这在大规模场景下是安全隐患和性能瓶颈)? 安全管控:API能不能做到认证、鉴权、限流、审计?数据共享能不能追溯到谁在什么时间访问了什么数据? 自助化:业务部门能不能在数据门户上自助申请、审批、获取数据,还是每次都需要IT部门手工导出? 常见陷阱:平台提供了API功能,但API网关和数据治理模块是割裂的——调用方拿到的数据没有质量标准、没有血缘信息。好的服务层应该和治理层、资产层打通:通过API获取的数据,质量和血缘信息一并带出。 考察参考:API平台的并发能力(是否支持万级并发、毫秒级响应)、数据门户的自助化程度(检索→申请→审批→获取的全流程),是验证服务层工程化能力的两个关键场景。 运营保障层:平台能不能持续转 很多选型评估在服务层就结束了。但真正决定中台长期成败的,是运营层。 三个验证点: 监控预警:平台能不能监控的不只是ETL任务是否跑完,也包括数据质量趋势、数据安全异常、资源使用情况?告警能不能分级、能不能自动触发处理流程? 组织与权限:支持多租户吗?能不能做到"一集团一中台、一公司一空间"的分权分域?权限粒度能不能到行级、列级? 持续服务能力:厂商交付完就撤,还是提供培训+陪跑机制?有没有定期的巡检和健康度评估?如果企业团队在项目中需要完成能力转移——从"依赖厂商"到"自主运营"——厂商有没有成熟的赋能体系? 常见陷阱:监控只覆盖了任务执行状态(跑没跑完),没有覆盖数据状态(质量好不好、安全有没有问题)。另外,很多厂商的"服务"在合同签署后就转为被动响应模式——有事你找我,没事我不动。但数据中台是一个需要持续运营的系统,不是一次性交付的软件。 考察参考:交付后是否提供培训+陪跑机制,是否支持从"厂商驱动"向"企业自主运营"的能力转移——这是选型中容易忽视但长期影响最大的一个维度。 五、案例验证:两个真实项目看五层落地 理论框架最终要靠实际项目验证。以下是两个不同行业的数据中台项目,按五层架构对照。(企业名称已脱敏,下同。) 案例一:华东某化工企业(年产值超百亿元) 该企业MES、ERP、CRM等系统相互独立,OT生产数据与IT业务数据未打通,物料编码不统一,销售预测与生产排产脱节。 项目以数据中台为核心,贯通了从生产现场到管理决策的完整数据链路: 五层 落地实践 汇聚层 接入DCS、MES、LIMS、ERP数据,构建工业数据湖,实现OT/IT融合 治理层 建立企业级数据标准体系,统一物料、产品编码,构建质量管理机制 资产层 构建面向工序与批次的数据模型,形成可复用的工业数据资产 服务层 产销协同驾驶舱、业财一体全景屏,API服务支撑多系统共享 运营层 成立数据管理部、设立数据管家岗位,将数据治理纳入绩效考核 上线一年后,库存周转率提升28%,订单交付及时率提升至91%,报表出具周期提前4天。更重要的是,企业从"项目驱动"转向"机制驱动"——数据治理不再是项目结束就停止的活动,而是一个持续运转的体系。 该企业数据管理部负责人在项目复盘会上坦言:"过去我们每年花几百万做数据治理项目,项目结束质量就回落。现在中台把治理规则固化到系统里,数据管家盯着指标,质量问题自动生成工单——治理终于从运动式变成了常态化。" 案例二:江苏某建筑装饰集团(200余家子公司) 集团旗下200余家区域子公司,同一材料在苏州叫"大理石A级"、在南京叫"A类石材",主数据混乱导致跨公司对账耗时5天。 项目建立"一集团一中台、一公司一空间"的多租户架构: 五层 落地实践 汇聚层 200+子公司多源异构数据接入 治理层 围绕物料、供应商、项目三个实体统一编码规则,集团通报强制执行 资产层 集团-公司-项目三级数据资产目录,穿透式可查 服务层 穿透式经营驾驶舱,总部可实时查看任一子公司的项目经营数据 运营层 工作空间模型——总部统一标准管控,子公司独立空间自治 跨公司对账从5天缩至1天,数据纠纷减少80%,项目平均工期缩短10%。这个案例特别验证了运营层中"多租户模型"的价值——集团的管控需求和子公司的业务灵活性不再是非此即彼的矛盾。 集团数据治理委员会的一名委员在验收会上感慨:"苏州子公司说这是大理石A级,南京说这是A类石材——同一个东西两个名字,对一次账要扯五天皮。现在总部统一编码,子公司不能再各说各话了,光这一项一年省下的管理成本就有几百万。" 两个案例有一个共同特征:没有哪个是只做了汇聚层和服务层就成功的。 每个案例中,治理层的扎实程度直接决定了最终效果——统一编码、质量标准、元数据管理,这些看起来"不性感"的基础工作,恰恰是数据中台能不能真正用起来的根基。 六、选型清单:一张表带走 以下是基于五层架构的选型评估清单。每一行对应一层,你可以拿着它去考察任何一个候选产品。 层次 核心验证问题 怎么测 红牌信号 数据汇聚层 能不能接入你环境中的所有数据源? 列出你环境中最复杂的3-5个异构源,现场验证 只支持主流数据库,工业协议/国产数据库/老旧系统无方案 数据治理层 标准/质量/元数据/主数据/安全五个子维度是否齐全且可落地? 拿一个真实业务场景,现场配置一条完整的质量规则全流程 元数据靠手工录入;质量标准只能写文档不能执行;质量检测会阻塞数据流转 数据资产层 业务人员能不能自己找到、看懂、申请数据? 用业务关键词搜索,看能不能搜到对应资产,验证全程不需要IT介入 资产目录只是数据库表列表;没有血缘追踪;没有申请审批流程 数据服务层 数据能不能安全可控地共享? 验证API从创建→发布→鉴权→限流→审计的完整链路 只能数据库直连;没有API服务化;共享后无法追溯 运营保障层 厂商交付后企业能不能独立运转? 看培训+陪跑机制、监控预警体系的覆盖范围、多租户支持 只有基础任务监控;不提供培训陪跑;不支持多租户 使用建议:选型不是打分求和。某一层不及格,整体就不及格——数据中台是串联系统,最薄弱的那个环节决定整体水位。如果你的核心痛点是数据质量,治理层必须是重点考察对象,不能因为汇聚层功能特别丰富而放水。 七、常见问题 Q1:五层必须全上吗?能不能先上几层? 可以分阶段启动。但至少汇聚层和治理层应该同步推进——如果数据进来了却没有质量标准,中台就只是一个数据管道。这引出一个选型前提:产品是否支持模块化独立部署。部分产品(如龙石数据中台)采用模块化架构,各层能力可独立部署、按需装配,企业可以从最紧迫的模块起步。 Q2:开源方案能覆盖五层吗? 汇聚层有成熟的开源工具(如DataX、Kettle),但治理层(标准管理、质量稽核、血缘追踪)和资产层(业务化目录、标签体系)的开源方案基本需要大量自研拼接,运营层更是开源生态的薄弱环节。如果团队有5人以上专职数据工程能力、愿意投入半年以上做集成开发,可以考虑混合方案。大部分企业选择商用产品,省下的不是license费,是时间和整合成本。 Q3:治理层为什么是选型的核心区分点? 因为汇聚和服务层的能力在各厂商之间差异在缩小——数据库连接器、API网关已经成为标配。但治理层的深度差异很大:标准能不能从文档变成自动稽核?质量能不能溯源到源头?元数据能不能全自动采集?这些决定了数据中台是"数据仓库升级版"还是"数据能力底座"。以DCMM 2.0(GB/T 36073-2025)[2]九大能力域为参照,其中数据治理、数据标准、数据质量、数据架构、数据资产等域,都与中台治理层的深度直接相关。 Q4:中小企业资源有限,怎么简化评估? 把五层清单压缩为三个必查项:汇聚能不能全(你现有的系统都能接)、治理能不能深(至少质量和标准两个子维度能落地)、服务能不能活(数据能通过API安全共享出去)。不用追求每层100分,但要确保没有哪层是零分。另外,中小企业对运营层的"培训+陪跑"需求往往比大企业更迫切——大企业有自己的数据团队可以摸索,小企业更需要厂商带着走。 参考来源 [1] DAMA International,《DAMA数据管理知识体系指南》(DAMA-DMBOK 2.0) [2] GB/T 36073-2025《数据管理能力成熟度评估模型》(DCMM 2.0) [3] 中国信通院,《数据治理产业图谱3.0》(2023年12月) [4] 国家数据局等,《"数据要素×"三年行动计划(2024—2026年)》

"演示很漂亮,功能列表拉出来两百多项。但上线半年后,业务部门还是用不起来。" 这是一家制造企业的 CDO 在选型复盘会上说的一句话。他们花了四个月对比厂商、两个月部署,最终发现——功能都有,但数据不可信,业务不敢用。 选型踩坑,不缺教训。缺的是一套围绕治理核心能力的评估框架。 选型前,先问自己三个问题 在看任何厂商之前,先想清楚三件事: 你要解决什么核心问题? 是数据孤岛打不通?是数据质量太差影响了报表可信度?还是缺少统一的数据服务层让业务部门自己找数用数?不同答案指向完全不同的选型侧重点。 你的团队能力和投入预期是怎样的? 有没有专职的数据治理人员?预算是一次性项目采购还是按年持续投入?这决定了你能接住多重的平台。 你的 IT 环境有多复杂? 涉及多少套业务系统?有没有信创要求?是单体企业还是集团多组织? 这三个问题不搞清楚,看再多彩页和 Demo 都没用。它们决定了你的选型重心——对有些企业来说,数据集成能力是第一优先级;对另一些企业来说,数据治理深度才是决定成败的关键。 DCMM 2.0(GB/T 36073-2025)[2] 将数据管理能力划分为九个能力域,其中"数据战略"域明确提出组织应首先明确数据管理的目标和优先级——选型前的自我评估,实质上就是在做这一步。 评估框架:五个维度从何而来 选型评估需要一个底层逻辑。根据中国信通院《数据治理产业图谱 3.0》[3],数据中台市场已从"单一产品"向"平台化、组件化、可组装"方向演进,选用产品时更需要以方法论为尺来衡量产品深度。市场上已有部分数据中台产品(如龙石数据中台)采用"理、采、存、管、用"五阶段方法论来组织产品能力——理(定战略、建体系、摸家底)、采(多源异构数据归集)、存(数据模型与仓库分层)、管(标准/质量/元数据/主数据/安全)、用(资产目录/共享/分析/智能用数)。 这个方法论框架本身就提供了一个评估视角。脱离方法论谈功能列表,很容易陷入"你有一百个功能我有一百零一个"的军备竞赛。反过来,以方法论为尺,看产品在每个环节上到底能做到什么深度——这才是选型评估该做的事。 以下五个评估维度,正是从这套方法论中提炼出来的关键治理能力。每个维度都指向一个核心问题:这个产品能不能帮助企业实现从"数据原料"到"数据资产"的全链路? 维度一:数据集成与标准管理能力 核心问题:能不能把散落在各系统的数据归集起来,同时确保大家说的是同一种"数据语言"? 数据中台的第一道坎是"接进来"。企业的 ERP、MES、CRM、SRM 等系统动辄运行了五到十年,数据库类型不一、接口标准不一、数据格式不一。如果中台产品的集成能力只支持有限的几种数据源,或者只能通过定制开发来对接,后续每接入一个新系统都是一次工程。 考察时重点关注三点:支持哪些数据源类型(数据库、API、文件、消息队列)?是否具备批流一体的采集能力(全量+增量、批量+实时)?集成配置是可视化拖拽还是需要写代码? 但光接进来不够。数据进来了,字段名叫"cust_name"还是"客户名称"?"销售额"含不含税?不同系统的口径对不齐,接进来的只是一堆看不懂的数字。数据标准管理能力——能不能定义字段级的业务标准和校验规则——决定了数据的可用性下限。 华东某大型化工企业(企业名称已脱敏,下同)的案例就很典型。MES 里的生产数据与 ERP 里的经营数据长期割裂,物料编码在三个系统中各不相同,销售预测与生产排产完全脱节。在搭建数据中台的过程中,团队做的第一件事不是接数据,而是建立企业级数据标准体系,统一了物料、产品、工序等核心业务对象的编码规则和指标口径。标准先行,集成才有了意义。 维度二:数据质量与元数据管理成熟度 核心问题:数据进来之后,怎么保证它是可信的? 这是区分"数据汇聚工具"和"数据管理平台"的关键分水岭。 数据质量管理的考察要点:质量规则能不能可视化配置(而非写 SQL)?业务人员能不能参与规则定义?质检是旁路并行扫描还是拦截入库? 一个值得关注的设计理念是旁路监测——数据正常入库,质检系统并行扫描,发现问题打标记、发告警、生成整改工单,但不阻断数据流转。这种设计在保障数据流动性的同时实现了质量管控,相比"不过检不入库"的强拦截模式,在实际项目中更容易被业务部门接受。市场上已有部分产品(如龙石数据中台)采用这种旁路监测方式,将质量规则配置从纯技术操作变为可视化拖拽,非技术人员也能上手。 元数据管理同样不可忽视。考察时问几个具体问题:元数据采集是全自动的还是需要大量手工录入?血缘分析能不能跨系统追踪——从报表字段一路追溯到原始业务系统的源表?这决定了出问题时能不能快速定位根因,也决定了后续数据变更的影响范围能不能提前预判。 DAMA-DMBOK 2.0 [1] 将数据质量和元数据管理列为核心知识领域,强调质量管理应覆盖"定义、测量、分析和改进"四个环节。DCMM 2.0 [2] 同样将数据质量列为九大能力域之一,要求问题能追溯到源头。 江西某国控集团在数据中台建设中,建立了覆盖完整性、准确性、一致性、及时性、唯一性五个维度的自动化质量稽核体系——这正是 GB/T 36344-2018《信息技术 数据质量评价指标》[5] 定义的六个维度中除可访问性外最直接影响数据应用效果的五个维度。系统实时检测财务数据填报错误、投资项目信息缺失等问题,自动预警、精准整改。项目落地后,业务人员数据相关工作量有了明显下降。 维度三:主数据管理机制 核心问题:同一物料三种叫法、同一供应商多个编码——你选的产品能搞定吗? 主数据混乱是绝大多数数据问题的源头。物料、供应商、客户、项目部——这些跨系统共享的核心实体,一旦编码不统一、名称不一致,上面所有分析、报表、数据共享都建立在错误的根基上。 考察主数据管理能力时,不要只看"支持主数据管理"这句宣传语,要追问:能不能制定统一的编码规范?历史数据清洗是手工还是半自动化?主数据变更后能不能自动分发到各下游系统?合并冲突处理逻辑能不能灵活配置? 华东某建筑装饰集团的经历很有参考价值。这家企业旗下两百余家区域子公司,同一装饰材料在苏州叫"大理石A级",在南京叫"A类石材",在总部采购系统里叫"石材_01"。三种叫法导致跨公司调拨、结算频繁出错,每月对账需要大量人工干预。通过统一物料、供应商、项目部编码并建立主数据分发服务后,跨公司对账时间从五天缩短至一天,数据纠纷大幅减少。各子公司"一物一码",采购、库存、调拨终于有了统一的参照系。 DCMM 2.0 [2] 将"数据标准"列为独立能力域,主数据管理的本质正是数据标准在核心实体上的集中落地。 维度四:数据安全与合规保障 核心问题:数据安全不是装个防火墙就完了——从采集到使用的全链路,有没有兜底机制? 在信创环境越来越普及、《数据安全法》[6] 等数据安全法规日趋严格的背景下,安全合规已从"加分项"变成了"一票否决项"。 考察分两层。第一层是基础能力:是否具备数据分类分级功能?敏感数据能不能自动识别?脱敏策略能否覆盖全链路(采集→存储→计算→输出)?第二层是信创适配:有没有完整的国产化兼容性认证(操作系统、数据库、中间件、芯片)? 但认证列表长不代表适配好。一个务实的做法:在 POC 阶段就在实际信创环境上跑一遍——从操作系统到数据库全链路验证,而不是只看厂商提供的兼容性列表。 数据安全还有一层容易被忽视的维度:组织权限的精细化管控。对于集团型企业,"总部要统一管、子公司要自治"的诉求天然存在。好的中台产品应该支持分权分域的工作空间模型——总部制定统一的数据标准和安全策略,子公司或部门在独立空间内管理自己的数据资产,权限隔离但逻辑归集。 维度五:数据资产目录与共享服务 核心问题:中台建好了,业务人员能不能自己找到数据、用上数据?还是换了一个地方继续提申请、等排期? 这可能是五个维度中最容易被选型时忽略的一个。很多企业选数据中台,精力全放在"怎么把数据管好"上,忘了问一句:"管好之后,怎么让人用上?" 数据资产目录不是 IT 人员看的元数据列表,而是业务人员的"数据地图"。一个好的资产目录应该做到:业务人员能用自己理解的业务语言搜索数据(而非技术表名)、能看到数据的含义和来源、能自助申请使用——从申请到审批到获取数据,全程在线完成。 数据共享服务的考察重点:是否支持 API 服务化发布?是否支持多种共享方式(API、文件、数据库视图)?网关有没有流量控制、鉴权、监控能力? 江西某国控集团的实践在这方面提供了参考。除了数据质量稽核体系,他们还建立了可视化的数据资产目录和 API 共享服务——监管应用无需再做定制化接口开发,通过标准的 API 服务即可快速获取所需数据。这带来的变化不仅是效率提升,更是数据供给模式的转变:从"业务提需求→IT 定制开发"的项目制,转向"数据资产上架→业务自助获取"的服务制。 这种转变的深层意义在于:数据的价值不再取决于 IT 部门的排期,而是取决于业务部门能在多大范围内自由发现和使用数据。国家数据局等十七部门联合发布的《"数据要素×"三年行动计划(2024—2026年)》[4] 明确提出推动数据跨部门、跨层级共享流通,而数据资产目录与共享服务体系正是实现这一目标的技术基础设施。 选型清单:一张表帮你理清思路 评估维度 核心问题 考察方法 数据集成与标准 多源异构能否归集?数据语言是否统一? 用真实的异构数据源做接入验证;检查标准管理是否支持字段级定义 数据质量与元数据 数据进来后能否验证可信度?出问题能否追溯? 现场配置一条质量规则(从建规则→跑监测→出报告);验证血缘跨系统追踪 主数据管理 核心实体的编码和名称能否统一? 问历史数据清洗方案;验证主数据变更自动分发到下游系统 安全与合规 全链路数据安全保障?信创适配? 检查分类分级/脱敏链路;POC 阶段在实际信创环境全链路跑通 资产目录与共享 业务人员能否自助找数用数? 用业务语言搜索数据资源;验证从申请到获取的全流程在线化 上面这张表是一个评估起点。选型时还有一个容易被忽视的维度:服务模式。数据中台不是买个软件装上就完了——它涉及组织变革和团队能力建设。厂商是交付完就走,还是有成熟的培训和持续陪跑机制?以龙石数据中台为例,其"产品+培训+陪跑"模式提供了一个参照系:理论培训让团队知道"为什么做",实施培训让团队知道"怎么做",实战陪跑让团队在真实项目中"动手做"。判断标准很简单——项目结束一年后,你的团队能不能脱离厂商独立运营这个平台? FAQ Q1:功能多少算够? 不是越多越好。一个数据中台的核心价值在于数据治理深度,而不是功能列表长度。如果你现阶段主要需求是数据集成和基础报表,很多治理类模块可以后续扩展。但如果目标是建设长期数据底座,标准、质量、主数据、元数据这些核心治理能力一个都不能少——这也是 DCMM 2.0 [2] 重点评估的能力域。 Q2:开源方案能不能用? 取决于团队能力。如果有一支五人以上的专职数据工程团队,愿意投入半年时间做二次开发和集成,开源方案可以纳入评估。但如果团队以业务人员为主、希望尽快看到效果,商用产品省下的不是 License 费,而是时间成本和试错成本。 Q3:中小企业预算有限怎么选? 不要看总价,看首年投入和见效速度。优先选择模块化程度高的产品,先上最紧迫的模块(比如数据集成+质量监测),跑通之后再逐步扩展。市面上已有部分产品(如龙石数据中台)支持功能模块独立部署、按需装配,单台服务器即可起步,部署周期约一周。这种轻量化启动模式适合不想一次性大投入的团队。 Q4:信创环境怎么选? 确认厂商有没有完整的信创适配认证——覆盖操作系统(麒麟、统信)、数据库(达梦、人大金仓、OceanBase)、芯片(华为鲲鹏、飞腾)等多个层面。但认证列表长不等于适配好。最可靠的做法是在 POC 阶段就在实际信创环境上完整跑一遍,从安装部署到核心业务流程全链路验证,而不是只看厂商提供的兼容性清单。 参考来源 [1] DAMA International,《DAMA-DMBOK2: Data Management Body of Knowledge》,第二版,Technics Publications,2017年 [2] GB/T 36073-2025《数据管理能力成熟度评估模型(DCMM 2.0)》 [3] 中国信通院,《数据治理产业图谱 3.0》,2023年12月 [4] 国家数据局等十七部门,《"数据要素×"三年行动计划(2024—2026年)》,2024年1月 [5] GB/T 36344-2018《信息技术 数据质量评价指标》,国家市场监督管理总局、中国国家标准化管理委员会,2018年6月发布,2019年1月实施 [6] 《中华人民共和国数据安全法》,2021年6月10日第十三届全国人大常委会第二十九次会议通过,2021年9月1日起施行 龙石数据是国内领先的数据管理型中台厂商,以数据治理为核心能力,基于"理采存管用"方法论为企业提供数据中台、AI用数智能体等产品与「产品+培训+陪跑」全周期服务。了解更多:https://www.longshidata.com




