

来源(公众号):大数据AI 智能圈
昨天跟一个朋友聊天,他跟我抱怨说公司新上的AI客服系统实在让人崩溃。
"明明昨天刚有人问过年假怎么休,今天又有人问,系统还得傻乎乎地去数据库里翻一遍,这不是折磨人吗?"
我一听就乐了,这不就是典型的RAG技术"
健忘症"吗?

数据分析师的噩梦:重复劳动何时休?
朋友在一家互联网公司做数据分析师,每天要处理几百个业务方的问题。最让他头疼的是,那些关于数据口径、指标定义的问题,十有八九都是重复的。
"比如有 人问GMV怎么计算,昨天问,今天问,明天还是有人问。我们的RAG系统每次都要去向量数据库里检索一遍,相似度计算,文档匹配,这一套流程走下来,最少也要200毫秒。"
他掰着手指头给我算账:"一天1000个查询,30%是重复的,就要多花60秒的数据库时间。一个月下来,光是Pinecone的账单就要多花几千块。"
这让我想起了小时候写作业,老师总说"这道题昨天刚讲过",但我还是得乖乖翻书找答案。RAG系统就像那个认真但死板的学生,每次都要重新翻一遍资料。
问题的根源在于,传统RAG完全没有记忆的概念。它就像一个患了健忘症的研究员,哪怕刚刚看过同一个文档,下次再需要时,还是要从头开始检索。
这就像是图书馆里有个图书管理员,你每次问他同一本书在哪里,他都要重新在整个图书馆里找一遍,哪怕那本书就摆在他面前的桌子上。
CAG:给AI装个大脑
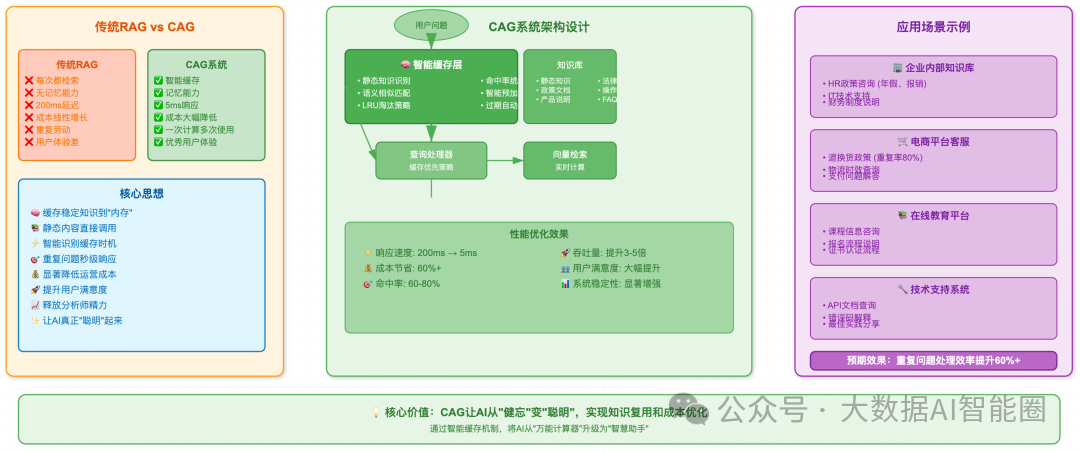
那天下午,我跟朋友说起了CAG(缓存增强生成)技术的思路。
"其实解决这个问题很简单,就是给AI装个'大脑',让它记住哪些是经常被问到的固定答案。"
我拿起咖啡店的餐巾纸,给他画了个简单的架构图:"你看,我们可以把那些稳定的、制度性的知识,比如公司政策、产品说明、法律条文,这些几乎不会变的内容,直接缓存起来。下次有人再问,直接从缓存里拿就行了。"
朋友眼睛一亮:"就像给电脑加了个内存条?"
"没错!这样一来,那些重复的问题,响应时间可以从200毫秒降到5毫秒,准确率还能保持100%。因为缓存的内容都是经过验证的正确答案。"
我们现场算了一笔账:如果是每天1000次查询,30%重复,用CAG后可以节省60%的数据库调用成本。更重要的是,用户体验会显著提升——没人喜欢等待,特别是重复等待。
更重要的是,CAG不仅仅是缓存,它还有智能识别能力。系统会自动判断哪些内容适合缓存,哪些需要实时检索。比如股价、天气这种实时数据,就不适合缓存;而公司制度、产品FAQ这些静态内容,就非常适合。
重新定义AI的"智慧"
真正的技术进步,往往来自于对"显而易见"的重新思考。
我们总是习惯性地认为,AI应该具备强大的推理能力,却忽略了最基本的事实:在这个信息爆炸的时代,"知道去哪里找答案"比"当场算出答案"更重要。
CAG技术给我们带来的启示是:智能不在于计算能力有多强,而在于能否合理利用已有的知识。
就像一个经验丰富的老医生,面对常见症状时不会每次都重新查医书一样,真正的AI系统也应该具备这种"经验积累"的能力。
这背后其实反映了一个更深层的思考:什么才是真正的智能?是每次都从零开始推理,还是能够合理利用历史经验,提高效率和准确性?
我倾向于后者。毕竟,人类的智慧很大程度上就体现在对经验的积累和运用上。
结语
技术在进步,AI也在进化。
从最初的无记忆模式,到RAG的检索增强,再到CAG的缓存增强,每一步都更加贴近真实的业务需求。
也许很快,我们就会看到更多基于CAG理念的AI应用崛起。到那时,"重复劳动"这个词,可能真的要退出历史舞台了。
AI智能的真正意义,不在于能够处理多少复杂问题,而在于能否优雅地解决那些看似简单但重复性高的问题。
这,才是技术为人类服务的真正价值。




