

之前分享过中台,前两天又分享了数据治理的相关内容。有个同学嚷嚷着让我说一下数据中台。虽然我做过数据中台,但是不算成功,写起来总觉得不太自信。
既然朋友盛情邀请,那就把我的理解整理一下,给大家分享一下。
在数据领域,从业务方向上可以分为OLTP(联机事务处理)和OLAP(联机分析处理)两个领域。这个名字很拗口,但是也很有意思。
OLTP就是你在本地操作,相对于单机而言,数据记录在本地,就叫单机事务处理,在本机操作,数据记录在服务器上,这叫联机事务处理。
OLAP就是数据存在服务器上,你在本地调用数据进行在线分析,这叫联机分析处理。
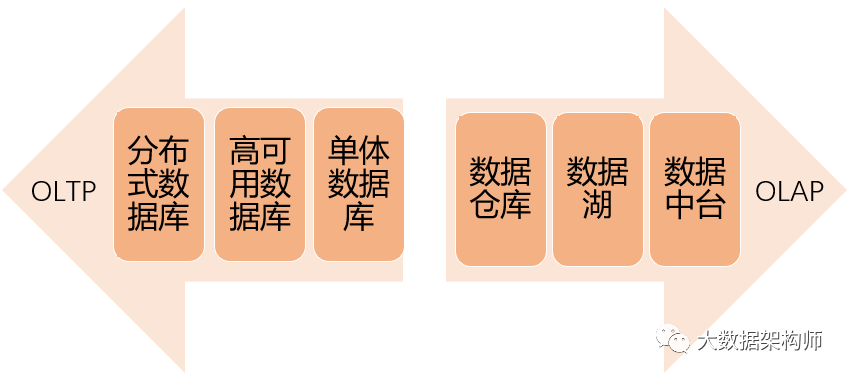
OLTP的发展路径其实就是数据库的不断演进,从关系型数据库从单机数据库到高可用版本,到现在的分布式关系型数据库。另外为了满足各种场景下的数据存储和查询,还诞生了NoSQL、MPP、时序数据库等一系列的数据库,大数据行业就此拉开序幕。
OLAP的发展路径也很有意思。一开始只是在业务数据库中建个表,统计一下各种固定报表。后来需要分析的内容越来越多,就开始不断的向前发展,这样也迎来了大数据分析师的黄金发展期。
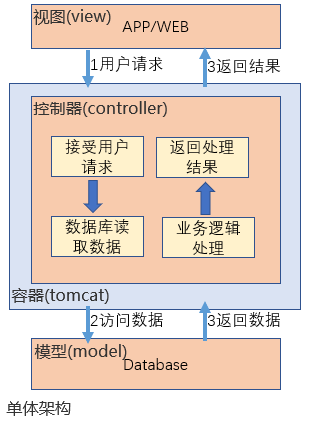
最早的时候,是没数据仓库什么事情的,OLAP的内容也少,只有少量的固定报表,那时候都是开发人员在业务库直接存储的。

现在很多系统仍然是这样的,比如你采购一个erp、电商平台等,自带的绝大部分报表都与业务系统在一个数据库中的。其实这个时候正式对应系统架构中的“单体架构”。
随着信息系统的不断建设,管理者开始不太满足于固定的寥寥几张报表,他们期望看到更多细节,找到异常,发现问题。这时候,就必须要有一个信息系统去满足他们的需求,DSS/BI系统就顺应而生,几乎同时,数据仓库的概念也一并被提出。
1990年前后,现代化的BI和数据仓库几乎同时诞生。这也无可厚非,这俩天生一对啊。BI就是OLAP的业务应用体系,数仓就是为了支撑BI而生的。数据仓库之父比尔·恩门(Bill Inmon)在1991年写了一本书《建立数据仓库》。对,就是那个inmon、kimball建仓方法论的inmon。
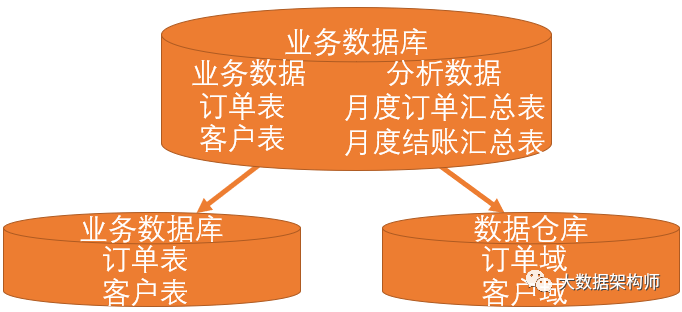
这时候,业务数据和分析数据开始分道扬镳,走上了不一样的道路。业务数据处理(OLTP)向准确、及时、一致的方向不断迈进;分析数据操作(OLAP)向历史静态、聚合、关联、多维的方向发展。
一个典型的问题就是在业务数据库中,你无法回答类似于一个订单的选购、下单、支付、发货、完成的全流程各用了多少时间的问题。当然,你可以通过冗余N个时间戳来解决,但是你无法将所有状态变化的数据统统记录下来。因为OLTP是反应当前的情况。
而OLAP就可以通过全量表、拉链表等方式保存历史状态数据,从而对每个对象进行历史分析。
tips:除了拉链表之外,通常还有全量快照表、增量表和流水表,一共四种形式收集历史数据,这四种情况下次开单篇聊。

数据仓库建设的目的就是为了进行数据分析用的。原则上来说数据仓库中的数据是不允许修改的。所以你看HIVE根本就没有update和delete的功能,很多人非常不理解其中的原因,其实这就是因为HIVE就是为了数据仓库而生的。
数据仓库解决的核心问题其实就是上面说到的,解决历史情况追踪,解决数据分析能力、解决业务频繁变化等一系列问题。
拿inmon老爷子的话来总结一下:
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
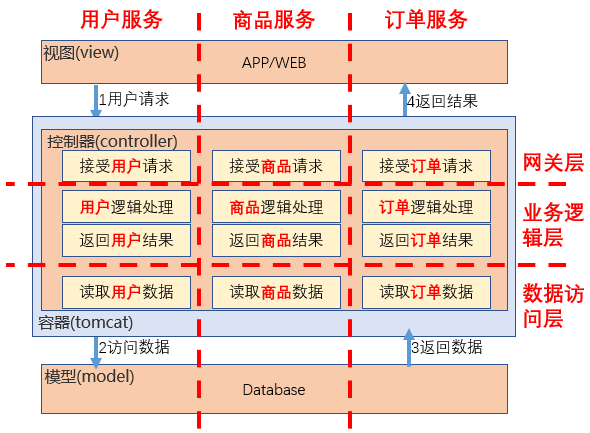
这个像什么?是不是很像系统架构中的微服务?对不对?横向分层,竖向切分领域。跟微服务的理念一样一样的。
数据湖时代
数据仓库很好用,多维分析简直能满足老板的一切需要。它能让决策者从公司总体情况,一直下钻到每个业务员的贡献,极大的满足了决策者的掌控欲,同时也给企业的决策带来了坚实的数据基础。
但是,数据仓库也有其非常致命的弊端:所有数据必须经过定义之后才能被使用,所有数据都经过了ETL处理,所有数据都被聚合。
作为数据工作者的你,肯定能理解其中的含义。一旦数据被动过,那就会造成信息丢失。
而在算法时代,这是不可接受的。
因此,在数据仓库发展了20年之后的2010年,Pentaho的创始人James Dixon提出了一个“数据湖”的概念。简单来说,数据湖其实可以理解为一个巨大的ODS层。
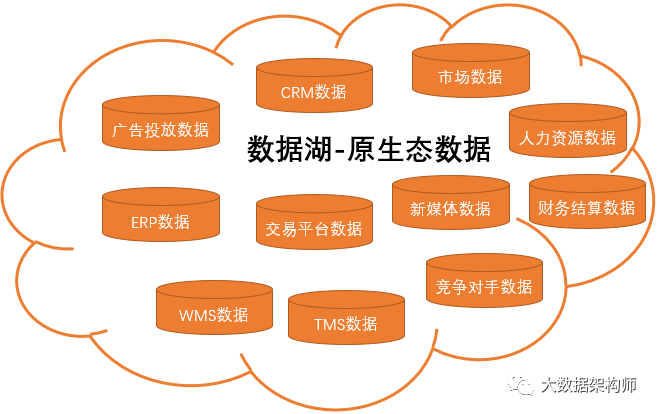
任何使用数据的同学都可以直接到数据湖中自由提取数据:
在多维分析报表中钻取到最细颗粒度之后仍然不能解决问题的,就到数据湖中查看最原始的数据,查找根因。
在进行算法设计的时候,数仓中处理的数据已经损失了一部分信息,那就去数据湖中找更详尽、更丰富的底层数据,没准可以找到最佳特征。
数据湖貌似非常完美,能解决一切问题,但是肯定哄不住专业的你。是的,数据湖说的好听,是一个原生态的,任由你汲取的巨型数据源,说的不好听,就是一个数据垃圾堆。不管你管理的多么好都无法改变这个事实。
你现在已经找到了一个异常客户,想找到这个客户在公司业务流中的表现。我们应该会通过CRM与其进行沟通和跟进;通过交易平台与其发生交易;货物是通过ERP进行采购的,通过WMS记录货物存储信息的,通过TMS记录货物运输过程信息的。最后你是在微博中收到了他的抱怨信息,在客服中心的CallCenter接到投诉电话的。
这个时候,你想怎么办?各个系统都是独立建设的,所有数据都在数据湖中,你就是没办法把他们串起来!而且,这还是一条业务线。公司通常都会有N条业务线,每个业务线的系统都统统单独建立一遍,一个客户与公司发生关系的系统越来越多。
这个时候,数据中台就出现了。

图片来自于阿里云数据中台解决方案手册
所以你可以看到,数据中台解决的是什么问题:
实体的打通和画像-OneID;
数据资产的统一构建与管理-OneModel;
数据服务的统一服务-OneService
这三点,共同组成了数据中台的OneData的方法论体系。
OneID是最底层的数据打通,把各条业务线、各个业务系统的相同实体(如客户)进行统一识别。用户端的感觉就是你用一个id,可以通行阿里系所有app。企业端的感觉就是无论用户用什么客户端,通过那个系统与企业发生关系,都能识别成为一个用户;
OneModel是中间层数据的统一建模,这里其实就是数据仓库。只不过不是一个业务线的数据仓库,是整个企业,整个集团的,统一的数据仓库。
OneService是业务层的统一服务提供,其实还是那一套,主数据、即席查询、固定报表、多维分析等等。当然会多一些算法层面的试探,也仅仅是试探而已。
我在之前的工作中,就曾建立数据中台,主要工作内容就是做商品id和用户id的打通,进行全局统一建模,提供统一的商品主数据的编码工作和统一的数据输出。
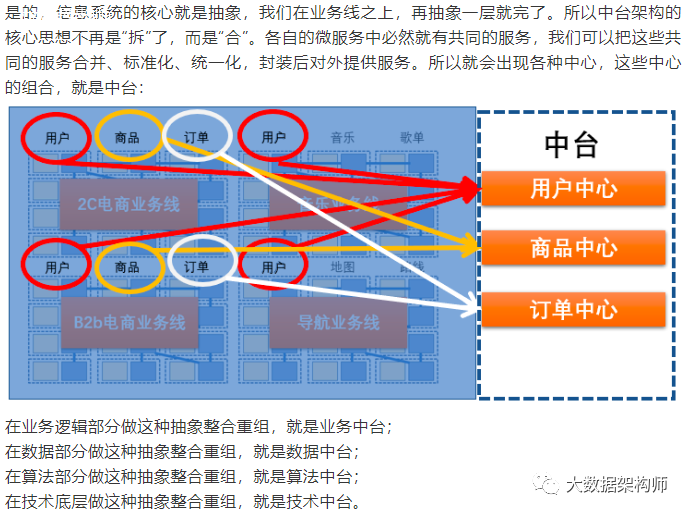
如上图所示,其实在上篇文章中,就已经说清楚数据中台是什么了。在数据层面进行多条业务线的服务合并、标准化、统一化,统一抽象,这就是数据中台。每个架构都是要解决特定的问题的,数据中台解决的核心问题就是全局统一,全局标准,全局打通。
所以,不要神话中台,更不要神话数据中台。你没有这个问题,或者说当前最紧急的问题不是中台最擅长解决的,那就不要跟风建中台。那样会死的很惨的。
以上,与君共勉!
来源:数据社




