

整体架构设计
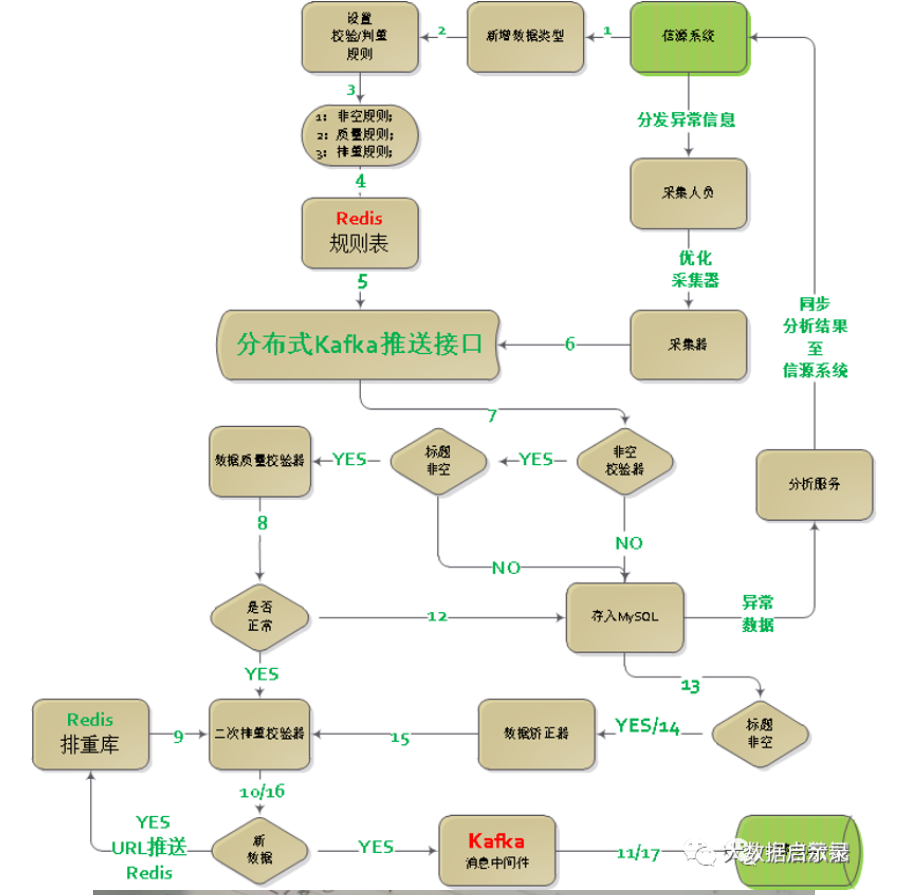
数据质量监控平台主要包括三个部分:数据层、功能层和应用层,平台架构如图1所示。
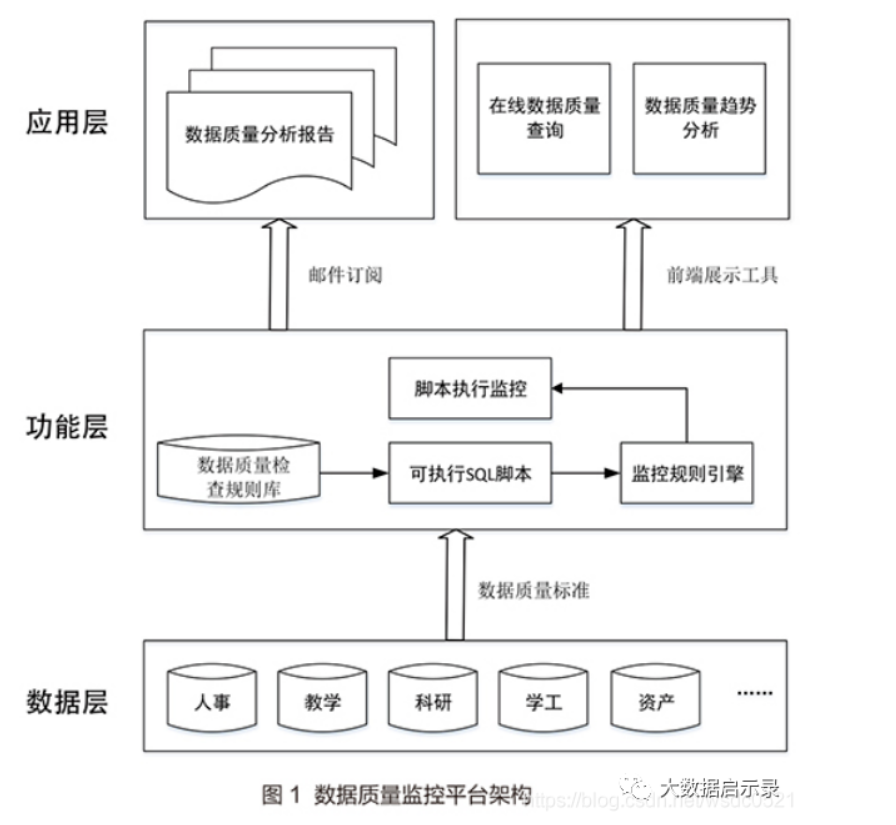
1.数据层
数据层定义了数据质量监控的对象,主要是各核心业务系统的数据,如人事系统、教学系统、科研系统、学生系统等。
2.功能层
功能层是数据质量监控平台的核心部分,包括数据质量检查规则的定义、数据质量检查规则脚本、检查规则执行引擎、数据质量检查规则执行情况监控等。
3.应用层
数据质量检查结果可以通过两种方式访问:一种是通过邮件订阅方式将数据质量检查结果发给相关人员,另一种方式利用前端展示工具(如MicroStrategy、Cognos、Tableau等)开发数据质量在线分析报表、仪表盘、分析报告等。前端展示报表不仅能够查看汇总数据,而且能够通过钻取功能查看明细数据以便业务人员能够准确定位到业务系统的错误数据。
规则库设计与梳理

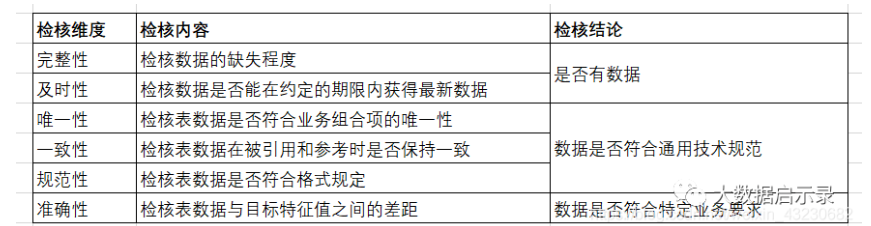
常见规则库逻辑实现示例:
如规则一:字段值长度小于阈值A
public Boolean isALengthLtB(MonitorRule mr, MonitorRuleRelation mrr,Object oneData) {
//判断A字段及A阀值不为空
if (!StringUtils.isNotBlank(mrr.getInterAField())|| !StringUtils.isNotBlank(mrr.getThresholdA()))
return false;
Object aFieldValue = Reflect.getObjectXField(oneData, mrr.getInterAField());
//阀值A必须为数字;
if (!BooleanRegular.isNumber(mrr.getThresholdA()))
return false;
//判断字段A的值不为空;
if (!StringUtils.isNotBlank(aFieldValue)) return false;
Double value = Double.parseDouble(mrr.getThresholdA());
if (aFieldValue.toString().length() < value.intValue())
return true;
return false;
如规则19:A字段时间大于B字段时间,则A字段值=B字段值
public Object aGTb(MonitorRule mr, MonitorRuleRelation mrr, Object oneData) {
if (!StringUtils.isNotBlank(mrr.getInterAField())|| !StringUtils.isNotBlank(mrr.getInterBField()))
return oneData;
Object a = Reflect.getObjectXField(oneData, mrr.getInterAField());
Object b = Reflect.getObjectXField(oneData, mrr.getInterBField());
if (!StringUtils.isNotBlank(a) || !StringUtils.isNotBlank(b)) // 不为空
return oneData;
if (!BooleanRegular.isDate(a.toString()) || !BooleanRegular.isDate(b.toString()))
return oneData;
// 必须是19位时间格式;
if (a.toString().length() == 19 && b.toString().length() == 19) {
long aLong = DateUtil.stringToLong(a.toString(),
DateUtil.year_month_day_hour_mines_seconds);
long bLong = DateUtil.stringToLong(b.toString(),
DateUtil.year_month_day_hour_mines_seconds);
if (aLong > bLong) {
oneData = Reflect.setObjectXField(oneData,mrr.getInterAField(), b);
}
}
return oneData;
} 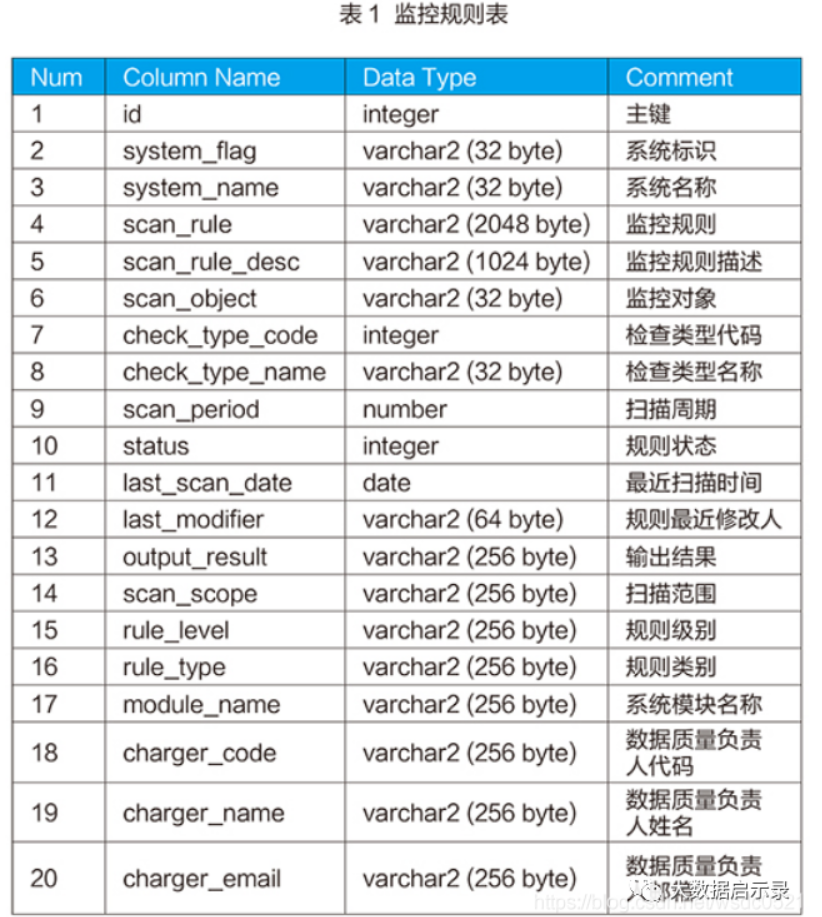
system_flag:系统标识,用来标记监控规则属于哪个业务系统。
scan_rule:监控规则,是可执行的SQL脚本,监控规则主要分两类,一类是单纯的数据校验规则,如检查是否为NULL、是否与字典表一致等;另一类是业务校验规则,有些数据从数据库角度出发是没有问题的,但是不一定符合业务逻辑,如项目的结项时间早于立项时间等。
scan_rule_desc:监控规则描述信息,用来准确说明监控规则脚本的检查内容、检查逻辑等信息,供业务人员和技术人员详细了解监控规则含义。
scan_object:监控对象,用来说明监控规则检查的数据对象或业务实体。
check_type_name:检查类型名称,指监控规则检查数据质量的哪一种问题,如完整性、有效性、准确性、唯一性、一致性、合理性。
scan_period:扫描周期,指该监控规则执行的频率,如每天、每周、每月。
status:规则状态,指该监控规则是否启用,1表示启用,0表示关闭,监控引擎不会执行已经关闭的规则。
last_scan_date:最近扫描时间,记录该规则上一次执行时间,用来和扫描周期联合计算当前时间该监控规则是否可执行。
output_result:输出结果,指监控规则执行后输出的内容,让数据质量管理人员准确知道是什么数据存在问题,方便在业务系统中查找、修改。
scan_scope:扫描范围,指监控规则扫描哪些业务数据,有并不是所有的业务数据都需要去检查,扫描范围在监控规则脚本中也有相应的体现。
rule_level:规则级别,指该监控规则对应的数据质量问题对业务的影响程度,一般可分为高、中、低三个级别,高级别的数据质量问题必须在第一时间解决,否则会影响业务的正常开展。
module_name:系统模块名称,指监控规则对应业务系统中哪个功能模块,主要用来将问题数据按系统功能模块来分类。
charger_email:数据质量负责人邮箱,可以将该规则检查的结果发生到负责人邮箱中,方便查看问题数据。
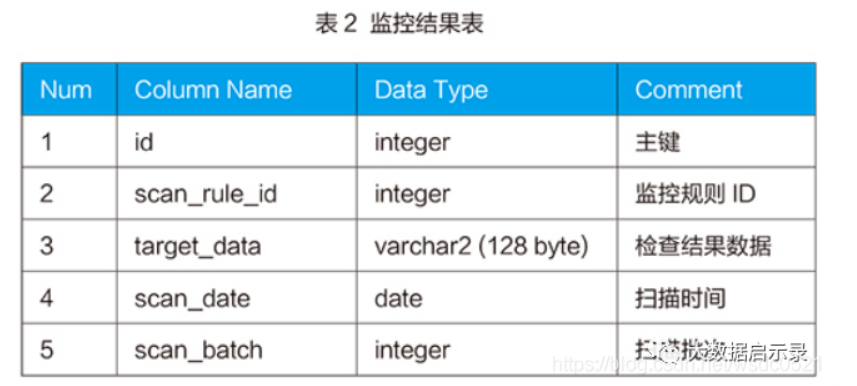
表2是监控结果表的数据结构,该表用来存放某监控规则在相应的扫描时间点检查出来的结果数据,通过scan_rule_id与监控规则表相关联就能知道结果数据的详细信息。
表3是监控规则库中教学系统相关的一些监控规则实例,由于排版问题只列出规则的核心字段。
规则的计算与解析
很多时候我们会将规则,以表达式的形式存储在数据库中,这样有利于动态增减规则和动态修改,能够更方便的维护起来。但通常这种规则表达式的格式和存储要求就变得较为灵活。一般来说,java代码是无法自动识别和解析该规则的。因此将规则表达式转换为可执行的java代码变显得尤为重要。推荐使用规则引擎来完成对于规则表达式的转换和解析。如:drools、easyRules、
esper、groovy、Aviator、Jexl...
监控引擎(定时任务)
监控引擎是数据质量监控平台的发动机,负责执行监控脚本并产生监控结果,监控引擎是一个可供调度程序定时执行的存储过程,需要部署在一个具有读取其他业务库的数据库用户下,监控引擎执行流程如图2所示,具体执行过程说明如下:
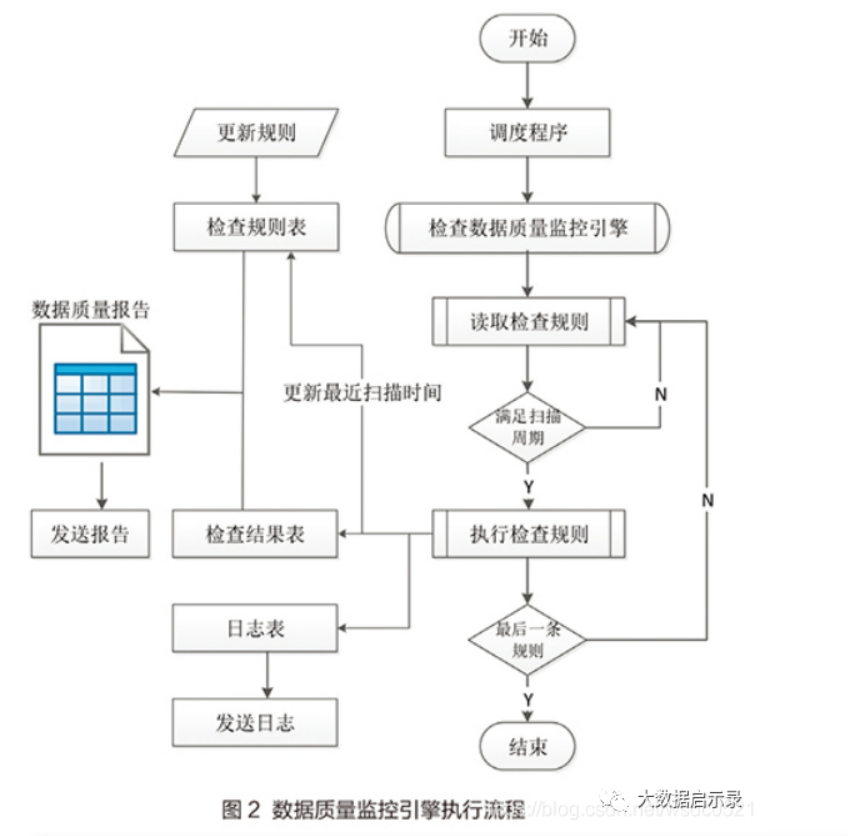
1.通过调度程序定时触发监控引擎执行,监控引擎可以根据实际情况灵活设置调度时间,一般设置在凌晨调度,减少对业务系统的影响。
2.监控引擎顺序读取规则库中的数据质量检查规则,判断规则是否有效、判断规则是否满足扫描周期。满足条件后执行检查规则,并将检查结果输出到结果表中。
3.一条规则执行完成后,更新该规则的last_scan_date(最近扫描时间)字段。
4.将监控规则执行是否成功记录到日志表,尤其是执行失败的规则,并将日志发送给系统管理员,以便及时修复问题。
5.执行完最后一条规则结束监控引擎的一次运行,同时将检查结果以报告的形式发送给相关业务人员。
数据推送统一接口逻辑处理
一般来说我们会将满足触发规则,并且进行处理后的数据写入kafka,处理的结果有时候会是告警聚合结果,但也有时候会是告警明细详情记录。因此topic该存储些什么也需要根据业务要求和场景来决定。
① 接口服务ID
② 接口名称(方法名)
③ 接口接受请求时间
④ 推送结束时间
⑤ 接口接受数据量
⑥ 校验异常数据量
⑦ 推送kafka成功量
⑧ 推送kafka失败量
⑨ Kafka的Topic名称
⑩ 推送人(信源系统用户ID):以便快速定位采集人
⑪ 采集器ID:以便快速定位采集器,查询相关问题
或者:
jobId
vin码
事件名称
告警时间
监控类型
告警类型
告警的阈值规则与触发,及告知方式
无论存放在kafka里的数据是告警聚合值还是告警明显详情记录,一般情况下我们也不会直接通过邮件或飞书货打电话直接告知相关责任人。通常都是某些告警结果或者告警记录到达了一定的阈值条件或规则条件,才会真正的将告警信息通过邮件/飞书/电话等方式通知到相关责任人。
来源:大数据启示录




