

导读:大家好,今天分享的主题是腾讯数据湖的元数据治理实践,跟大家一起聊聊腾讯云上DLC数据湖计算产品中统一元数据的设计思路和实践经验,希望能给大家带来一些参考。
本文的内容主要包括四部分:首先是对什么是数据湖进行背景概述,介绍腾讯数据湖的整体架构,以及统一元数据模块的详细架构实现;第二部分介绍腾讯云上元数据多租户的设计模式,最后介绍统一元数据的两大核心能力:在线数据目录和离线数据治理的功能。
01
什么是数据湖
随着Snowflake公司股价高歌猛进和各大云厂商的推广,数据湖已成为近2、3年来大数据领域的新贵之一,而什么是数据湖,数据湖与数据仓库之间的竞争和融合,各家云厂商和数据平台都有自己的解读。从定义来看,数据仓库是1990年由数仓之父Bill Inmon提出,是面向主题的、集成的、相对稳定的、反映历史的数据集合,为上层提供管理决策;而数据湖概念最早是2010年由Pentaho CTO James Dixon提出,是存储各类自然格式数据的系统,提供数据ETL操作。
以我的理解,数据仓库和数据湖可分别看作是分而治之和无为而治。
数据仓库:具有标准的数据模型和数据分层,包括ODS操作数据层,CDM通用数据模型层,ADS数据应用层,而每层又可以进行细分;数据仓库仅支持结构化数据,在写入数据文件时,必须提前定义好数据的Schema结构;数据仓库的整体数据质量较高,但随之而来的构建成本较大且仅支持特定计算引擎。
数据湖:无需提前设计好数据模型和数据分层,支持结构化和半结构化数据,在数据读取操作时,才需要确定出数据的Schema结构;相比于数据仓库,数据湖的整体数据质量较低,但其构建成本较小,且支持多样化的计算引擎进行数据分析。

以腾讯数据湖计算DLC为例,数据湖的整体优势可以分为:高效性、低成本、易扩展。
高时效:可基于表格式,使用Iceberg提供行级数据操作,可将传统的大数据数仓时延从小时级别降低到分钟级别;可基于存储缓存,使用Alluxio提供本地的分层存储,加速计算。
低成本:相比于传统的HDFS,腾讯云上对象存储COS的计费更加低廉,用户只需为实际存储的数据买单,天然适合云原生场景。提供数据湖Serverless计算能力,可基于云上EKS对计算资源进行动态扩缩容,让用户无需购买整套EMR集群就能实现海量的数据分析。
易扩展:使用存算分离架构,可解耦计算资源和存储资源的扩缩容;可扩展支持多样化的计算引擎,目前已支持Presto和Spark进行计算分析。
数据湖在灵活性的优势下,也需要更好的管理能力,包括数据建模能力和数据治理能力,而各厂商也纷纷提出湖仓一体的概念,将数据湖和数据仓库进行整合,更好的根据实际需求寻找两者的平衡。
02
腾讯数据湖和腾讯统一元数据治理框架
腾讯数据湖的整体架构如下图所示,可以简单理解为3+2架构,由数据湖的三大基本组成要素和两大关联模块构成。
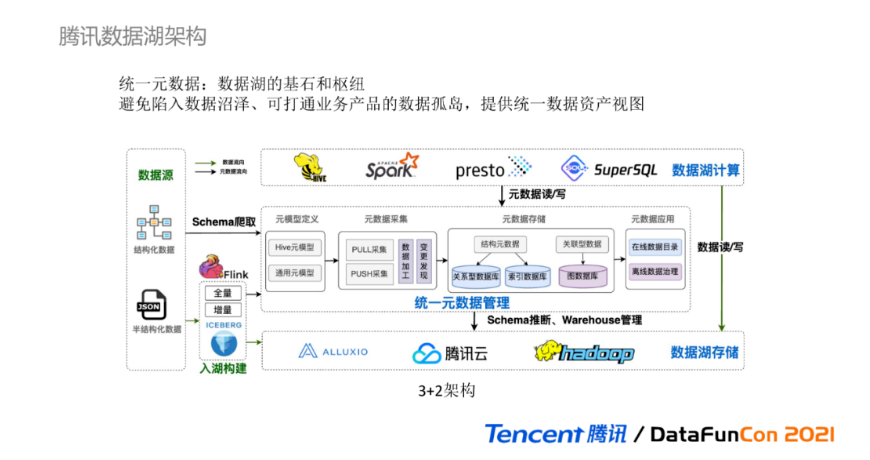
首先来看数据湖的三大基本组成要素:
数据湖存储:提供海量异构数据的存储能力,具备低成本、高可用、可弹性伸缩。DLC基于腾讯云对象存储COS作为主要数据湖存储,搭配Alluxio进行数据编排和分层缓存,同时也支持云上EMR HDFS扩展存储;
数据湖计算:以Serverless无服务的形式提供高效敏捷的计算分析。DLC支持基于Presto实现即席分析,基于Spark实现数据ETL批处理、基于腾讯SuperSQL实现联邦跨源分析;
统一元数据:提供云上统一的在线数据目录和离线数据治理能力,主要有四个部分构成:
元模型定义:是对元数据的抽象描述,定义了Hive元模型和通用元模型;
元数据采集:支持基于PULL定时拉取和PUSH主动上报的两种方式采集元数据,并对原始元数据进行加工处理;
元数据存储:根据不同元数据的数据结构和用途,选择存放在不同类型的数据库中,目前使用了关系型数据库、索引数据库、图数据库;
元数据应用:分为在线数据目录和离线数据治理两类功能模块,在线数据目录可为数据湖的计算引擎提供Schema管理功能,而离线数据治理可为数据湖提供资产管理能力。
两大关联模块包括:
异构数据源:为数据湖提供生产资料来源,支持结构化数据,如腾讯云上EMR HIve,CDB、CDW等数据库来源,同时也支持半结构化数据,如Json文本、Log日志等;
入湖构建:为数据湖提供便捷的数据入湖集成能力,基于Iceberg表格式和Flink,可实现全量和增量的数据导入集成功能。
在整个架构图中,由黑色箭头的元数据流向可以看出,统一元数据是整个数据湖的基石和枢纽,发挥着承上启下的关联作用,承上对接数据湖计算引擎,启下对接数据湖存储,可通过元数据采集从异构数据源进行Schema数据结构爬取,而数据的Schema信息又可以为入湖构建提供基本的元数据资料。元数据中的Schema管理和数据治理,提升和保证了数据湖的数据质量,避免陷入数据沼泽,同时统一元数据可以整合不同的业务场景提供统一的数据管理视图,打通各业务的数据孤岛。
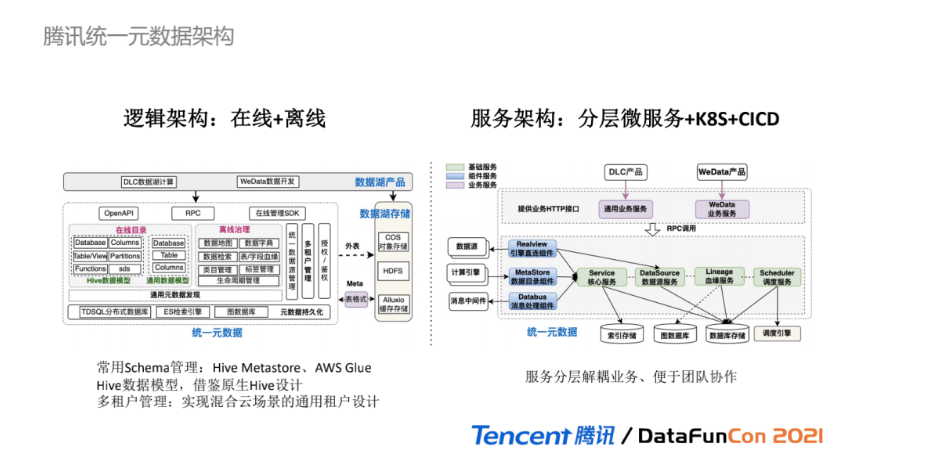
下面来看腾讯统一元数据的模块详细架构,其中系统逻辑架构如图所示,有两大核心功能:在线数据目录和离线数据治理。
在线目录:提供元数据Schema管理能力,可类比Hive Metastore或AWS Glue 组件,对接计算引擎提供元数据信息。根据具体的使用场景和服务定位,我们放弃了更具灵活性但又更复杂的元元模型管理,定义了两类:Hive数据模型和通用数据模型。Hive数据模型参考原生Hive的数据结构设计,通过定义DB、表、UDF Function、字段、分区、存储描述,使得在线目录功能尽可能与SQL-on-Hadoop的计算引擎无缝对接;而通用模型通过定义DB、表、字段,可适配基本的数据治理能力。
离线治理:提供丰富的元数据管理应用,包括数据地图、数据字典、数据检索、表/字段级别血缘、类目管理、标签管理、生命周期管理等功能。除在线和离线核心功能外,多租户管理实现混合云场景的通用租户设计,使得统一元数据可适配不同场景。
系统服务架构如右图所示,基于分层微服务、k8s容器化、CICD持续集成和部署实现云原生的服务架构,统一元数据的服务分为三层:
基础服务:与数据库存储对接,提供基础的元数据管理能力,包括核心服务、数据源服务、血缘服务、调度服务;
组件服务:以服务进程的形式提供组件化功能,仅调用基础服务提供的接口,不与数据库直接对接,包括引擎直连组件、数据目录组件、消息处理组件;
业务服务:提供HTTP接口与具体的业务产品交互,根据每个业务的独特性,可分别提供不同的业务服务。
这样的分层设计,保证基础服务和组件服务的通用性,尽可能与个性化业务场景解耦。同时在团队开发实践中,也便于不同团队协作,业务团队可快速的参与到具体的业务开发中。
03
租户设计:介绍腾讯云上的元数据租户
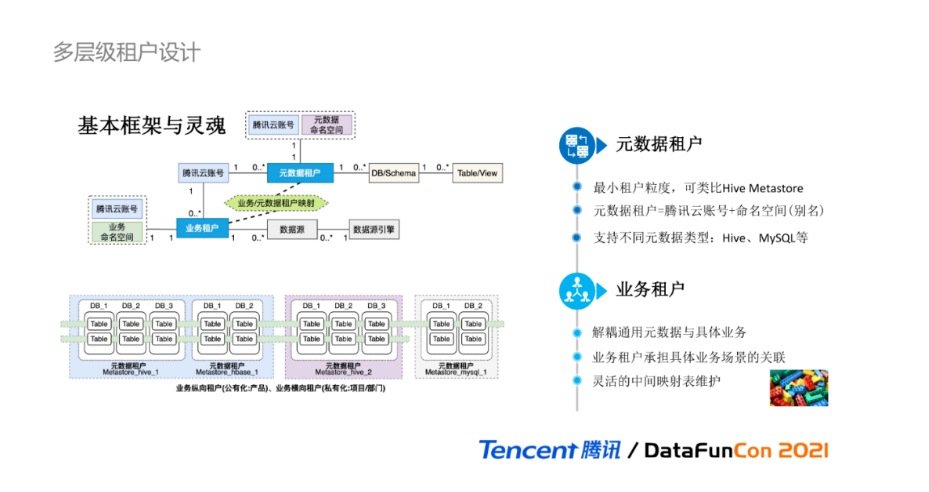
元数据中多层级的租户设计是整个系统的基本框架与灵魂,所有的实现逻辑都会以此为基础进行叠加。虽然这个领域模型看起来比较朴素和简单,但在设计之初,我们团队内部讨论了蛮久才最终确定的。抽象出元数据租户和业务租户两个层级维度的租户级别,来架构元数据的基本能力和满足不同的业务需求,如联邦多Catalog管理,多业务的元数据打通。
元数据租户是系统中的最小租户粒度,可涵盖完备的元数据Schema信息,不同元数据租户是相互独立隔离的。一个元数据租户可类比为一个Hive Metastore,元数据租户与数据库DB是一对多的关系。一个腾讯云账号下对应多个元数据租户,可以适配多Catalog管理场景。为便于计算引擎和外部服务的接口调用,同个腾讯云账号下,可定义不重名的元数据命名空间作为别名来使用,与元数据租户一一对应。元数据租户是抽象逻辑概念,可支持不同的元数据类型,如Hive、MySQL等。
业务租户的设计初衷是为了解耦通用元数据与具体业务的强关联关系,使得底层元数据租户与具体的业务是无关的,由业务租户承担具体业务场景的关联与维护。数据源一般由业务使用方提供的,因此设计为与业务租户相关,一个业务租户可对应多个数据源。需要特别关注的是:元数据租户与业务租户本身没有直接且明确的关联关系,它们的关系由中间映射表维护,该映射关系是灵活的,由具体的业务逻辑决定的,不同业务场景使用的中间映射表不同,新增一种新业务类型,仅需扩展中间映射关系表。
业务租户与元数据租户的映射关系,可以分为两类的划分:
纵向划分:可用于公有云场景,从纵向对元数据租户进行合并划分,一个业务租户对应一个云上产品,每个产品之间元数据是逻辑隔离的,而从腾讯云账号这个更高维度,又可对多个业务产品进行孤岛元数据的打通;
横向划分:可用于私有云场景,从横向对元数据租户进行共享及拆分,一个业务租户对应一个公司部门,所有部门都共享一个私有化集群和元数据租户,部门之间通过DB维度进行隔离,则中间表维护部门、元数据租户和DB名称的关系。
04
功能模块 - 在线目录
下面我们进入统一元数据的第一个核心功能模块:在线数据目录。在业界方案中,Hive Metastore是Hadoop生态圈中数据目录管理的事实标准,为SQL on Hadoop的分析计算引擎提供通用的Schema管理能力。在DLC数据湖计算场景中,为保证计算引擎与统一元数据能够最小成本的无缝对接,我们首先考虑的是如何进行Hive Metastore的改造实现,提供保持一致的Metastore RPC接口,让计算引擎对底层元数据的服务形态零感知。
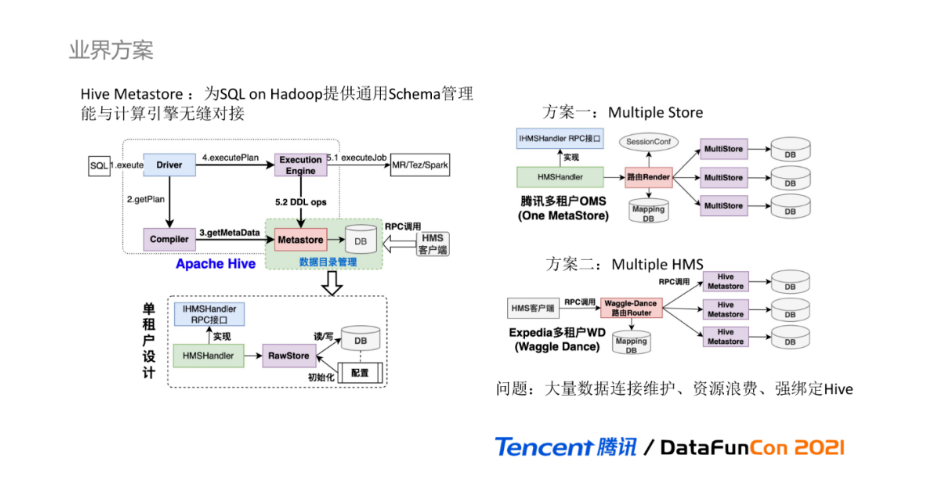
首先来大致回顾Hive执行的流程:由Driver触发SQL解析,Compiler编译器进行编译解析获取逻辑计划对象,会基于Hive Metastore RPC接口获取Schema元数据信息,用于校验和丰富逻辑计划对象。逻辑计划转换为可执行的物理计划,由Execution Engine执行引擎触发执行,其中若涉及元数据变更操作,会调用Hive Metastore RPC接口进行元数据变更,并最终将元数据信息持久化到RDBMS。Hive Metastore是典型的单租户设计,不同用户之间Schema无法完全隔离,无支持创建重名数据库。Hive Metastore的内部设计要点是基于HMSHandler类完全实现IHMSHandler类定义的RPC接口,HMSHandler基于RawStore类从配置中加载持久层的数据库连接信息并初始化,最终数据元数据读写操作由RawStore基于JDO框架实现。
为扩展和支持Hive Metastore实现多租户的能力,业界有不同的实现方案,主要分为两类。
方案一:以腾讯多租户OMS的实现为例,通过侵入修改Hive Metatsore的源码,在HMSHandler连接RawStore之间新增路由管理器,从RPC连接的Session配置获取连接标识,根据标识,从映射DB中获取具体的JDBC连接信息并初始化,最终由对应的MultiStore完成元数据读写操作,多租户实现可理解为多个连接存储MultiStore。
方案二:以Expedia公司的WD(Waggle Dance)实现为例,在Hive Metastore之外增加路由管理服务,用户调用路由服务提供的RPC接口,通过配置从映射DB中,将RPC请求路由转发到真正的Hive Metastore上,多租户实现可理解为多个Hive Metastore。虽然方案二对原生Hive Metastore侵入性较小,但也增多了一层请求链路。
以上两种方案都不适用于公有云数据湖场景。首先,两种多租户方案底层都是通过绑定独立的数据库连接实现,一个租户即为一个独立的数据库连接,需要进行大量的数据库连接管理;其次,公有云场景会存在很多长尾试用用户,大量的非活跃用户会造成数据库资源的浪费;最后,两种方案都与Hive Metastore的数据模型和实现逻辑强绑定,对于实现数据治理功能,存在很硬性的限制条件。
我们最终选择的实现方案是重新实现Hive Metastore RPC接口,大致的实现流程如图所示:新增自定义Handler类继承IHMSHandler,完全重新实现Thrift文件RPC接口。内部增加RPC认证鉴权操作,并最终对外提供RPC Server服务。自定义Handler主要负责处理Metastore逻辑和数据转换操作,真正的元数据持久化通过服务间RPC调用最终由元数据基础服务完成。在线目录除提供完全兼容Hive Metastore的RPC接口外,还提供了HTTP接口供不同的产品使用。该实现方案虽然具有很强的灵活性,但整体实现和维护成本偏高,并不适合所有场景。
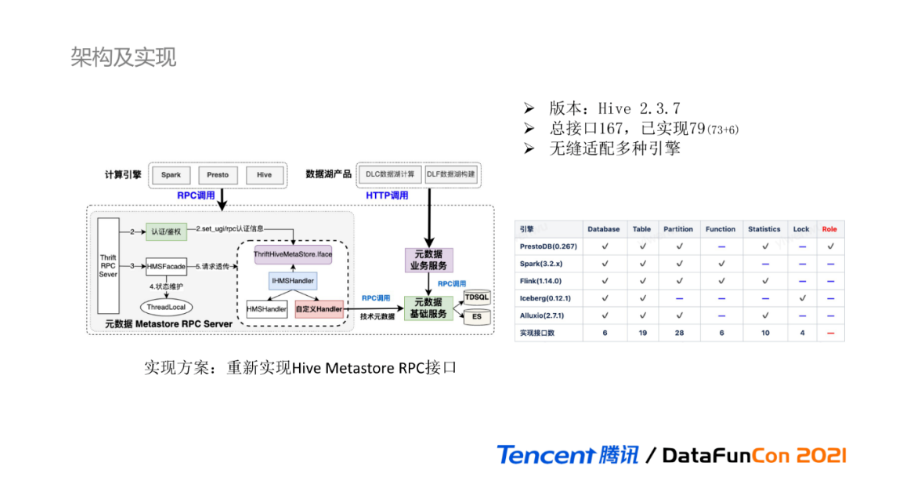
目前自研的元数据Metastore构建在Hive 2.3.7版本之上,RPC文件定义的接口总数有167个,已实现接口数79个,主要包括六类:数据库、数据表、分区、自定义UDF、统计元数据、事务锁,已具备无缝对接多引擎的能力。我们已上线并适配使用的引擎有PrestoDB、Spark、Flink、Iceberg、Alluxio。每个引擎所使用到的接口范围如上表所示,蓝色横线代表该引擎不会调用这类RPC接口。
因为选择使用完全重写的方案,我们可以基于Metastore进行深度优化。对于数据模型,我们在Hive Metastore的原生模型之上进行二次抽象和简化,核心模型由12个减少到6个,主要的改造包括:① 去除PARAMS表:将KV的配置参数关联表以Json字符串的形式作为数据模型的一个字段;② 统一模型:将分区字段与非分区字段统一成一个数据模型;③ 简化SDS:简化存储描述SDS相关联的数据模型;④ 租户维护:DB和Table之上增加了元数据租户的字段维护。
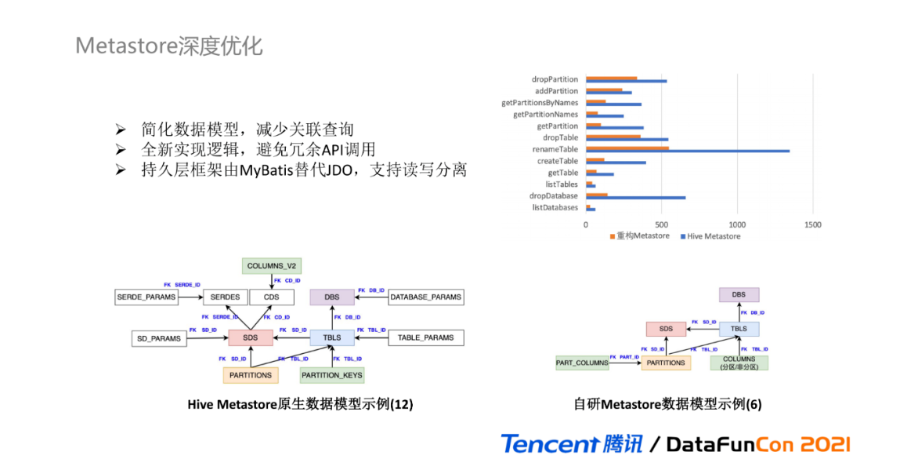
简化后的数据模型,可以减少大量的数据库关联查询,而全新的实现逻辑,从根源上减少了冗余API的调用并进行执行逻辑优化;持久层框架由更灵活的Mybatis替代JDO,支持基于数据库的读写分离。该图展示了100次接口重复调用下,库、表、分区的各接口的耗时对比,可以看出重构后Metastore的耗时远低于原生Hive Metastore耗时。
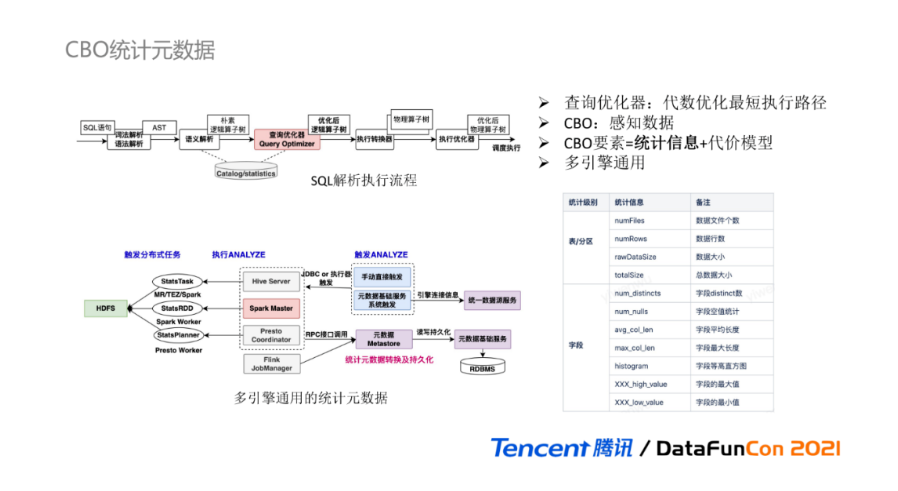
对于在线数据目录,除了提供Schema管理外,还提供了通用的统计元数据,为CBO优化器助力。首先简要回顾下SQL的解析执行流程,SQL语句经过词法/语法和语义解析后,获得朴素的逻辑算子树,经过查询优化器的代数逻辑优化,获取其中最短执行路径的逻辑算子树,最后逻辑算子树转换为物理算子树并提交执行引擎。
查询优化器是SQL引擎的重点核心能力,常见的优化器有基于规则的RBO优化器和基于代价的CBO优化器,其中CBO优化器可通过感知数据来调整执行计划,在大数据领域更受欢迎。CBO的要素由统计信息和代价模型构成,为加速计算优化,统一元数据提供多引擎通用的统计元数据功能,支持表、分区、字段级别的统计元数据,具体各级别的统计信息如下表所示。
多引擎通用统计元数据的实现流程大致如下:Hive、Spark、Presto支持ANALYZE语句,通过执行ANALYZE分布式任务,计算出统计元数据,计算引擎调用元数据Metastore接口持久化统计元数据。但存在的一个问题:不同的计算引擎使用的统计元数据读写接口可能不同。元数据Metastore作为中转层,会根据计算引擎类型进行转换处理,使得统计元数据对于不同引擎都是通用性。如Presto计算出的统计元数据,在Spark执行SQL,可直接获取对应统计信息进行CBO优化,而无需再次ANALYZE计算。
05
功能模块 - 数据治理
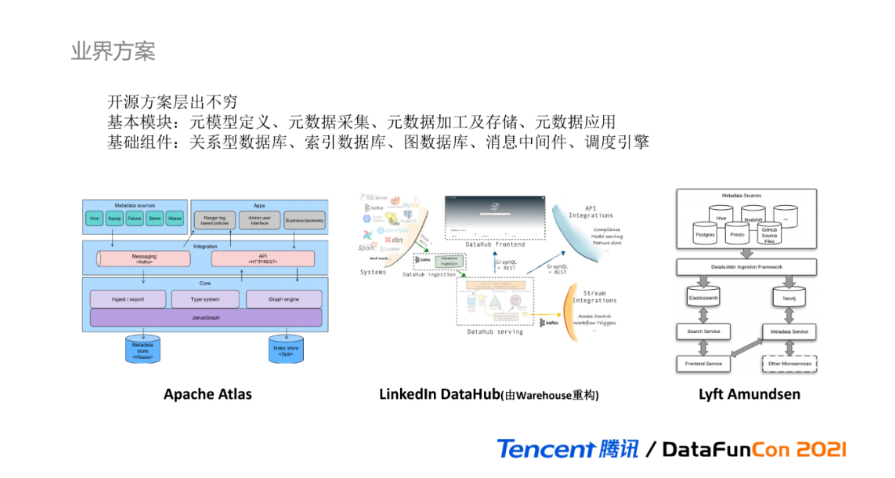
最后进入统一元数据的第二个核心功能模块:离线数据治理。针对元数据治理,各类开源方案在业界层出不穷,这里列举了几个业内比较流行的元数据管理组件:
Apache Atlas:是基于Hadoop之上的元数据管理框架,主要以计算引擎Hook的方式,来获取元数据信息,并提供基本的元数据应用管理;
LinkedIn DataHub:是LinkedIn Warehows的前身,提供元数据搜索及集成功能;
Lyft Amundsen:最近比较热门的元数据管理系统之一,由lyft开源的数据发现平台。
基于业界方案调研,可以总结出以下规律:
开源的数据治理产品也在不断迭代更新:从单体服务到分层服务,到以消息驱动为主,很多主流的元数据管理系统,会采用消息中间件来解耦数据采集和数据加工,使得系统更具通用性。新增的异构数据源,仅需按照规定的消息格式发送元数据到消息中间件,元数据就可以被系统进行加工处理;
完整的数据治理系统可以分为四个基本模块:元模型定义、元数据采集、元数据加工及存储、元数据应用;
数据治理服务常用的基础组件有:关系型数据库,用于元数据存储;索引数据库,用于数据检索的;图数据库,用于关联数据存储,如数据血缘或者元数据实体;消息中间件,用于解耦元数据操作;调度引擎,用于执行采集任务。
以Atlas为例,元模型定义在Core模块Type System中实现;元数据采集在Integration集成模块接收元数据Hook消息并生产到消息中间件;元数据加工及存储在Core模块处理,基于Graph Engine持久化;元数据应用在Apps模块中使用;使用Kafka作为消息中间件,使用ES索引数据库进行数据检索;使用JanusGraph图数据库进行元数据实体存储,而血缘消息也作为其中一类元数据实体。
下表展示了各个开源系统与腾讯元数据治理功能的对比,其中腾讯元数据的项目代号为Hybris,可以看出腾讯统一元数据已具备丰富的数据治理能力。除功能的完整性对比外,按照我们的以往经验,开源的数据治理系统在实际业务中很难直接的使用起来,因为数据治理是与业务领域和形态密切相关,直接使用具有一定抽象性且通用的开源系统,只能获取比较基础的数据治理能力,很难得到业务相关的数据价值。若与业务结合,则需要对开源系统进行深度改造的二次开发,因此在数据治理部分我们也选择完全自研。
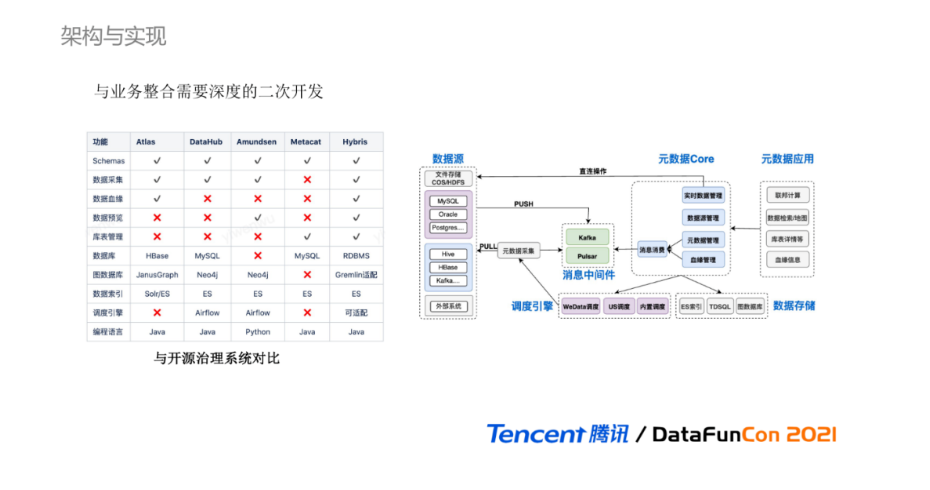
数据治理的整体架构:在公有云场景,由调度引擎触发离线采集调度任务,通过PULL定时拉取的爬虫方式采集异构数据源的元数据信息,并将元数据发送到消息中间件;元数据Core中的元数据管理和血缘管理通过消息消费获取对应的元数据进行加工处理,并将元数据持久化到数据库。除离线采集外,也提供了直接数据源引擎获取实时元数据和进行库表管理的操作。最终由元数据应用功能提供多样化的治理功能。
来源:志明与数据
作者:吴怡雯




