

01
数据仓库选型
数据仓库选型是整个数据中台项目的重中之重,是一切开发和应用的基础。而数据仓库的选型,其实就是Hive数仓和非Hive数仓的较量。Hive数仓以Hive为核心,搭建数据ETL流程,配合Kylin、Presto、HAWQ、Spark、ClickHouse等查询引擎完成数据的最终展现。而非Hive数仓则以Greenplum、Doris、GaussDB、HANA(基于SAP BW构建的数据仓库一般以HANA作为底层数据库)等支持分布式扩展的OLAP数据库为主,支持数据ETL加工和OLAP查询。
自从Facebook开源Hive以来,Hive逐渐占领了市场。Hive背靠Hadoop体系,基于HDFS的数据存储,安全稳定、读取高效,同时借助Yarn资源管理器和Spark计算引擎,可以很方便地扩展集群规模,实现稳定地批处理。Hive数据仓库的优势在于可扩展性强,有大规模集群的应用案例,受到广大架构师的推崇。
虽然Hive应用广泛,但是其缺点也是不容忽视的。
Hive的开源生态已经完全分化,各大互联网公司和云厂商都是基于早期的开源版本进行个性化修改以后投入生产使用的,很难再回到开源体系。Hive现在的3个版本方向1.2.x、2.1.x、3.1.x都有非常广泛的应用,无法形成合力。
开源社区发布的Hive版本过于粗糙,漏洞太多。最典型的就是Hive 3.1.0版本里面的Timestamp类型自动存储为格林尼治时间的问题,无论怎么调整参数和系统变量都不能解决。据HDP官方说明,需要升级到3.1.2版才能解决。根据笔者实际应用的情况,Hive 3.1.2版在大表关联时又偶尔出现inert overwrite数据丢失的情况。
Hive最影响查询性能的计算引擎也不能让人省心。Hive支持的查询引擎主要有MR、Spark、Tez。MR是一如既往的性能慢,升级到3.0版也没有任何提升。基于内存的Spark引擎性能有了大幅提升,3.x版本的稳定性虽然也有所加强,但是对JDBC的支持还是比较弱。基于MR优化的Tez引擎虽然是集成最好的,但是需要根据Hadoop和Hive版本自行编译,部署和升级都十分复杂。
Hive对更新和删除操作的支持并不友好,导致在数据湖时代和实时数仓时代被迅速抛弃。
Hive的查询引擎也很难让用户满意,最典型的就是以下查询引擎。
1)Spark支持SQL查询,需要启动Thrift Server,表现不稳定,查询速度一般为几秒到几分钟。
2)Impala是CDH公司推出的产品,一般用在CDH平台中,查询速度比Spark快,由于是C++开发的,因此非CDH平台安装Impala比较困难。
3)Presto和Hive一样,也是Facebook开源的,语法不兼容Hive,查询速度一般为几秒到几分钟。
4)Kylin是国人开源的MOLAP软件,基于Spark引擎对Hive数据做预算并保存在Hbase或其他存储中,查询速度非常快并且稳定,一般在10s以下。但是模型构建复杂,使用和运维都不太方便。
5)ClickHouse是目前最火的OLAP查询软件,特点是查询速度快,集成了各大数据库的精华引擎,独立于Hadoop平台,需要把Hive数据同步迁移过去,提供有限的SQL支持,几乎不支持关联操作。
以Hadoop为核心的Hive数据仓库的颓势已经是无法扭转的了,MapReduce早已被市场抛弃,HDFS在各大云平台也已经逐步被对象存储替代,Yarn被Kubernetes替代也是早晚的事。
我们把视野扩展到Hive体系以外,就会发现MPP架构的分布式数据库正在蓬勃发展,大有取代Hive数仓的趋势。
其中技术最成熟、生态最完善的当属Greenplum体系。Greenplum自2015年开源以来,经历了4.x、5.x、6.x三个大版本的升级,功能已经非常全面和稳定了,也受到市场的广泛推崇。基于Greenplum提供商业版本的,除了研发Greenplum的母公司Pivotal,还有中国本地团队的创业公司四维纵横。此外,还有阿里云提供的云数据库AnalyticDB for PostgreSQL、百度云FusionDB和京东云提供的JDW,都是基于Greenplum进行云化的产品。华为的GaussDB在设计中也参考了Greenplum数据库。
OLAP查询性能最强悍的当属SAP商业数据库HANA,这是数据库领域当之无愧的王者。HANA是一个软硬件结合体,提供高性能的数据查询功能,用户可以直接对大量实时业务数据进行查询和分析。
HANA唯一的缺点就是太贵,软件和硬件成本高昂。HANA是一个基于列式存储的内存数据库,主要具有以下优势。
把数据保存在内存中,通过对比我们发现,内存的访问速度比磁盘快1000000倍,比SSD和闪存快1000倍。传统磁盘读取时间是5ms,内存读取时间是5ns。
服务器采用多核架构(每个刀片8×8核心CPU),多刀片大规模并行扩展,刀片服务器价格低廉,采用64位地址空间—单台服务器容量为2TB,100GB/s的数据吞吐量,价格迅速下降,性能迅速提升。
数据存储可以选择行存储或者列存储,同时对数据进行压缩。SAP HANA采用数据字典的方法对数据进行压缩,用整数代表相应的文本,数据库可以进一步压缩数据和减少数据传输。
百度开源的Doris也在迎头赶上,并且在百度云中提供云原生部署。Apache Doris是一款架构领先的MPP分析型数据库产品,仅须亚秒级响应时间即可获得查询结果,高效支持实时数据和批处理数据。Apache Doris的分布式架构非常简洁,易于运维,并且支持10PB以上的超大数据集,可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。Apache Doris支持AGGREGATE、UNIQUE、DUPLICATE三种表模型,同时支持ROLLUP和MATERIALIZED VIEW两种向上聚合方式,可以更好地支撑OLAP查询请求。另外,Doris也支持快速插入和删除数据,是未来实时数仓或者数据湖产品的有力竞争者。
尝试在OLTP的基础上融合OLAP的数据库TiDB、腾讯TBase(云平台上已改名为TDSQL PostgreSQL版)、阿里的OceanBase都在架构上做了大胆的突破。TiDB采用行存储、列存储两种数据格式各保存一份数据的方式,分别支持快速OLTP交易和OLAP查询。TBase则是分别针对OLAP业务和OLTP业务设置不同的计算引擎和数据服务接口,满足HTAP场景应用需求。OceanBase数据库使用基于LSM-Tree的存储引擎,能够有效地对数据进行压缩,并且不影响性能,可以降低用户的存储成本。
02
ETL工具选型
目前,业界比较领先的开源ETL数据抽取工具主要有Kettle、DataX和Waterdrop。商业版本的DataStage、Informatica和Data Services三款软件不仅配置复杂、开发效率低,执行大数据加载也非常慢。
Kettle(正式名为Pentaho Data Integration)是一款基于Java开发的开源ETL工具,具有图形化界面,可以以工作流的形式流转,有效减少研发工作量,提高工作效率。Kettle支持不同来源的数据,包括不同数据库、Excel/CSV等文件、邮件、网站爬虫等。除了数据的抽取与转换,还支持文件操作、收发邮件等,通过图形化界面来创建、设计转换和工作流任务。
DataX是阿里巴巴集团内部广泛使用的离线数据同步工具/平台,实现包括MySQL、Oracle、SQL Server、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute (ODPS)、DRDS等各种异构数据源之间高效的数据同步功能。
Waterdrop是一款易用、高性能、支持实时流式和离线批处理的海量数据处理工具,程序运行在Apache Spark和Apache Flink之上。Waterdrop简单易用、灵活配置、无需开发,可运行在单机、Spark Standalone集群、Yarn集群、Mesos集群之上。Waterdrop支持实时流式处理,拥有高性能、海量数据处理能力,支持模块化和插件化,易于扩展。用户可根据需要来扩展插件,支持Java/Scala实现的Input、Filter、Output插件。(志明补充:Waterdrop已更名为Apache SeaTunnel)
总的来说,Kettle适合中小企业ETL任务比较少并且单表数据量在百万以下的项目,开发速度快,支持的数据来源丰富,方便快速达成项目目标。DataX支持需要批处理抽取数据的项目,支持千万级、亿级数据的快速同步,性能高效、运维稳定。Waterdrop是后起之秀,在DataX的基础上还支持流式数据处理,是DataX的有力竞争者和潜在替代产品。
03
调度平台选型
调度平台可以串联ETL任务并按照指定的依赖和顺序自动执行。调度平台一般用Java语言开发,平台实现难度小,大多数数据仓库实时厂商都有自研的调度平台。
在早期银行业的数据仓库项目中,大多数据ETL过程都是通过DataStage、Informatica或者存储过程实现的。笔者接触过最好用的产品就是先进数通公司的Moia Control。Moia Control定位于企业统一调度管理平台,致力于为企业的批处理作业制定统一的开发规范、运维方法,对各系统的批量作业进行统一管理、调度和监控。Moia Control的系统架构如
图1所示,系统分为管理节点和Agent节点,管理节点负责调度任务的配置和分发作业,Agent节点负责任务的执行和监控。Moia Control在金融领域具有非常广泛的应用。

图1 Moia Control系统架构
在开源领域,伴随着大数据平台的崛起,虽然先后涌现了Oozie、Azkaban、AirFlow等深度融合Hadoop生态的产品,但都是昙花一现,目前已经逐步被DolphinScheduler取代。DolphinScheduler于2019年8月29日由易观科技捐赠给Apache启动孵化。DolphinScheduler的产品架构如图2所示。
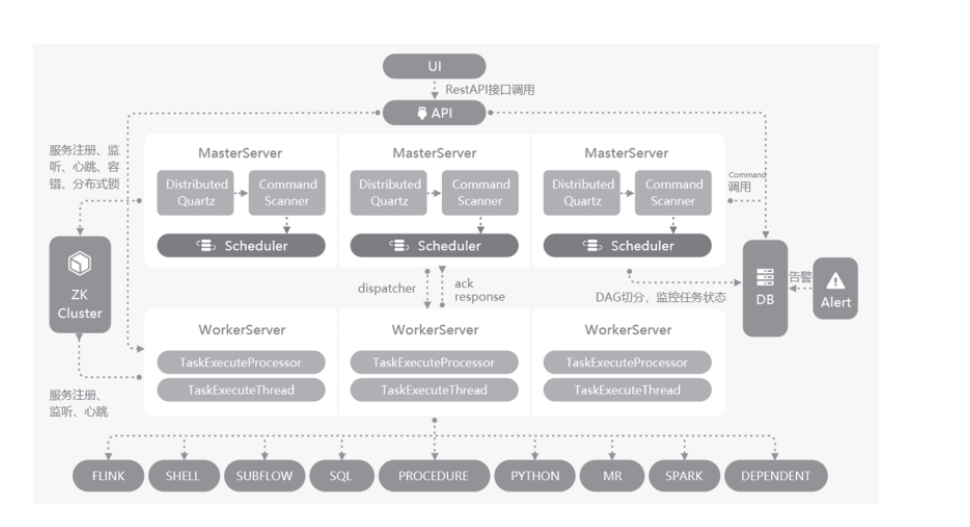
图2 DolphinScheduler 产品架构
DolphinScheduler是全球顶尖架构师与社区认可的数据调度平台,把复杂性留给自己,易用性留给用户,具有如下特征。
1)云原生设计:支持多云、多数据中心的跨端调度,同时也支持Kubernetes Docker的部署与扩展,性能上可以线性增长,在用户测试情况下最高可支持10万级的并行任务控制。
2)高可用:去中心化的多主从节点工作模式,可以自动平衡任务负载,自动高可用,确保任务在任何节点死机的情况下都可以完成整体调度。
3)用户友好的界面:可视化DAG图,包括子任务、条件调度、脚本管理、多租户等功能,可以让运行任务实例与任务模板分开,提供给平台维护人员和数据科学家一个方便易用的开发和管理平台。
4)支持多种数据场景:支持流数据处理,批数据处理,暂停、恢复、多租户等,对于Spark、Hive、MR、Flink、ClickHouse等平台都可以直接调用。
此外,Kettle本身包含调度平台的功能,我们可以直接在KJB文件中定义定时调度任务,也可以通过操作系统定时任务来启动Kettle,还可以去Kettle中文网申请KettleOnline在线调度管理系统。
Kettle通过KJB任务里面的START组件可以设置定时调度器,操作界面如图3所示。
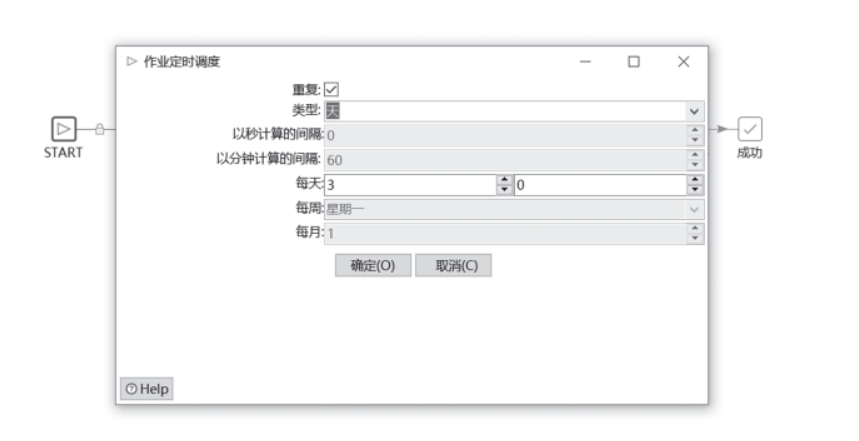
图3 Kettle定时页面
此外,在Kettle中文网还提供了功能更为强大的KettleOnline工具,非常适合较大型Kettle项目使用,具体功能这里就不展开介绍了。
除了上述调度工具之外,还有一些小众的Web调度工具,例如Taskctl、XXL-JOB等。总的来说,都能满足基本的需求。有研发实力的公司可以在开源版本的基础上进一步完善功能,打造属于自己的调度平台。
04
BI工具选型
BI是一套完整的商业解决方案,用于将企业现有的数据进行有效的整合,快速、准确地提供报表并提出决策依据,帮助企业做出明智的业务经营决策。BI工具是指可以快速完成报表创建的集成开发平台。
和调度平台不一样,BI领域商业化产品百花齐放,而开源做成功的产品却基本没有。这也和产品的定位有关,调度平台重点关注功能实现,整体逻辑简单通用,便于快速研发出满足基本功能的产品。而BI则需要精心打磨,不断完善和优化,才能获得市场的认可。
在早期Oracle称霸数据库市场的年代,BI领域有3个巨头,分别是IBM Cognos、Oracle BIEE和SAP BO。在早期BI领域,IBM 50亿美元收购Cognos、SAP 68亿美元收购BO都曾创造了软件行业的收购纪录。这两起收购发生分别发生在2007年和2008年。此后是传统BI的黄金十年,这三大软件占领了国内BI市场超过80%的份额。笔者参加工作的第一个岗位就是BIEE开发工程师,而后又兼职做过两年的Cognos报表开发,对二者都有比较深刻的认识。
在传统BI时代,主要按照星形模型和雪花模型构建BI应用,在开发BI报表之前,必须先定义各种维度表和事实表,然后通过各BI软件配套的客户端工具完成数据建模,即事实表和维度表的关联,以及部分指标逻辑的计算(例如环比、同比、年累计等)。最后在Web页面上定制报表样式,开发出基于不同筛选条件下,相同样式展现不同数据的固定报表。整个开发过程逻辑清晰,模块划分明确,系统运行也比较稳定,作为整个数据分析项目的“脸面”,赢得了较高的客户满意度。
传统BI以固定表格展现为主,辅以少量的图形。虽然模型和页面的分离让开发变得简单,目前广泛应用于金融行业和大型国企管理系统中,但是也有不少缺点,例如,星形模型的结构在大数据场景下查询速度非常慢、模型与页面的分离造成版本难以管控、模型中内嵌函数导致查找数据问题变得困难等。
2017年前后,Tableau强势崛起,以“敏捷BI”的概念搅动了整个BI市场,引领BI进入一个全新的时代。
Tableau最大的特点是以可视化为核心,强调BI应用构建的敏捷性。Tableau抛弃了传统BI的模型层,可以直接基于数据库的表或者查询来构建报表模块,大大降低了开发难度,提升了报表的开发效率和查询性能。曾经需要一天才能完成的报表开发,现在可能一个小时不到就可以完成,极大提升了产出效率。
在传统BI时代,国产BI软件虽然也在发展,但是不够强大。在敏捷BI时代,FineBI、永洪BI、SmartBI、观远BI等商业化产品顺势崛起,开始抢占国内BI市场。帆软公司的Fine Report和FineBI更是其中的佼佼者,稳坐国产BI软件的头把交椅,将产品铺向了广大中小企业。国产BI在培训体系上做得更为完善,以至于笔者发现在最近半年的面试中,差不多有一半的应聘者使用过帆软公司的产品。
在国产化BI之外,跨国软件公司也在敏捷BI方向上做出了调整,其中笔者接触过的就有微软的Power BI和微策略的新一代MSTR Desktop。同时,云厂商也加入BI市场的争夺,其中百度云Sugar、阿里云QuickBI都是内部产品对外提供服务的案例。
总的来说,在敏捷BI领域,国外厂商的软件成熟度高,版本兼容性好。国内厂商的软件迭代比较快,也容易出现Bug。从实现效果上看,以上软件的差异并不大,BI战场已经变成了UI的较量了,只要UI能设计出好的样式,绝大多数BI软件都可以实现近似的效果。
来源:志明与数据
作者:王春波




