

"小王,这个数据跑了三个小时还没出来,明天的AI模型训练怎么办?"
办公室里,数据科学家小李盯着电脑屏幕,眉头紧锁。屏幕上的进度条像蜗牛一样爬行,让人怀疑人生。
这个场景你熟悉否?在AI时代,如果数据真是新石油,那么数据科学家就真是炼油工了。大家都在谈论AI多么神奇,DeepSeek多么智能,模型多么强大。
可现实呢?90%的时间都在等数据,等数据传输,等数据清洗,等数据准备。 数据科学家们经常自嘲:"
我们是AI时代的搬砖工。"
传统数据传输的痛点:慢到怀疑人生
让我们算一笔账。
一个中等规模的机器学习项目,需要处理10TB的数据。用传统的MySQL客户端或JDBC连接方式,传输速度大概是每秒几百MB。10TB数据需要传输多久?
整整一个通宵。
更要命的是,这还只是传输时间。数据到了本地,还要进行格式转换、清洗、预处理。原本的列存格式数据,要先转成行存传输,到了客户端再转回列存格式供算法使用。这个过程好比把一箱苹果先打散,装到一个个小袋子里运输,到了目的地再重新装箱。
"这不是脱裤子放屁吗?"一位资深算法工程师吐槽道。
传统方案的问题不止于此:
数据传输过程中要经历多次序列化和反序列化,CPU资源消耗巨大。内存占用也成倍增长,动不动就爆内存。网络带宽被低效利用,明明有千兆网络,却只能跑出百兆的效果。
更让人抓狂的是,很多数据科学项目需要反复试验,同样的数据要传输N次。每次调参、每次验证、每次重新训练,都要重新来一遍这个痛苦的过程。
Arrow Flight SQL:数据传输界的su7
Doris 2.1版本带来了一个救命性的功能:基于Arrow Flight SQL协议的高速数据传输链路。
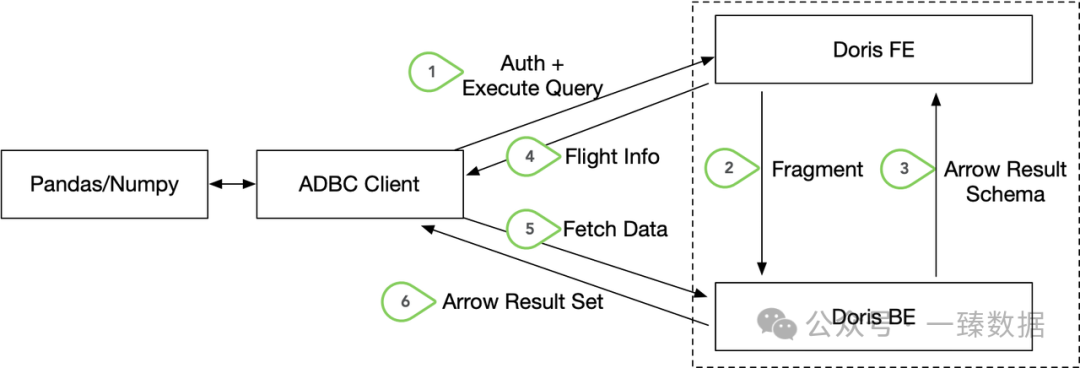
什么概念?原来需要一晚上传输的10TB数据,现在可能只需要几十分钟。性能提升不是10%、20%,而是百倍级别的飞跃。
这真就从绿皮火车换到了高铁,从马车换到了小米su7。
Arrow Flight SQL的巧妙之处在于彻底颠覆了传统的数据传输思路。
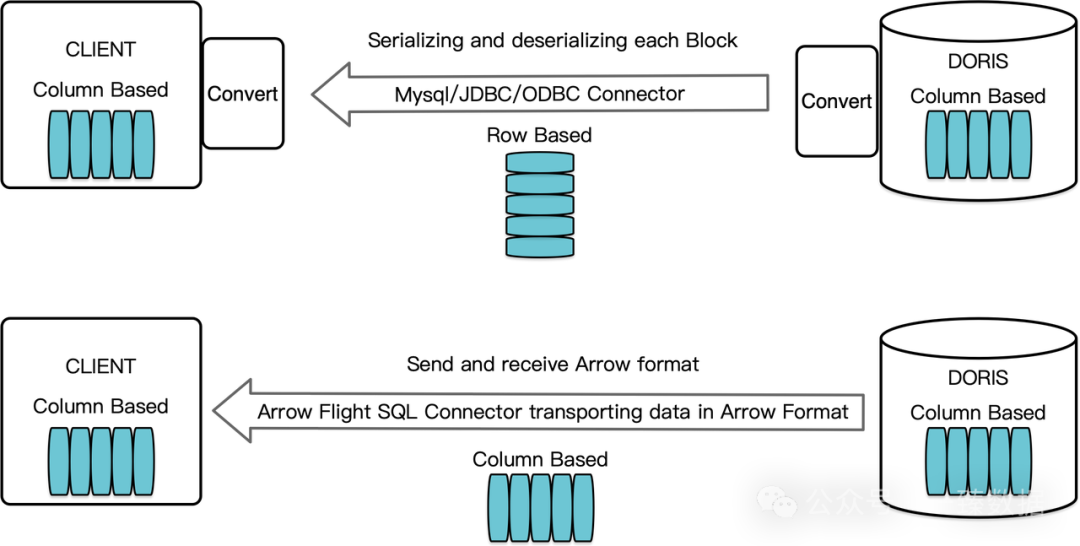
Doris内部查询结果本身就是以列存格式的Block组织的。传统方案需要把这些Block转换成行存的Bytes传输,客户端接收后再反序列化为列存格式。
Arrow Flight SQL直接跳过了这个"脱裤子放屁"的过程。数据在Doris里是什么格式,传输过程中就是什么格式,到了客户端还是什么格式。零转换,零损耗。
这就像快递公司不再要求你把东西重新包装,而是直接用你的原包装发货。省时省力省心。
而真正让Doris在数据科学领域脱颖而出的,不仅仅是速度,更是它对生产环境复杂性的深度理解。
很多数据科学项目在实验室里跑得很好,一到生产环境就各种问题。网络不通、权限不够、配置复杂、扩展困难。
Doris的Arrow Flight SQL充分考虑了这些现实问题:
1. 多BE节点并行返回结果
当查询结果很大时,可以从多个节点同时获取数据,进一步提升传输效率。
2. 支持反向代理配置
生产环境中BE节点通常不直接对外暴露,Doris可以通过Nginx等反向代理实现数据转发,既保证了安全性,又维持了高性能。
3. 提供灵活的连接管理
支持长连接复用,减少连接建立开销;同时提供合理的超时和清理机制,避免资源泄露。
与大数据生态的深度融合
当然,数据科学项目很少是孤立的。
它们通常是更大数据处理流水线的一部分,需要与Spark、Flink等大数据框架协同工作。
Doris的Arrow Flight SQL为这种协同提供了完美的桥梁。Spark可以通过Arrow Flight SQL高效读取Doris数据,进行大规模特征工程;Flink可以实时消费Doris的流式数据,为在线机器学习提供支持。
更重要的是,Arrow作为一种标准化的内存数据格式,已经被越来越多的数据处理框架采用。这意味着基于Arrow Flight SQL的数据流水线具有很好的互操作性和可扩展性。
你的数据可以在Doris、Flink、Spark、Pandas、TensorFlow之间无缝流转,就像水在不同容器间流动一样自然。
用Python轻松驾驭海量数据
对数据科学家来说,最爽的事情是什么?当然是代码跑得飞快,数据来得及时。
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
# 连接Doris
conn = flight_sql.connect(uri="grpc://doris-fe:8070", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()
# 执行查询
cursor.execute("SELECT * FROM massive_table")
df = cursor.fetch_df() # 直接返回pandas DataFrame
...
就这么简单。几行代码,亿级数据瞬间到手。不需要复杂的配置,不需要担心内存爆炸,不需要等待漫长的传输时间。
关键是cursor.fetch_df()这个方法。它直接返回pandas DataFrame,数据全程保持列存格式。科学家们可以立即开始数据分析,无缝对接NumPy、Pandas、Scikit-learn等主流数据科学库。
有位数据科学家兴奋地说:"这感觉就像从拨号上网时代一步跨入了光纤时代。"
Java生态的全面支持
Java开发者也没有被遗忘。Doris提供了多种Java连接方式,适应不同的使用场景。
如果你的下游分析需要基于行存数据格式,可以使用标准的JDBC方式:
String DB_URL = "jdbc:arrow-flight-sql://doris-fe:8070";
Connection conn = DriverManager.getConnection(DB_URL, "user", "pass");
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("SELECT * FROM data_table");
...
如果你想充分利用Arrow的列存优势,可以使用ADBC Driver:
final BufferAllocator allocator = new RootAllocator();
FlightSqlDriver driver = new FlightSqlDriver(allocator);
AdbcDatabase adbcDatabase = driver.open(parameters);
AdbcConnection connection = adbcDatabase.connect();
AdbcStatement stmt = connection.createStatement();
stmt.setSqlQuery("SELECT * FROM massive_dataset");
QueryResult queryResult = stmt.executeQuery();
ArrowReader reader = queryResult.getReader();
...
这种方式返回的是原生Arrow格式数据,可以直接用于大数据分析框架,性能达到极致!
结语
回到文章开头的场景。现在的小李不再需要通宵等数据了。
"小王,昨天的10TB数据已经处理完了,新的模型训练可以开始了。"小李轻松地说道。
"这么快?"小王有些惊讶。
"Doris的Arrow Flight SQL,数据传输快得飞起。我现在有更多时间专注于算法优化,而不是等数据。"
Doris的Arrow Flight SQL让数据科学真正起飞了,让AI应用的开发变得更加高效和可靠
来源(公众号):一臻数据




