

1. 为什么大语言模型(LLMs)会“过度自信”
现代LLMs在数学、科学甚至代码推理方面表现惊人,这得益于一种称为带验证奖励的强化学习(RLVR)的训练范式。在RLVR中,模型生成答案,自动验证器检查其正确性,并据此给予奖励(或惩罚)。这一循环使模型无需人工编写的奖励信号即可自我改进。
但这里存在一个隐藏的问题。
在RLVR训练中,大多数流程会反复采样相同的“初始状态”(即原始问题)。随着模型学会解决这一特定提示分布,其策略熵(衡量其下一个token选择多样性的指标)会急剧下降。简而言之,模型开始依赖少数安全的答案模式,变得过度自信且低多样性。结果是熵崩溃:探索枯竭,学习停滞,进一步训练收效甚微。
研究人员尝试用提高采样温度、添加KL惩罚或裁剪高协方差token等技巧修补此问题。这些方法虽有一定效果,但通常需要针对任务精心调整超参数,且仍依赖同一组静态提示。我们真正需要的是在模型学习过程中向训练数据注入真正的新颖性。
2. 如何让模型保持“好奇”
当语言模型生成解决方案时,有时会真正犹豫该写哪个词或数学运算符。这些时刻反映为高token级熵——模型“举棋不定”。
如果我们在这些高熵点精确干预,可以在分叉前截断部分生成的答案,保留导致不确定性的连贯前缀,并将该前缀附加到原始问题后重新提示模型。模型现在面临一个略有不同的初始上下文——一个它从未见过的上下文——因此其后续决策被迫探索新的推理路径。

这就是CURE(关键token引导的重新拼接)的核心。CURE不调整损失函数或裁剪梯度,而是动态重塑数据分布,引导模型转向未充分探索的状态,从而延缓熵崩溃。
3. CURE简述——两个阶段
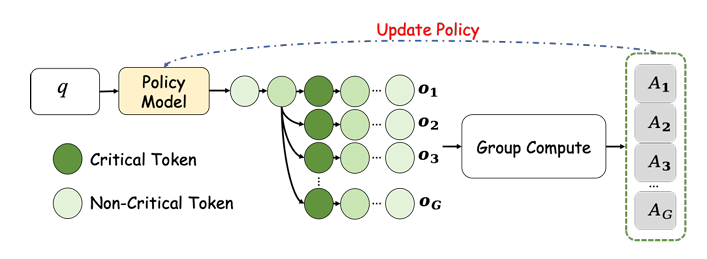
阶段1(探索)。 采样器被替换为以下流程:首先生成原始提示的多个 rollout,计算每个token的熵,选择一个关键token(从top-K中均匀采样的最高熵token),提取该token前的前缀,将其与原始问题拼接,然后从新提示生成额外 rollout。原始和重新提示的 rollout 组成训练组,输入GRPO风格的裁剪替代损失。
阶段2(利用)。 探索阶段后,训练与标准RLVR完全相同:模型在原始问题上微调(无重新拼接)。由于策略已接触更丰富的初始状态,现在可以安全地将熵缩减至确定性高精度状态,而不会崩溃。
4. 方法深入解析(阶段1)
以下是探索阶段的逐步说明,非专业人士也能理解。
采样初始 rollout
对训练集中的每个问题q,用当前策略π₀生成N₁(如4个)候选答案。
计算token级熵
生成每个答案时,模型在每一步对词汇表分配概率分布。该分布的熵,
量化其在token位置t的“不确定性”。高Hₜ表示模型在多个合理选项中犹豫。
选择关键token
按Hₜ排序所有位置。
取top-K(如K=20)最高熵位置。
从中均匀采样得到随机关键索引t⁎。
创建前沿前缀
提取前缀p = answer₁…answer₍ₜ⁎₋₁₎(关键token前的所有内容)。
重新拼接
构建新提示
其中“||”表示简单拼接。
生成重新提示的 rollout
从每个精炼提示q′生成N₂(如3个)额外答案。
组构建
对每个原始问题q,现在有一个组
该组输入GRPO风格的裁剪替代损失:
动态过滤(DAPO技巧)
丢弃并重新采样仅含全正确或全错误答案的组,确保每批包含混合信号。
优化
用AdamW(学习率=1e-6,无熵或KL正则化)最小化损失。故意省略KL项,因为重新拼接前缀被视为外生干预——无梯度流过,模型仅学习对新上下文的反应。
阶段1结果: 模型的策略熵在探索中实际增长,同时习得的知识融入权重。后续利用阶段后,熵适度下降(评估温度0.6时约30%),但准确率比仅用阶段1的基线提高约7%。
5. 实验
在六个标准数学推理基准上,CURE始终优于先前的RLVR方法。第一阶段(探索)后,多数数据集准确率绝对提升约2–3%。最终(利用)阶段表现最佳:
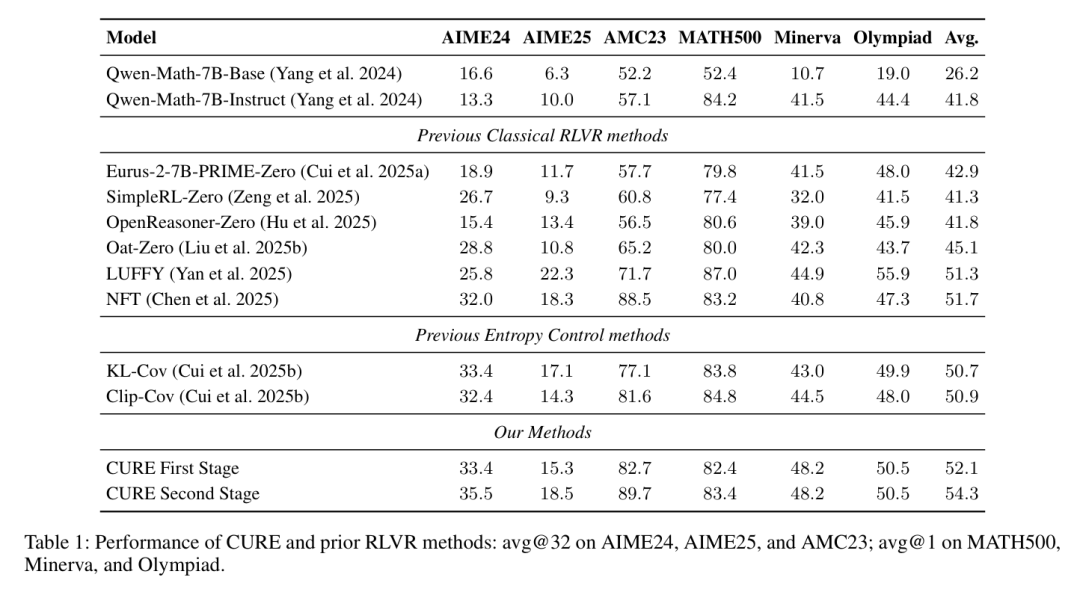
六基准平均准确率从阶段1后的 52.1% 升至阶段2后的 54.3% ——绝对提升约2%,相对最强RLVR基线改进约5%。
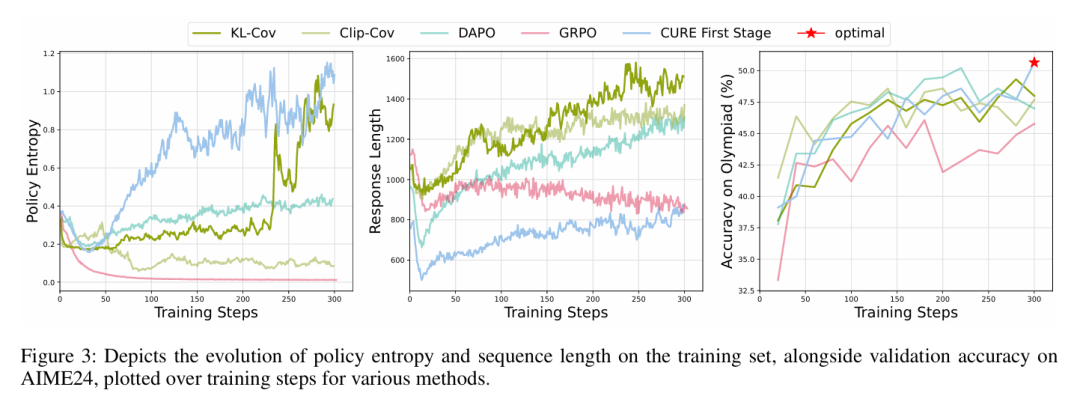
熵轨迹显示,探索阶段达到所有测试方法的最高策略熵,利用阶段平滑降低熵,同时高于DAPO或GRPO的平台期。定性分析(生成文本的词云)显示阶段1后连接词(“因此”“验证”等)使用更丰富,符合CURE鼓励更广推理路径的假设。
6. 结论——“好奇”LLMs的配方
CURE证明,一种以数据为中心的微调——在模型自身犹豫时刻重新提示——可显著延缓熵崩溃,并在挑战性推理基准上转化为真实性能提升。因其仅需两个额外超参数(rollout数量)和top-K设置,易于采用、计算廉价且兼容任何RLVR框架。
来源(公众号):AI Signal 前瞻




