

为何“记忆”对LLM至关重要
大语言模型(LLMs)在文本生成、翻译和问答方面表现卓越,但它们都存在一个根本性局限:无状态性。每个用户查询都被独立处理,模型仅能查看固定长度的“上下文窗口”(通常为数千个 token)。当对话跨越数十轮,或任务需要数周前的对话信息时,模型便会遗忘——关键信息对其不可见。
常见的解决方案是附加外部记忆库。模型通过检索增强生成(RAG)获取少量历史记录并附加到提示词中。这为 LLM 提供了访问“旧”信息的捷径,但也引入了两难权衡:
检索条目过少 → 遗漏关键事实,导致错误答案
检索条目过多 → 提示词被无关信息淹没,模型注意力分散

人类记忆的工作方式不同:我们快速浏览庞大的心理档案,然后筛选并整合与当前问题真正相关的内容。Memory‑R1 论文的作者主张,“记忆管理”应是一项习得技能,而非手工设计的启发式规则。
Memory‑R1 核心思想概览
Memory‑R1(读作“Memory‑R‑one”)是一个强化学习(RL)框架,为 LLM 配备两个专用智能体:
记忆管理器 – 针对每条新信息,决定添加(ADD)、更新(UPDATE)、删除(DELETE) 或无操作(NO‑OP);基于下游答案正确性,通过结果驱动的 RL(PPO 或 GRPO)进行优化
应答智能体 – 根据用户问题,通过 RAG 召回最多 60 条候选记忆,提炼最有用信息并生成最终答案;同样通过 PPO/GRPO 微调,奖励信号为生成答案与标准答案的精确匹配(EM)率
两个智能体均构建于标准 LLM 之上(作者实验了 LLaMA‑3.1‑8B‑Instruct 和 Qwen‑2.5‑7B‑Instruct)。关键在于,仅需152 个标注的问答对即可训练系统——远少于监督微调通常所需的数千个样本。
方法深度解析
1. 整体流程
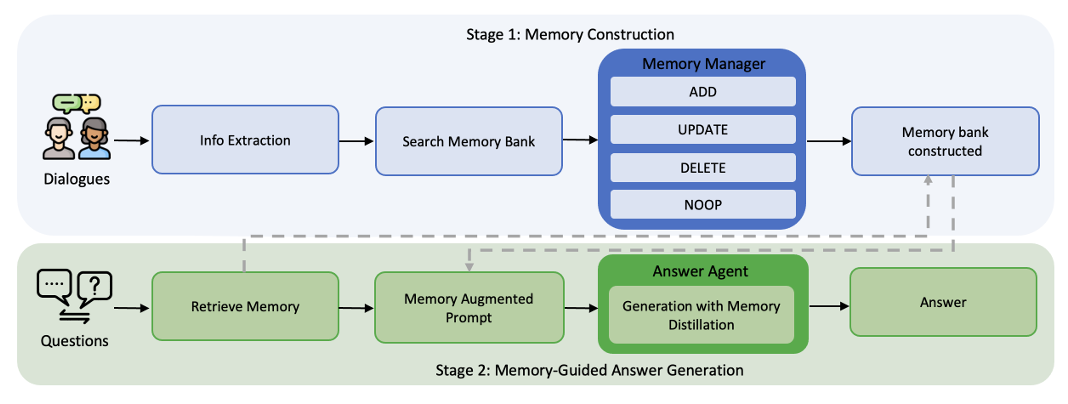
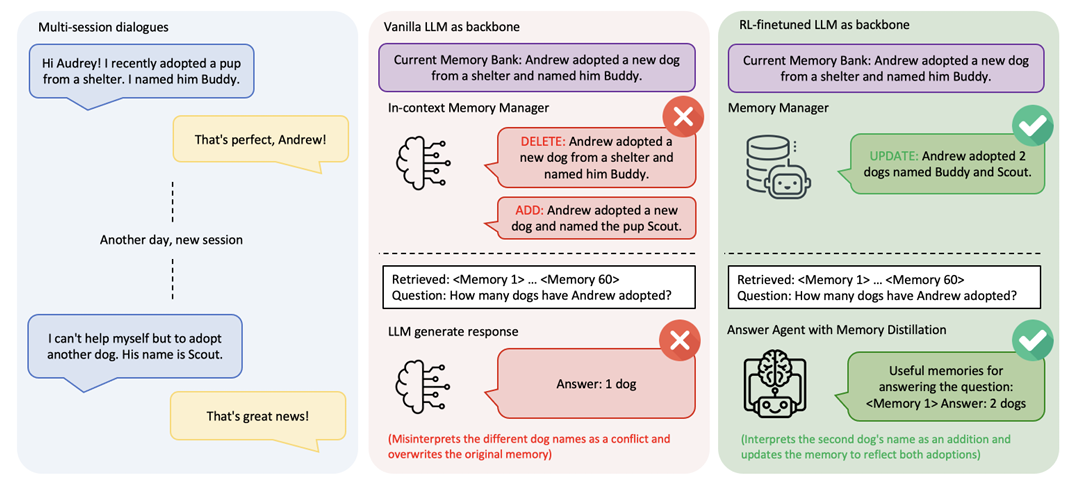
对话轮次到达 → LLM 提取关键事实 (例如“Andrew 收养了名为 Buddy 的狗”)
RAG 检索从当前记忆库 中获取相关记忆短列表
记忆管理器接收 并预测操作
记忆库相应更新,产生新库
问题出现时 → RAG 从 中获取最多 60 条候选记忆
应答智能体执行记忆提炼策略:对每条检索记忆评分,保留 top‑k(通常仅少数几条),并基于提炼后的上下文生成答案
2. 强化学习微调
两个智能体均作为策略网络 进行训练,将输入映射到离散动作(记忆操作或答案 token)。探索了两种 RL 算法:
近端策略优化(PPO) – 通过裁剪替代目标优化,保持策略更新稳定性;经典且易于理解,适用于价值函数(评论家)可估计预期奖励的场景
组相对策略优化(GRPO) – 对一组动作采样并相对排序,在组内标准化优势函数;无需显式评论家,在稀疏的结果驱动奖励(如精确匹配)下收敛更快
2.1 记忆管理器 RL
状态:提取事实 + 检索记忆
动作:四类记忆操作 token 之一,以及(ADD/UPDATE 时)待插入或合并的内容
奖励:若更新后应答智能体生成正确答案则 ,否则
策略训练目标是最大化基于操作前后答案准确率差异计算的优势值。由于奖励为二值信号,策略能快速学会哪些操作安全(NOOP),哪些操作有益(如“两只狗”案例中的 UPDATE)。
2.2 应答智能体 RL
状态:问题 + 检索记忆集
动作:完整答案 token 序列(自回归生成)
奖励:生成答案 与标准答案 的精确匹配(EM)率
训练期间,智能体对候选答案批次采样并计算 EM 分数,将得分输入 PPO/GRPO。记忆提炼步骤嵌入策略中:模型学会关注能最大化 EM 的记忆子集,实现内置过滤机制。
3. 数据构建
记忆管理器训练数据 – 对每轮对话,使用强 LLM(GPT‑4o‑mini)构建时序记忆快照(前 50 轮对话)。该轮次、快照及关联问答对构成监督学习元组。通过比较该轮次前后的快照自动标注正确操作(ADD/UPDATE/DELETE/NOOP)
应答智能体训练数据 – 记忆管理器构建全局记忆库后,每个问题检索每位参与者最相关的 30 条记忆(共 60 条)。三元组(问题,检索记忆,标准答案)成为应答智能体的训练样本
实验亮点
基准测试:LOCOMO
LOCOMO 是用于长程对话记忆的挑战性基准,包含 10 个多轮对话,每个对话约 600 轮(≈ 26 k token)。问题需跨越遥远对话轮次进行单跳、多跳、开放域及时序推理。
训练制度:仅使用第一个对话(152 个问答对)进行微调;剩余八个对话(1 307 个问答对)构成测试集
骨干模型:LLaMA‑3.1‑8B‑Instruct 和 Qwen‑2.5‑7B‑Instruct
主要结果(文本描述)
作者对每个骨干模型评估了 GRPO 和 PPO 训练的 Memory‑R1 系统,并与两个基线对比:原始记忆系统(Mem0)和文献报道的最强非 RL 基线(A‑Mem)。
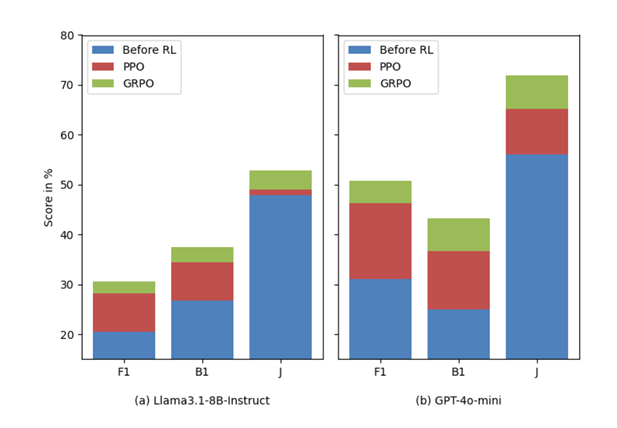
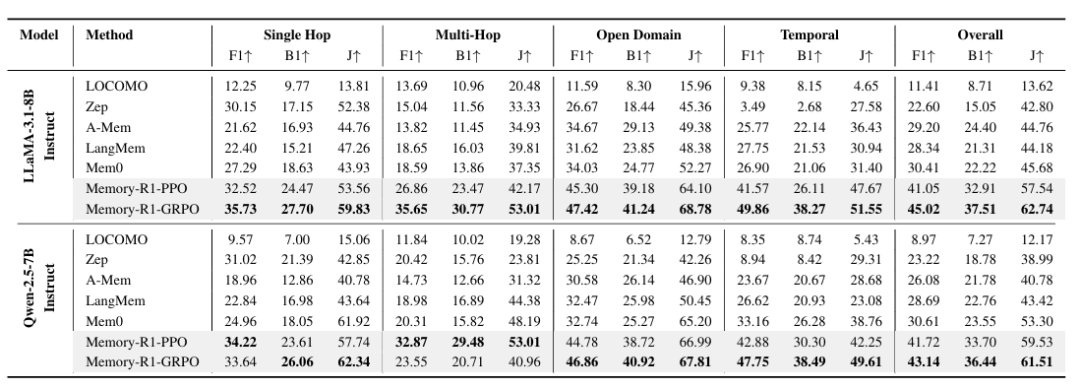
简言之,Memory‑R1 相比最强非 RL 基线将 F1 提高约 48 %(LLaMA)和 57 %(Qwen),BLEU‑1 和 LLM‑as‑a‑Judge 指标亦有相当提升。
消融实验洞察
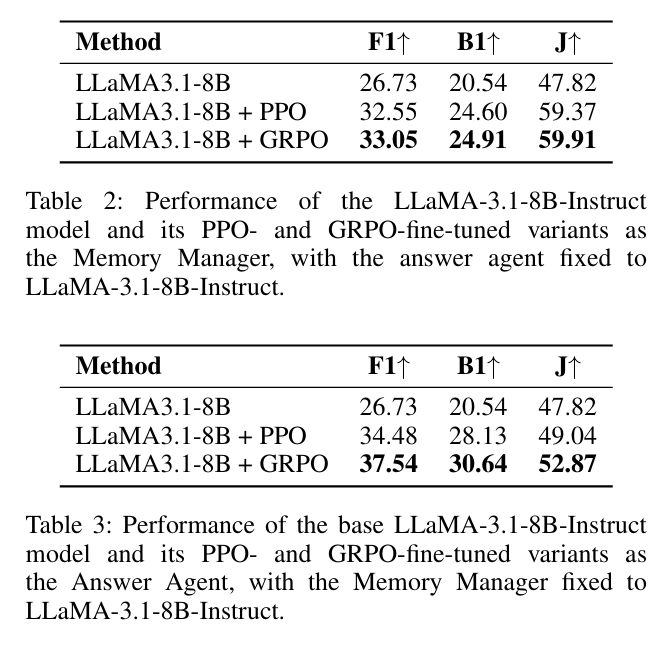
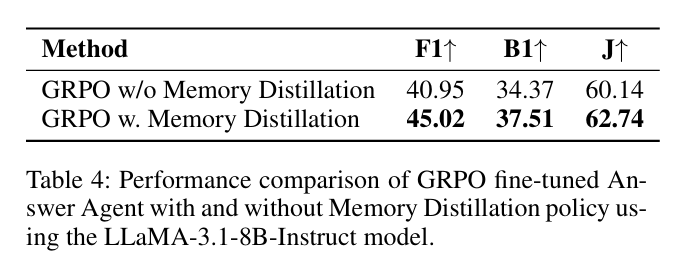
结果证实作者主张:每个 RL 训练组件均带来可量化价值,且双智能体相互增强——更优的记忆管理为应答智能体提供更丰富上下文,而选择性提炼策略进一步受益。
PPO 与 GRPO 对比
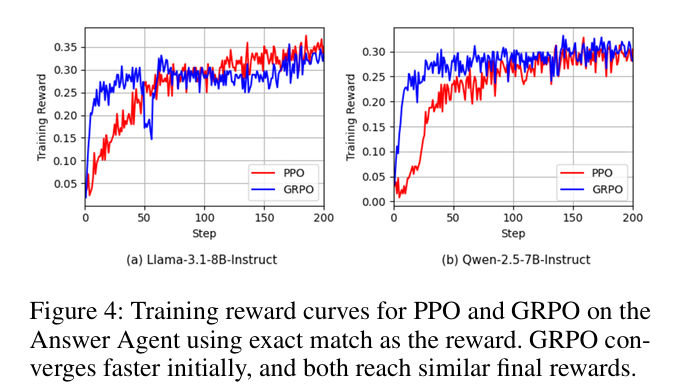
训练曲线显示GRPO 早期收敛更快,因为当奖励稀疏(二值 EM)时,组相对优势提供更强梯度信号。但两种算法最终性能相近,表明选择可基于计算预算或所需速度。
结论
Memory‑R1 表明,赋予 LLM “记忆感知”能力——而非单纯扩大容量——可显著提升其长周期记忆、推理与行动能力。随着强化学习技术持续成熟,我们有望见到真正学会管理自身知识的、日益 sophisticated 的智能型 LLM 系统。
来源(公众号):AI Signal 前瞻




