

标题:Metacognitive Reuse: Turning Recurring LLM Reasoning Into Concise Behaviors
日期:2025-09-16
一句话总结:本文提出一种机制,使大语言模型能够元认知地分析自身推理轨迹,将重复模式提取为简洁可复用的"行为单元",并利用这些单元提升未来问题解决的效率与准确性。
问题症结:为何大语言模型总在重复发明轮子
大型语言模型(LLMs)在解决复杂多步骤问题方面展现出惊人能力,涵盖从高等数学到代码编写的多个领域。这一成功的关键驱动力在于"思维链"(CoT)提示技术,该技术通过生成详细的逐步推理轨迹,促使模型进行"出声思考"。
然而,这种能力恰恰暴露了一个根本性的低效问题。当面对新问题时,LLMs往往会从头开始重新推导相同的基础原理和子程序。设想一个LLM正在解决需要有限几何级数公式的问题:它可能会逐步细致地推导公式。而在处理几个问题后,当遇到类似任务时,它很可能再次执行完全相同的推导过程。这种持续重复发明轮子的行为导致多个问题:
令牌使用膨胀:冗余的推理步骤消耗大量令牌,增加计算成本和延迟
上下文空间浪费:模型的有限上下文窗口被重复推导占据,留给新颖问题特定推理的容量减少
知识积累缺失:当前推理循环缺乏内置机制来识别常用推理模式,将其封装为紧凑形式以供未来复用
本质上,虽然LLMs擅长推理,但它们患有一种程序性失忆症。它们懂得如何推演事物,却不记得自己已经推导过的内容。
元认知复用:基于经验学习的新框架
为解决这种结构性低效问题,研究人员受人类认知启发提出了新框架:元认知复用。元认知即"对思考的思考",是人类反思自身认知过程的能力。这项研究将该概念引入LLMs领域,为其创建从自身解题经验中学习的路径。
核心思想是让LLM能够分析自身推理轨迹,将重复出现的可泛化步骤提炼为名为行为的简洁可复用技能。行为被定义为具有规范名称的简短可操作指令。例如,模型可以学习并调用以下行为,而非每次重新推导三角形内角和:
behavior_angle_sum: 三角形内角和为180度。当已知两个角度时,运用该性质求未知角。
这些行为被收集并存储于 "行为手册" 中,作为程序性记忆的一种形式。与存储陈述性知识("是什么")的传统检索增强生成(RAG)系统不同,该手册存储的是程序性知识("如何做")。这是一个由模型生成、供模型使用的推理捷径库。该框架提供了将冗长缓慢的推导过程转化为快速可调用反射的机制。
创建「行为手册」:LLMs如何将推理提炼为技能
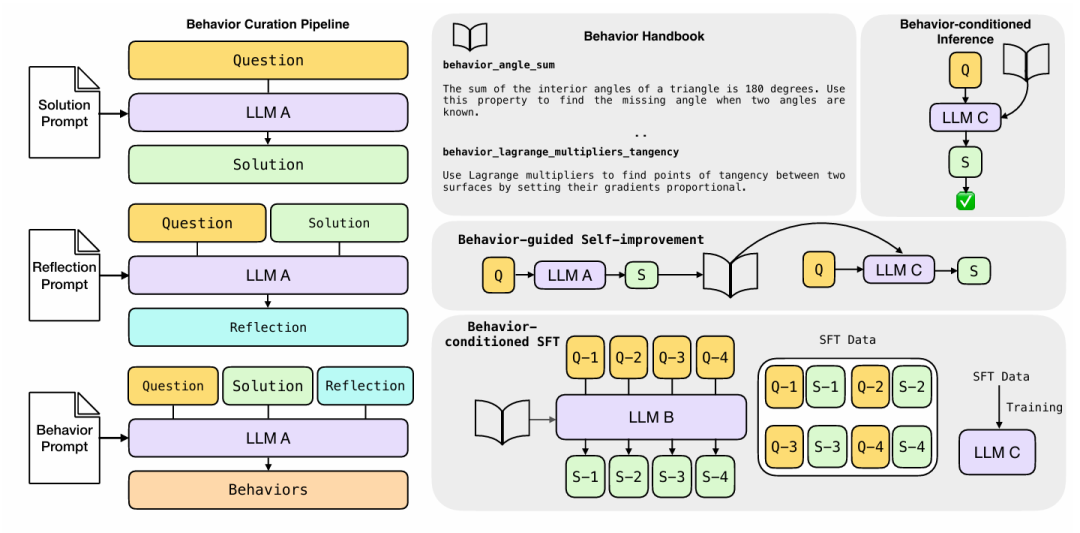
构建行为手册的过程是一个完全由LLM驱动(称为"元认知策略师")的系统化三步流程。如论文图1所示,该流程将原始推理转化为结构化可复用知识。
步骤一:求解
流程始于提示元认知策略师(本研究中采用R1-Llama-70B等模型)解决问题,生成详细的思维链推理轨迹。这是待提取知识的原始材料。
步骤二:反思

接着模型执行元认知任务:它面对自己的解决方案并被提示进行反思。如图2中"反思提示"所示,模型从多个维度审视自身工作:
正确性分析:逻辑是否严谨?是否存在数学错误?
缺失行为分析:哪些既定原理或捷径可使解决方案更简洁、更优雅或更不易出错?
新行为建议:推理中是否有部分可泛化为新的、广泛适用的未来行为?
步骤三:提炼
最后阶段,LLM将反思获得的见解形式化。通过特定"行为提示"(参见图2),它将建议转化为结构化的(名称,指令)对列表。例如在反思概率问题后,它可能提炼出以下行为:
systematic_counting: 通过检查每个数字的贡献进行系统性计数,避免遗漏案例和重复计数。
这些提炼出的行为随后被添加至持续增长的行为手册,创建出直接从模型解题经验中衍生的丰富可检索程序技能库。
行为应用实践:增强推理的三种方法
行为手册创建完成后,关键下一步是使LLMs在推理过程中能够获取这些程序性知识。研究阐述了利用这些行为提升性能的三种不同方法。
行为条件推理(BCI)
这是最直接的应用方式。当"学生LLM"获得新问题时,检索机制首先从手册中选择最相关的行为。这些行为及其指令随后与问题一同放入提示上下文中,模型被明确要求在解题时引用相关行为。
检索可通过两种方式实现:对于按主题组织的MATH数据集,直接根据问题主题检索行为;对于更多样化的AIME数据集,则采用基于FAISS的嵌入检索来查找语义最相似的top-K个行为。如图3提示模板所示,该方法通过相关提示直接指导模型。

行为引导自我改进
该方法使模型能够即时从自身错误中学习。模型首先生成问题的初始解,随后对其轨迹应用元认知流程来筛选相关行为,最后将这些自生成的行为作为提示反馈给同一模型以产生改进的二次解。这形成了强大的自我校正循环,使模型能在无外部指导或参数更新的情况下自我指导优化解题。
行为条件监督微调(BC-SFT)
虽然BCI有效,但需要在推理时在上下文中提供行为,这会增加输入令牌数。BC-SFT旨在将程序性知识"内化"到模型参数中。流程如下:
"教师LLM"使用BCI生成高质量解决方案数据集,其中明确引用所使用行为
"学生LLM"基于这些(问题,行为条件响应)对进行微调
目标是通过微调,学生模型能够无需提示中提供行为即可自发调用习得的推理模式。该蒸馏过程有效将教师的有意识引导推理转化为学生的快速直觉化低令牌响应。
实验结果:数学解题精度与效率的双重提升
研究人员在MATH和AIME等具有挑战性的数学基准上严格评估这些方法,取得了全面的显著成果。
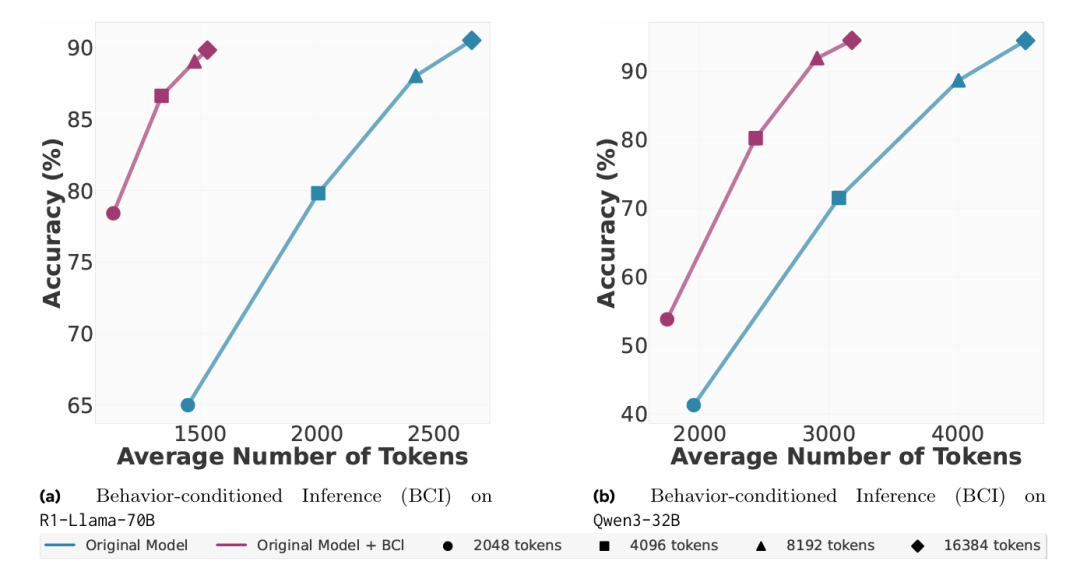
行为条件推理(BCI)的结果尤为突出:通过上下文提供相关行为,模型在显著减少令牌使用量的情况下(推理令牌最高减少 46% ),达到了与基线相当甚至更高的准确率。图4和图5清晰展示了这种令牌效率的提升。例如表1显示,模型通过调用behavior_total_outcomes和behavior_inclusion_exclusion等行为,可比从基本原理推导更简洁地解决概率问题。
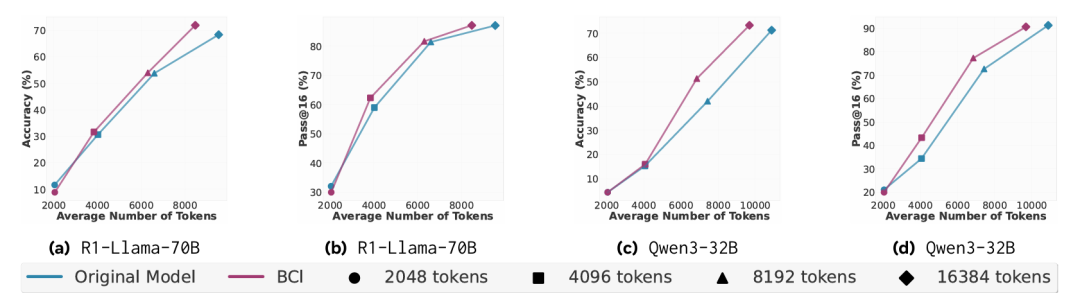

在行为引导自我改进中,该方法明显优于标准的批评-修订基线。
如图7所示,使用自生成行为的模型实现了最高 10% 的准确率提升。关键的是,性能随着令牌预算增加持续提升,表明行为提示能帮助模型更有效利用额外"思考时间"。
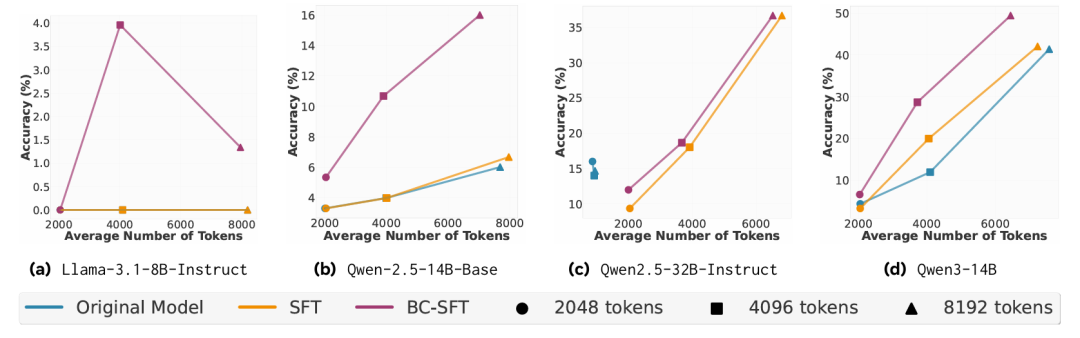
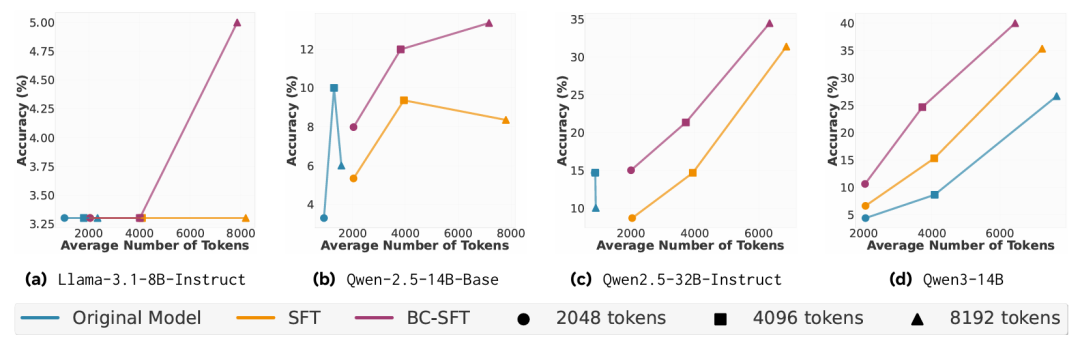
最后,行为条件监督微调(BC-SFT)被证明是培养持久推理能力的有效方法(图8图9). 研究发现BC-SFT特别擅长将较弱的非推理模型转化为具备推理能力的模型,带来超越简单摘要的"真正质量提升"。
结论:迈向具备推理记忆能力的LLMs
本研究引入了一种简单而强大的机制,以弥补LLM推理中的关键效率缺陷。通过赋予模型反思自身思维的元认知能力,我们能够使其将重复出现的推理模式提炼成简洁可复用的行为库。
在上下文推理、自我改进和监督微调这三种互补场景中,该框架持续实现了准确性与令牌效率的双重提升。核心洞见在于:这种方法帮助LLMs学会记忆如何推理,而不仅仅是什么结论。
虽然数学领域的结果令人鼓舞,但该框架具备领域无关性,可拓展至编程、科学推理和定理证明等其他复杂领域。当然仍存在局限性:当前BCI方法使用开始时检索的固定行为列表,而更动态的系统可在推理过程中实时检索行为。未来工作可聚焦于扩展该方法以构建大规模跨领域行为手册,并通过大规模微调更深度集成这些技能。
最终,这项工作指向这样一个未来:LLMs不仅是强大的问题解决者,更是能够积累经验、将缓慢思考转化为快速可靠专业知识的持续学习者。
来源(公众号):AI Signal 前瞻




