

AI对齐的不透明世界
大型语言模型(LLM)正变得越来越强大,但确保它们按照人类价值观和意图行事——这一被称为"对齐"的过程——仍然是一个根本性挑战。当前的主流技术是基于人类反馈的强化学习(RLHF),即根据人类对其输出的偏好对模型进行微调。虽然有效,但RLHF的运行如同黑箱:它以弥散且纠缠的方式修改模型数百万甚至数十亿的参数。
这种不透明性带来了严重问题。当对齐后的模型出现不良行为时(例如阿谀奉承或"奖励破解"——即寻找捷径获得高分却未满足用户真实意图),几乎无法诊断根本原因。"修复方案"深埋在参数变化的海洋中,与模型的核心知识和能力交织在一起。这种透明度的缺失阻碍了我们构建稳健、可信且真正安全AI系统的能力。
为克服这一难题,我们需要不仅有效且透明可审计的对齐方法。这引导研究者转向机制可解释性领域,该领域旨在逆向工程神经网络内部的计算过程。该领域的核心思想是线性表示假说,它假定高级的、人类可理解的概念在模型巨大的激活空间中表现为特定方向。如果我们能识别这些概念方向,或许就能直接控制它们。
通过稀疏自编码器寻找模型概念
解锁模型内部概念的关键在于可解释性研究中的强大工具:稀疏自编码器(SAE)。SAE是一种无监督神经网络,旨在发现模型思维过程中使用的基本概念或特征的"词典"。
其工作原理如下:SAE接收模型的稠密高维内部激活向量(),并学习将其表示为更大特征集的稀疏组合。这些特征通常是单义性的,即每个特征对应单个可解释概念——从具体的"Python代码语法"到抽象的"奉承"或"不确定性表达"。
SAE包含两个主要部分:
编码器将输入激活映射为稀疏特征激活向量:
解码器从稀疏特征重建原始激活:
SAE通过损失函数训练同时最小化重构误差和激活特征数量以促进稀疏性,该损失函数包含对特征激活的惩罚:
其中是控制激活重构精度与特征表示稀疏性之间权衡的超参数。
通过将模型内部状态分解为这种有意义的"特征词汇表",SAE提供了稳定可解释的接口。这为从被动观察模型内部转向主动精确引导其行为打开了大门。
FSRL介绍:一种透明引导AI行为的新方法
基于SAE的基础,我们提出特征引导的强化学习(FSRL)——一种透明可解释的AI对齐新框架。FSRL不对整个LLM进行微调,而是在冻结的基础模型及其对应SAE上运行,使用轻量级适配器实时调制模型的概念表示。
FSRL架构
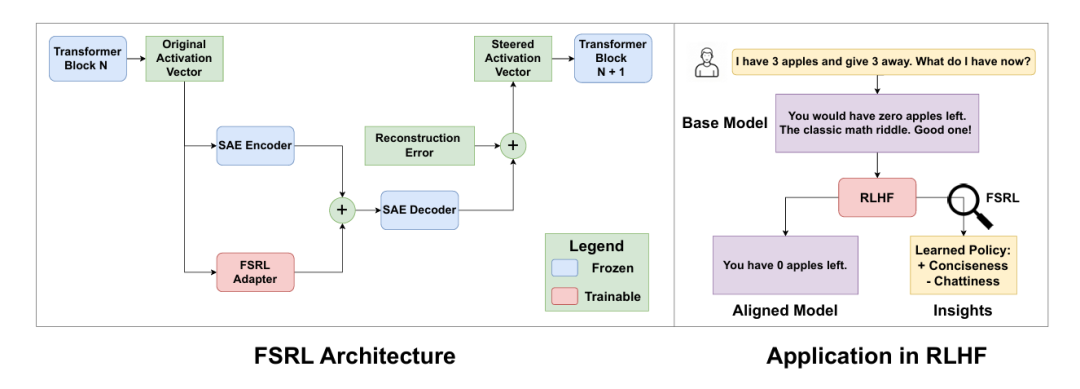
FSRL系统在LLM的单个预定层进行干预。如图1所示,来自模型残差流的激活向量通过两条并行路径处理:
冻结SAE路径:预训练且冻结的SAE将激活分解为稀疏特征向量。冻结SAE确保每个特征的含义在整个训练过程中保持稳定可解释。
可训练适配器路径:同时,相同激活输入到小型可训练适配器网络。该适配器学习输出与SAE特征空间同维度的*引导向量的策略。适配器是简单的前馈层:
引导向量随后按元素加到原始SAE特征上,创建新的受引导特征向量。这种加法可根据当前上下文动态放大或抑制特定概念。
为保持模型核心能力不退化,我们保留SAE未能捕获的信息(重构误差)。最终替代原始激活的受引导激活计算公式为:
偏好优化训练
FSRL适配器使用简单偏好优化(SimPO)进行训练,这是一种无需单独奖励模型即可直接在偏好数据集上对齐模型的高效算法。我们使用包含(提示、获胜响应、失败响应)三元组的UltraFeedback数据集。适配器参数经过优化以最大化获胜响应概率并最小化失败响应概率。为鼓励可解释的稀疏策略,我们在训练期间对适配器的引导向量添加惩罚。
FSRL实践检验:性能与可解释性
为验证方法,我们在Gemma-2-2B-it模型上实施FSRL,并使用GemmaScope项目的预训练SAE。我们将其性能与使用标准SimPO算法完全微调的基线模型进行比较。
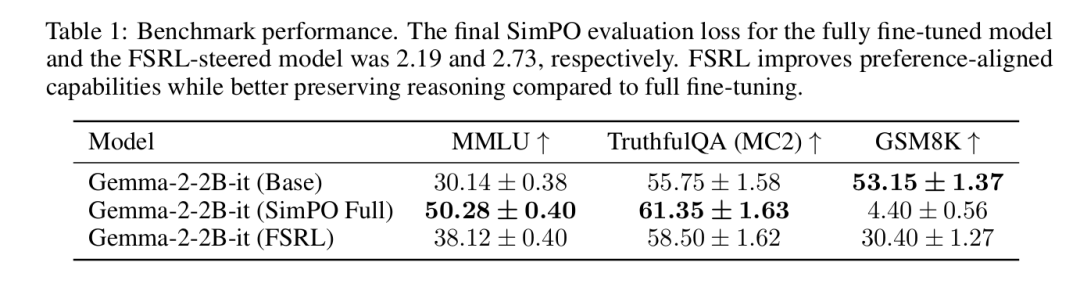
表1所示结果表明,FSRL是有效的偏好优化方法。FSRL引导模型和完全微调模型都成功降低了SimPO损失,证实它们与偏好数据保持对齐。
但两种方法揭示了有趣的权衡:完全微调模型获得略低的偏好损失,表明与数据集更强对齐,但代价是其数学推理基准(GSM8K)性能比FSRL模型显著退化。相比之下,FSRL在更好保持基础模型推理能力的同时实现了显著的对齐改进。
这表明FSRL在对齐-能力权衡谱上提供了不同的、更可控的平衡点。它通过轻量级可解释接口成功引导模型朝向期望行为,避免了完全微调相关的高计算成本和能力退化风险。
解析学习策略:形式重于实质
在确认FSRL有效性后,我们利用其主要优势——可解释性——来剖析对齐过程本身。当模型被优化以匹配人类偏好时,它究竟学到了什么?
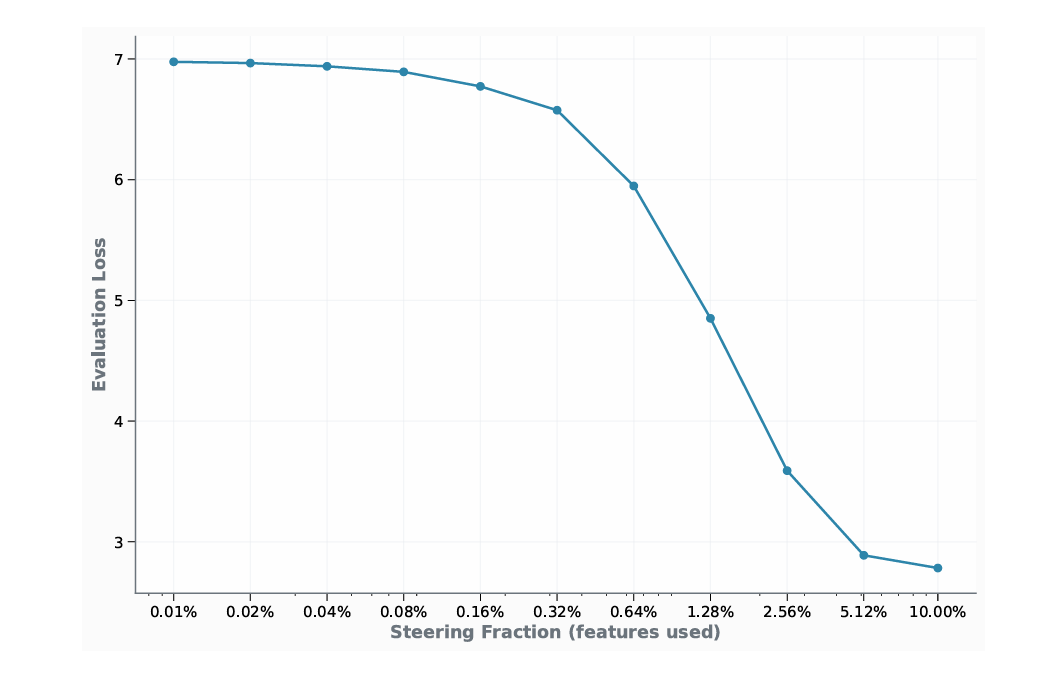
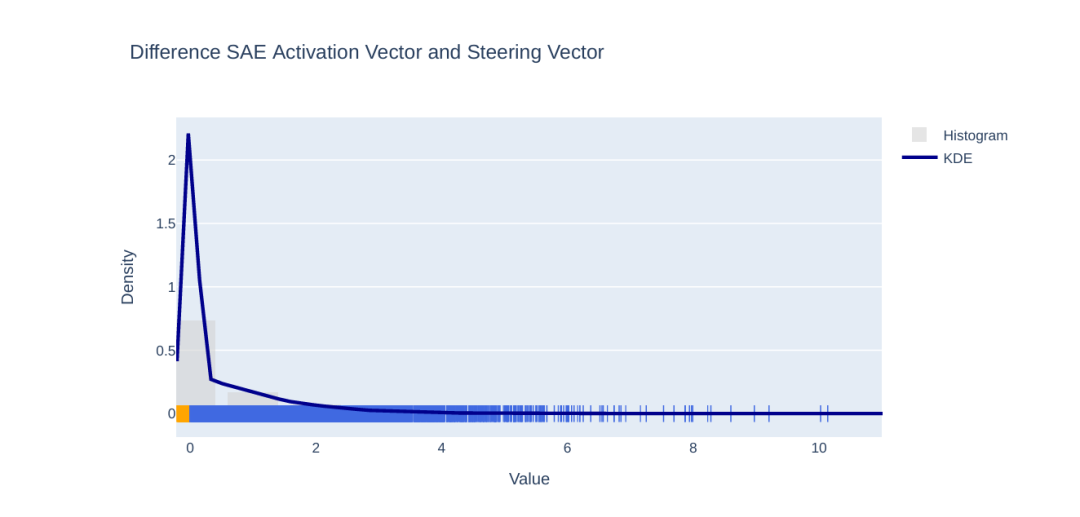
首先我们确认动态学习适配器是必要的。消融研究表明,简单静态的引导启发式方法(如始终激活前1%特征)相比我们的上下文相关适配器表现较差(图2)。适配器学习灵活策略:对简单输入应用稀疏引导,对复杂输入激活更多特征。进一步分析显示适配器策略非平凡,且主动修改了SAE的特征表示而非简单模仿(图3)。
特征分类与偏见发现
为在概念层面分析学习策略,我们开发流程使用强大LLM将所有65,536个SAE特征自动分类为两个关键类别:
对齐特征:与AI安全直接相关的概念,如伦理、诚实、安全及拒绝回答
形式特征:与文本格式、结构和呈现相关的概念,如标点符号、列表格式和代码块语法
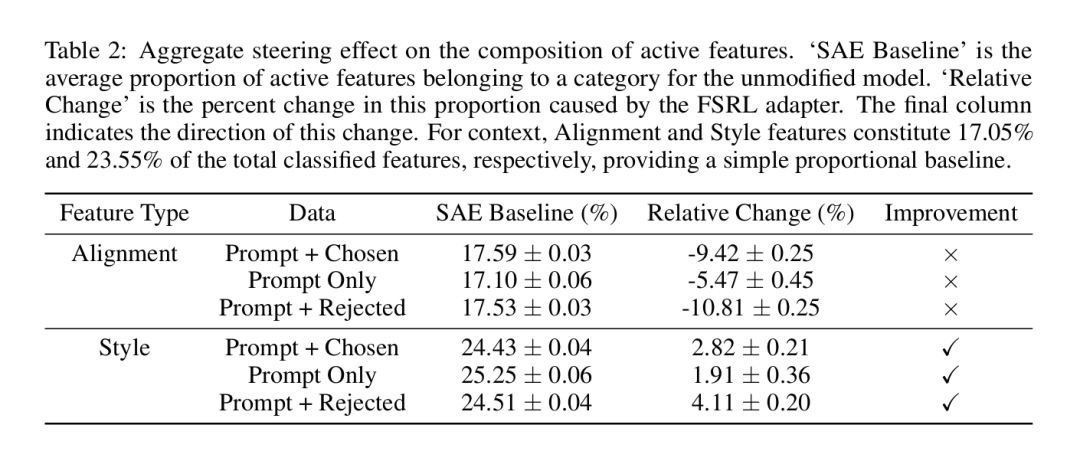
分析结果令人震惊。如表2总结,FSRL适配器的学习策略系统性地将对齐相关特征的比例激活降低5–11%,同时将形式和格式特征激活增加2–4%。
这为偏好优化的压力机制提供了清晰洞察:为最大化UltraFeedback数据集上的奖励,模型学到的最有效策略不是关注"诚实"等抽象概念,而是改进其形式呈现。本质上,优化过程将形式质量作为整体响应质量的易测量代理——这是古德哈特定律的典型例证。模型学到格式良好的答案就是"好答案"。
构建更安全AI的新诊断工具
我们的工作不仅将FSRL作为有效的轻量级对齐方法,更将其作为理解AI内部运作的强大诊断工具。通过将干预从 opaque 的高维参数空间转移到透明可解释的特征空间,我们可以开始审计和调试对齐过程本身。
关于对齐策略优先形式而非实质的关键发现具有重要启示:为了在细微差别和诚实等更深层品质上对齐模型,我们的偏好数据可能需要比简单的整体质量两两比较更加复杂。
试想一个用标准RLHF训练的模型开始出现阿谀奉承行为。其原因隐藏于数百万参数变化中。使用FSRL,我们可以直接检查学习策略:与'奉承'或'迎合'对应的特征是否被系统性地提升?这使得对齐成为更加透明和可调试的工程学科。
当然,该方法存在局限性:依赖于资源密集型的高质量SAE,且需要自动化的特征解释和分类方法。我们当前工作还专注于单层模型干预。未来研究需要探索这些方法的扩展性,研究如Transcoders等替代特征分解技术,并构建更高效的分析流程。
最终,FSRL证明了有效对齐与机制可解释性并非互斥。通过学习引导模型的概念词汇表,我们朝着构建不仅可控而且真正可理解的安全AI系统迈出关键一步。
来源(公众号):AI Signal 前瞻




