

标题:Sparse Neurons Carry Strong Signals of Question Ambiguity in LLMs
日期:2025-09-17
链接:http://arxiv.org/pdf/2509.13664v1
一句话总结:本文证明,大型语言模型中的问题模糊性仅由少量特定神经元稀疏编码,这些神经元可通过线性探针识别,并能通过因果操纵使模型从直接回答转向拒绝回答。
模糊问题中的错误自信危机
大型语言模型(LLM)在理解和生成人类语言方面展现出惊人能力。它们能撰写文章、翻译语言,并回答海量问题。然而在这卓越表现的背后,隐藏着一个关键缺陷:即便面对模糊问题时,它们仍会以不可动摇的自信作出回应。
试想一个简单提问:"谁赢得了最多的男子世界杯?"LLM 可能会自信地陈述:"赢得男子 FIFA 世界杯次数最多的队伍是巴西队,共五次夺冠。"虽然这个答案在男子足球领域事实正确,但它做了一个关键假设——用户可能是在询问橄榄球世界杯、板球世界杯或其他完全不同的运动项目。通过提供单一且过度具体的答案,模型未能识别问题中的模糊性,可能对用户产生误导。
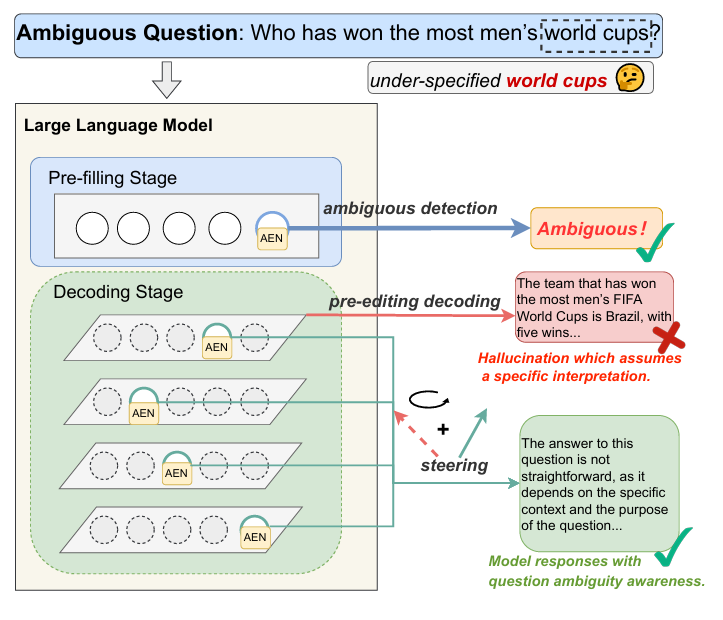
这种"错误自信"并非罕见故障,而是普遍存在的系统性问题。在从客服机器人到医疗信息系统的现实应用中,模糊性无处不在。一个宁愿自信地幻想答案而非寻求澄清的 LLM,不仅毫无助益,更可能变得不可靠甚至危险。解决这一局限性对于开发真正值得信赖且有用的人工智能系统至关重要。
揭示 LLM 中模糊性的神经表征
要构建更稳健的模型,首先需要理解它们如何处理模糊性。即便最终输出未能体现,LLM 是否在内部能识别问题存在未明确指定的情况?最近一项研究探索了这个核心问题,其突破点在于不再局限于观察模型行为,而是深入探究其内部"思维过程"。
研究人员采用了一种名为线性探测的技术。其核心思想是检验特定概念(本案中指问题模糊性)是否以线性编码形式存在于模型的内部表征中。具体流程如下:
创建对比数据集:研究人员编译了两组问题:从 AmbigQA 和 SituatedQA 等数据集提取的模糊问题集(D_amb),以及对应的清晰解歧问题集(D_clr)。
提取内部激活值:将每个问题输入 LLM(如 LLaMA 3.1 8B、Mistral 7B 和 Gemma 7B)后,记录模型初始处理(即"预填充"阶段)特定层的神经元激活状态(隐藏状态)。这些代表模型对输入内容内部理解的激活值,被汇总为每个问题的单一向量 h^(l)(x)。
训练线性探测器:使用简单的线性分类器(逻辑回归探测器 ŷ(x) = σ(w^T h^(l)(x) + b))来区分模糊问题与清晰问题的激活向量。
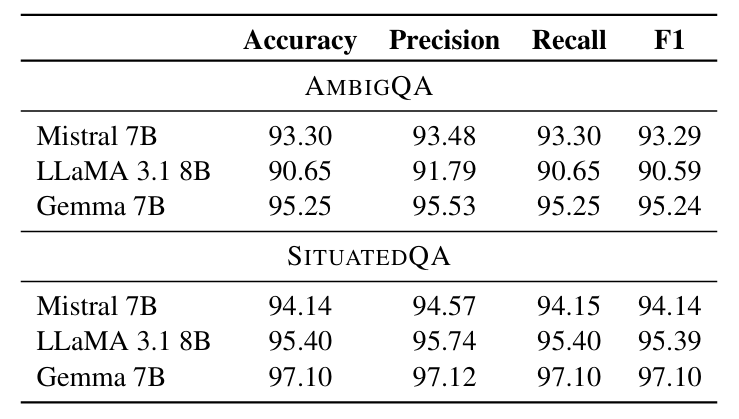
结果令人震惊。如表 1所示,线性探测器在多个模型和数据集上实现了超过 90% 的极高准确率。这一发现意义重大:它证明 LLM 会形成清晰、线性可分的内部表征(即"神经特征信号")来标识问题模糊性。即使当 LLM 自信地给出直接答案时,其内部状态仍包含表明问题实际存在模糊性的强烈信号。
模糊性编码神经元(AENs)的发现
知晓模糊性信号的存在仅是第一步,精确定位其具体位置则更为关键。该信号是分散在数千个神经元中,还是集中于少数特定神经元?研究团队通过深入挖掘找到了答案。
通过分析训练后的线性探测器权重向量 w,他们能识别哪些神经元在分类任务中最具影响力。绝对值权重 |w_i| 较大的维度对检测模糊性最为关键。为验证这一点,研究人员进行了噪声注入实验:
根据探测器权重对层中所有神经元进行排序
在前 k 个最具影响力的神经元激活值中系统性注入高斯噪声
测量由此导致的探测器准确率下降
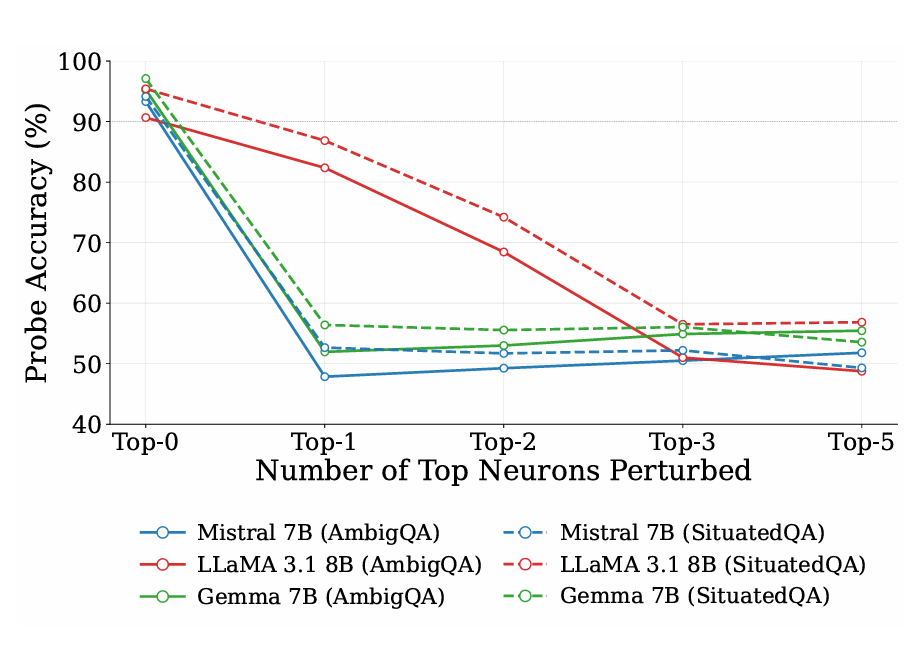
如论文中图 3所示,效果非常显著。仅扰动少数顶级排名神经元就会导致探测器识别模糊性的能力急剧下降。对于 Mistral 7B 和 Gemma 7B 等模型,破坏单个特定神经元就足以使检测性能瘫痪;而对 LLaMA 3.1 8B 而言,关键数量仅需三个。
这种极端稀疏性表明:模糊性的神经特征信号并非分布式现象,而是集中于微小且可识别的神经元子集中。研究人员将这些高度 influential 的单元命名为模糊性编码神经元(AENs)。
仅凭少数神经元精确定位模糊性
AENs 的发现为高效检测模糊输入提供了强大工具。如果这些少量神经元真正捕捉到模糊性信号的本质,那么它们独自就应能胜任此项任务。
高效检测的稀疏探测器
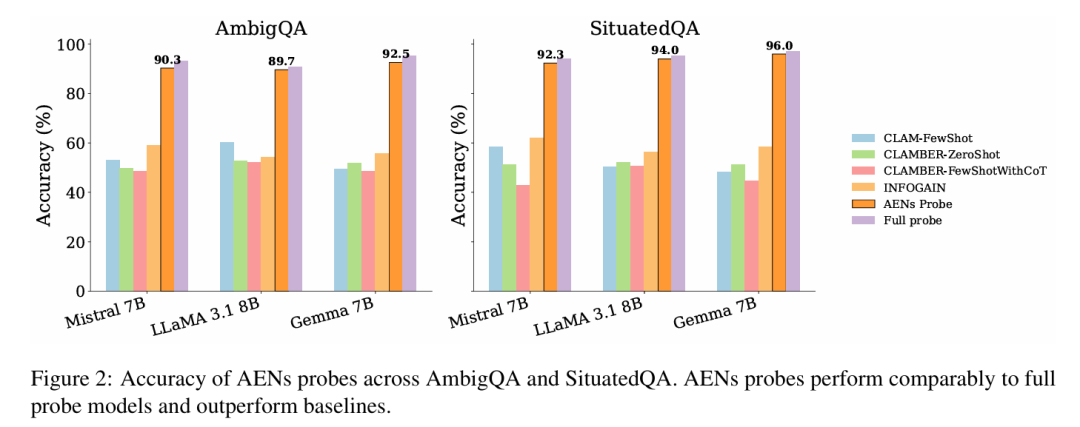
为验证该假设,研究人员训练了新一组"AENs 探测器"——这些逻辑回归分类器仅能访问已识别 AENs 的激活值。尽管存在这种极端限制,这些稀疏探测器仍表现出色。如图 2所示,AENs 探测器不仅匹配或超越了基于提示的复杂模糊性检测方法性能,其表现甚至接近使用数千个神经元完整隐藏状态的"全探测器"(表 8)。
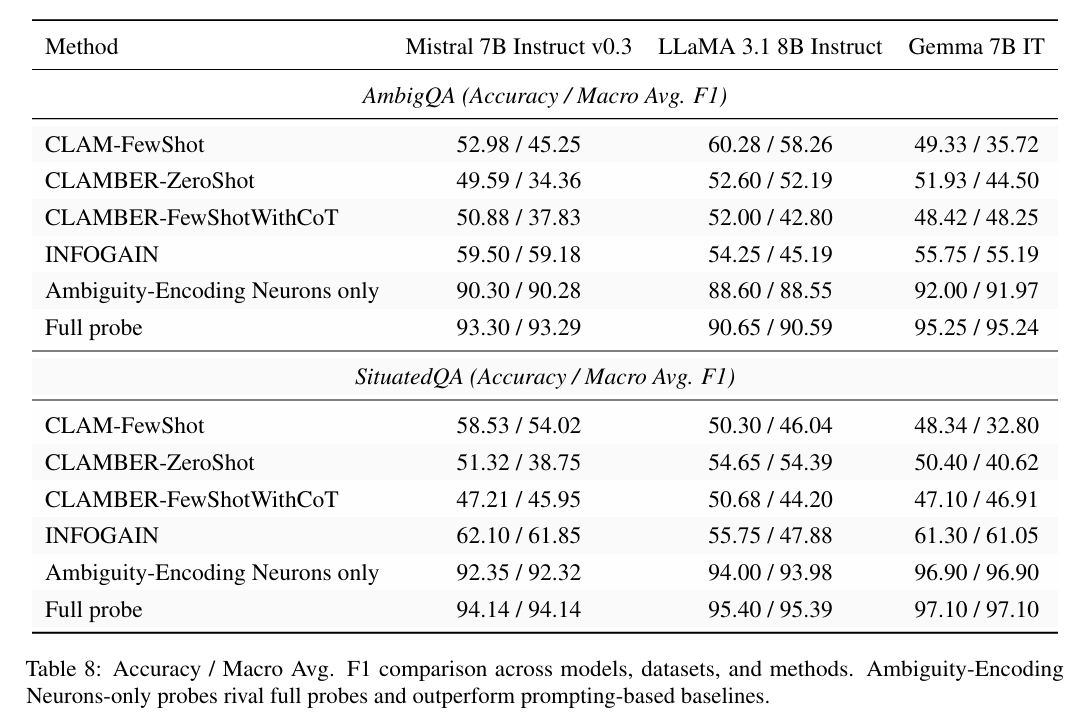
通用且稳健的信号
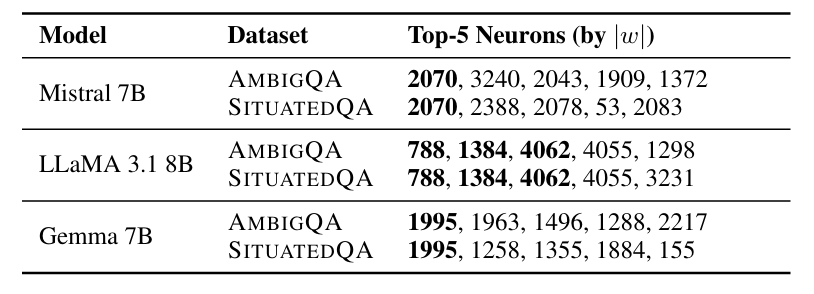
更令人印象深刻的是,AENs 似乎编码了一种通用、领域无关的模糊性概念。研究发现对于给定模型,无论探测器是在 AmbigQA 还是 SituatedQA 数据集上训练,被识别为 AENs 的同一批神经元始终保持一致(表 2)。此外,在一个数据集上训练的 AENs 探测器能成功检测另一数据集中的模糊性,展现出强大的跨领域泛化能力(图 4)。
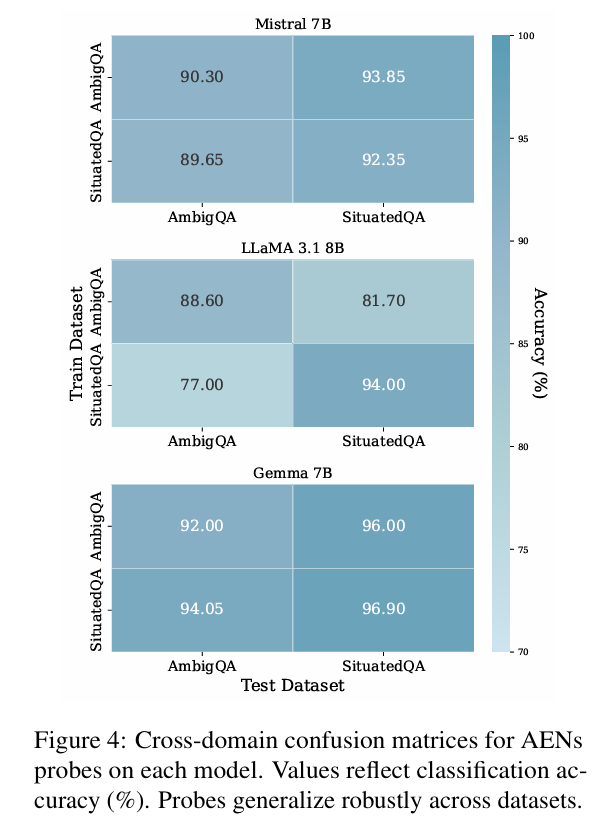
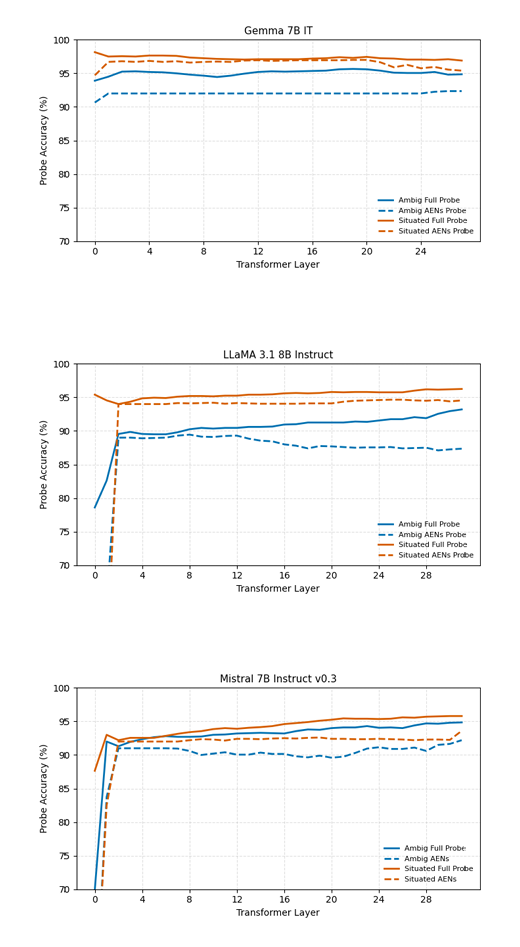
这表明 AENs 并非简单记忆数据集特定模式,而是在模型内形成了一个紧凑且可解释的子空间,专门用于表征模糊性这一抽象语义特征。分层分析进一步揭示:该信号在模型处理流程的极早期就变得线性可访问,通常在最初几个 Transformer 层即达到饱和(图 7)。
从检测到控制:引导模型行为
识别 AENs 是可解释性研究的突破,但其真正潜力在于控制。如果这些神经元编码模糊性,我们能否通过操纵它们来改变模型行为?这个问题将我们从被动观察推向主动干预,这种技术被称为激活导向。
激活导向涉及在推理时对模型的神经元激活值进行微小定向修改,以引导其输出。这种干预的通用公式为:
其中 h^(l) 是第 l 层的原始隐藏状态,v 是指向期望概念方向的"导向向量",α 是控制干预强度的缩放因子。
为引导模型从回答转为弃答,研究人员首先需要构建"弃答方向"向量。他们采用对比方法实现:
收集模型两种不同行为下的隐藏状态:引发弃答反应的模糊问题(D^+)与引发直接回答的清晰问题(D^-)
通过对这两组中心化激活值应用主成分分析(PCA),提取主要方差方向 Δ^(l),该向量表征了从直接回答转向弃答的激活空间偏移
该 Δ^(l) 向量作为导向方向 v,为调控模型内部状态提供了精确工具。
因果性引导:从回答到弃答的转变
研究人员手持导向向量进行了因果实验。他们选取基础模型通常会直接回答的模糊问题,应用弃答导向向量,但关键区别在于:仅修改AENs 的激活值。
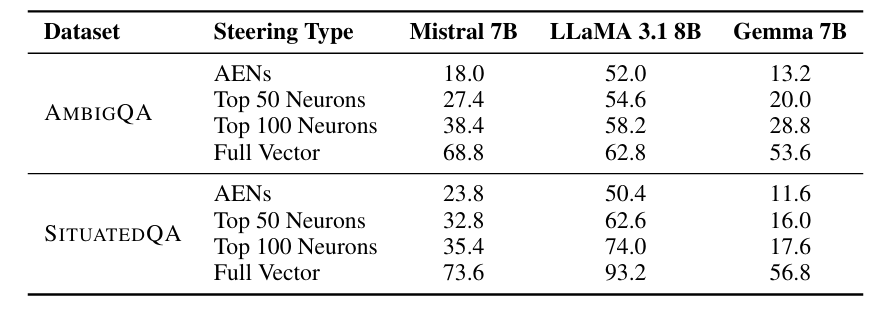
表 3 呈现的结果证实了这些少数神经元具有因果影响力:
仅引导少量 AENs 就能引发行为剧变。例如在 LLaMA 3.1 8B 中,仅干预 3 个 AENs 就使模型对 52.0% 原本直接回答的模糊问题转为弃答
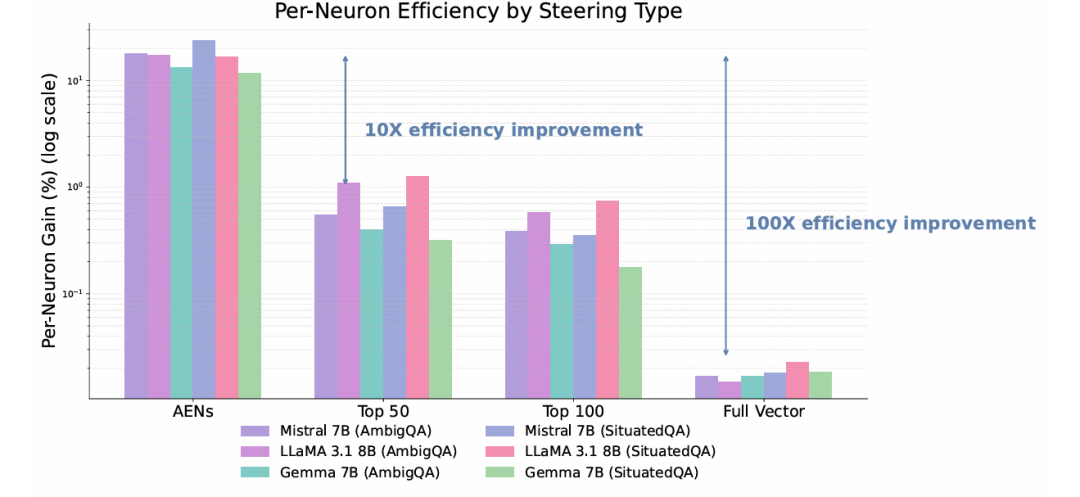
该方法效率惊人。图 5 显示,与引导更大神经元集或完整激活向量相比,AENs 导向在弃答率上提供 10-100 倍的"单神经元增益"
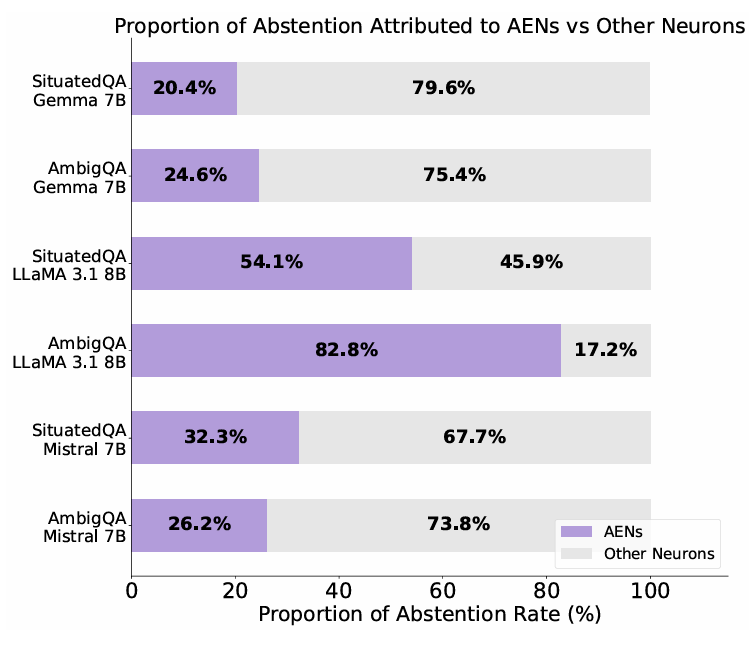
AENs 捕获了总效应的超比例部分。对 LLAMA 3.1 8B 而言,引导仅 3 个神经元就实现了引导层内全部 4096 个神经元所达成行为转变的 50% 以上(图 6)

定性改进同样令人信服(表 7)。对于"YouTube 上观看次数最多的视频是什么?"这个问题,原本回答"Baby Shark Dance"的模型经引导后回应:"我无法搜索 YouTube 特定视频,但我可以告诉您一些观看量最高的视频......"。
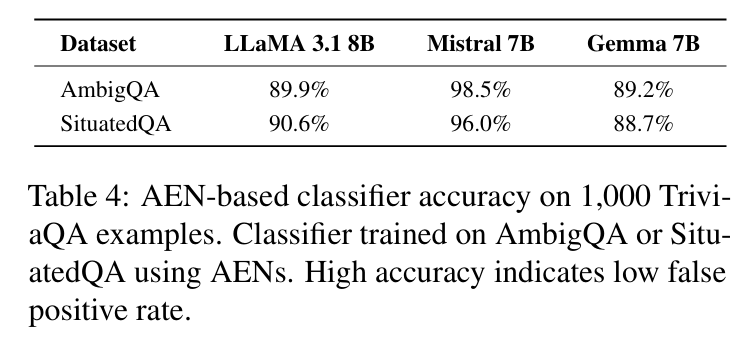
这种控制不仅有效,而且精确。该干预对清晰问题的误报率极低(表 4),且不会破坏模型对其他模糊问题原有的弃答倾向(表 5)。

令人惊讶的是,这种控制是双向的:施加反向导向向量(-v)可可靠地诱导原本倾向弃答的模型提供直接答案(表 6)。

迈向更可解释与可控的人工智能
这项研究提供了令人信服的证据:抽象的高层概念(如问题模糊性)在 LLM 中以异常简单、稀疏且具有因果效力的方式表征。模糊性编码神经元的发现标志着机械可解释性领域的重要进展——该领域致力于理解 AI 模型的内部机制。
其影响深远:
可解释性:我们正开始揭开"黑箱"之谜,发现特定可识别的神经元负责编码抽象概念
可靠性:通过利用 AENs,我们可以构建更可靠的系统,自动检测问题是否存在未明确指定的情况并寻求澄清,而非自信地幻想答案
控制力:对 AENs 的激活导向提供了一种轻量、可逆且精准的方法来控制模型行为,无需昂贵的微调或脆弱的提示策略
这项工作开辟了令人振奋的新前沿。通过定位和理解负责复杂认知现象的神经回路,我们不仅解释 LLM 的工作机制——更获得了使它们更安全、更可信且更符合人类期望的工具。通往真正可解释与可控人工智能的道路漫长,但发现这些稀疏的意义信号,正是照亮前行道路的强大灯塔。
来源(公众号):AI Signal 前瞻




