

来源(公众号):大数据AI智能圈
“哥,又来活了。”
刚入职场的AI“实习生”小R,一脸兴奋地看着我,手里捧着一堆刚从网上扒下来的资料。
这是老板刚丢过来的需求:“小R,帮我查查最近三年,Transformer模型在降本增效上,都有哪些新花样?”
小R,全名RAG(
Retrieval-Augmented Generation),是我们团队的“超级实习生”。他有个绝活,就是能把问题和他那“博闻强记”的外部知识库结合起来,生成看起来头头是道的答案。自从他来了之后,那些“我们公司最新的报销政策是啥?”或者“A产品的技术文档在哪?”之类的基础问题,再也不用我们这些“老油条”亲自出马了。
但这次,小R似乎遇到了点麻烦...
RAG:AI界的“超级实习生”,听话能干但有点“傻”
小R的工作模式,说白了就三步:检索、增强、生成。
接到任务后,他会先把老板的问题(Query)“翻译”成计算机能懂的语言(向量),然后去他的“记忆宫殿”(向量数据库)里,把所有相关的资料(Documents)都找出来。
最后,他会把问题和这些资料一股脑儿地塞给大脑(LLM),让大脑生成最终的答案。
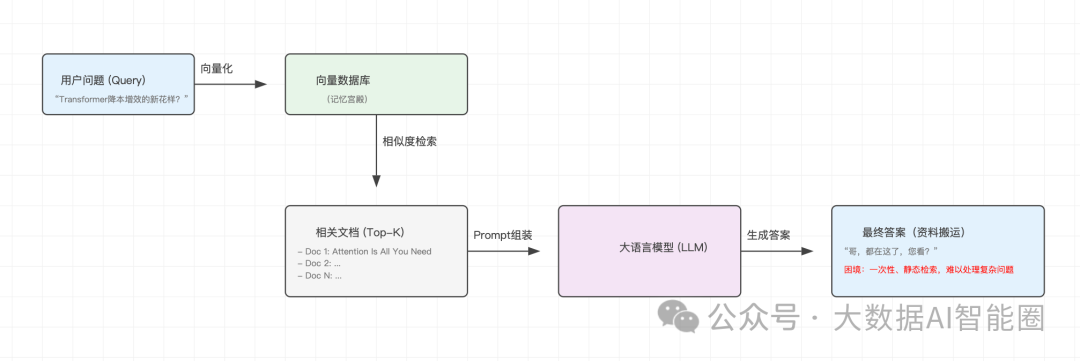
这套流程,在处理简单问题时,简直是“降维打击”。比如你问他“苹果最新的操作系统是啥?”,他能精准地告诉你iOS的最新版本,而不是给你推荐一斤红富士。
但面对老板那个“Transformer降本增效”的复杂问题,小R的“傻”就暴露无遗了。他吭哧吭哧地从知识库里拖出了一大堆文档,从2017年的“Attention Is All You Need”到最新的各种变体,一股脑地堆在我面前。
“哥,都在这了,您看?”
我看着那长长的文档列表,头都大了。这不叫“总结”,这叫“资料搬运”。
小R就像一个只会用Ctrl+C和Ctrl+V的实习生,虽然听话能干,但你让他做点需要动脑子的分析,他就“死机”了。
他不知道哪些是重点,哪些是噪音,更不知道如何从这些杂乱无章的信息中,提炼出老板真正想要的“新花样”。
这就是RAG的困境:一次性、静态的检索,让它在面对复杂、多层次的问题时,显得力不从心。 他能给你鱼,但不会教你钓鱼,更不会帮你把鱼做成一桌好菜。
DeepSearch:给实习生“加餐”,从“搬砖”到“分析”
“小R,你这样不行啊。”我语重心长地对他说,“老板要的是‘新花样’,你得有自己的分析和判断。”
为了让小R“开窍”,我们给他请了个“私教”,名叫DeepSearch。
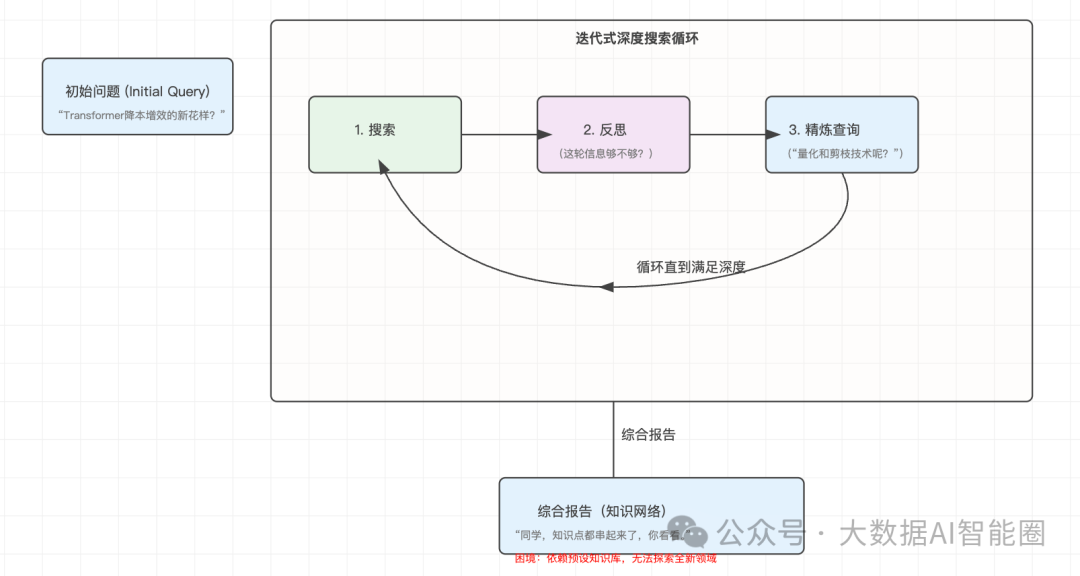
DeepSearch的到来,给小R的工作流程带来了革命性的变化。他不再是那个只会“一把梭”的愣头青,而是学会了“三思而后行”。
面对同样的问题,DeepSearch会先引导小R把问题拆解成几个小目标:
第一步: 先搞清楚“Transformer效率优化”有哪些主流方向?
第二步: 找到“2024年”的最新研究成果。
第三步: 聚焦到“计算成本降低”这个具体的技术点上。
这种分阶段检索的机制,直接给小R装上了一个“导航系统”,让他不再会迷失在信息的海洋里。
更绝的是,DeepSearch还教会了小R一个新技能:边生成边检索。在写报告的过程中,如果发现某个知识点有缺失,比如“稀疏化技术”的最新进展没覆盖到,他会立刻停下来,启动一轮新的、针对性的检索,把信息补全。
这还没完。
在DeepSearch的“调教”下,小R还学会了和团队里的其他“人”协同作战。比如,他会先让“问题规划Agent”把任务拆解好,然后让“搜索Agent”去执行检索,再让“阅读Agent”提取关键信息,最后自己(推理Agent)再把这些信息整合起来,生成最终的结论。
这套组合拳下来,小R的产出质量,直接上了一个台阶。他交上来的报告,不再是简单的资料罗列,而是有了初步的结构和分析。老板看了之后,满意地点了点头:“嗯,有点意思了。”
根据阿里云的测试,在处理3跳以上的多层次问题时,DeepSearch的检索召回率比传统RAG高出40%以上。
这背后,是对“检索质量”和“生成负担”之间平衡的精准拿捏。通过动态筛选最相关的信息,DeepSearch让大模型能把宝贵的计算资源,集中在知识整合上,而不是信息筛选上。
DeepResearch:当“实习生”学会了“独立思考”
秘塔AI的【深度研究】模式,相当于DeepResearch,如下图所示:

就在我们以为小R已经“学成出师”的时候,一个新的挑战又来了。老板说:“光有分析还不够,我需要一份关于这个主题的深度研究报告,要有洞察,有观点,能直接拿去给客户看的。”
这次,连DeepSearch都觉得有点棘手了。他能帮小R找到答案,但无法凭空创造出“洞察”和“观点”。
于是,我们迎来了终极进化体:DeepResearch。
如果说DeepSearch是小R的“研究助理”,那DeepResearch就是能独立带项目的“初级研究员”。他的出现,让小R的工作,从“信息检索”直接跃迁到了“知识创造”。
DeepResearch的工作流程,完全模拟了一个人类研究员:
1. 理解研究目标: 他会先和老板反复确认,到底想要什么样的报告。
2. 规划研究步骤: 然后,他会自己制定一个详细的研究计划,精确到每天要看哪些论文,分析哪些数据。
3. 搜集多元信息: 他不再局限于公司内部的知识库,而是会主动去网上搜寻最新的论文、技术博客、甚至是行业报告。
4. 交叉验证: 他会像一个严谨的学者一样,对比不同来源的信息,如果发现冲突,会标记出来,并优先采信更权威的来源。
5. 综合分析与报告生成: 最后,他会把所有的研究成果,整合成一份结构完整、逻辑清晰、包含摘要、方法、结果、讨论的深度报告,甚至能直接导出到Notion或Obsidian里。
前段时间,有个同事让他研究“近五年机器学习在金融风控中的应用进展”。DeepResearch只花了半个小时,就交出了一份堪比专业分析师水准的综述报告。而这项工作,如果让人来做,没几天时间根本下不来。
DeepResearch的强大,源于其Agentic AI的内核。
他不再是一个被动的工具,而是一个拥有自主规划、执行、反思、调整能力的“智能体”。他能在开放、真实的网络环境中,像人类一样自主地进行研究,处理各种噪声数据,应对信息缺失的挑战。
结语
从RAG到DeepSearch,再到DeepResearch,我们看到了一条清晰的技术进化路径:从最开始听话能干但有点“傻”的实习生,到能做分析、有条理的“研究助理”,再到能独立思考、创造知识的“初级研究员”。
这背后,是AI知识探索领域的一场“内卷”与“进化”。
RAG解决了“有没有”的问题,让AI有了可靠的知识来源。
DeepSearch解决了“好不好”的问题,让AI在复杂问题面前,能更聪明地找到答案。
DeepResearch则解决了“精不精”的问题,让AI开始拥有了创造新知识的潜力。
未来,这三者之间的界限会越来越模糊。RAG会吸收DeepSearch的动态检索能力,DeepResearch的核心组件也会被模块化,融入到更广泛的AI应用中。
但无论技术如何演进,其最终的目标,都不是为了取代我们,而是成为我们的“认知放大器”——将我们从重复、繁琐的知识搬运工作中解放出来,让我们能专注于那些真正需要创造力、洞察力和同理心的工作。




