

标题:StyleBench: Evaluating thinking styles in Large Language Models
日期:2025-09-25
机构:University of California, Berkeley, Virginia Tech
链接:http://arxiv.org/pdf/2509.20868v1
一句话总结:本文推出StyleBench综合基准,通过多样化任务和15个大语言模型系统评估五种推理风格,揭示策略有效性高度依赖于模型规模与任务类型。
大型语言模型的多种“思维风格”
大型语言模型(LLM)的强大之处远不止于其庞大的参数量。决定其在复杂任务上成功的关键因素在于引导其推理过程的方法。用户不能简单地要求模型直接输出答案,而通常需要通过提示使其以结构化方式“思考”。这推动了多种提示技术的发展,这些技术常被称为“推理风格”或“思维模式”。
早期突破性技术如思维链(CoT)表明,仅需要求模型进行逐步思考,就能显著提升其数学和逻辑问题的解决能力。此后,更复杂的技术呈现寒武纪式爆发,形成了并行推理路径、迭代草稿甚至算法回溯等多元方法。然而,这些不同推理风格、特定LLM与任务性质之间复杂的相互作用仍未被充分理解。这留下了一个关键问题:如何为特定任务选择正确的思维风格,以实现性能与效率的最佳平衡?
StyleBench:系统性评估框架
为应对这一挑战,研究者推出了StyleBench——一个旨在系统评估不同推理风格在多样化场景下性能的综合基准。这并非简单的性能排名,而是对LLM认知机制的深度探索。
该评估涵盖广泛维度:StyleBench在五类推理任务(包括数学问题、常识问答和逻辑谜题)上测试五种不同推理风格;研究涉及LLaMA、Qwen、Mistral和Gemma等主流系列的15个前沿开源模型,参数规模从灵巧的2.7亿到庞大的1200亿不等。核心目标是超越个案经验,为任意应用场景选择最高效推理策略提供清晰的经验性指导。
思维分类学:从线性链到搜索树
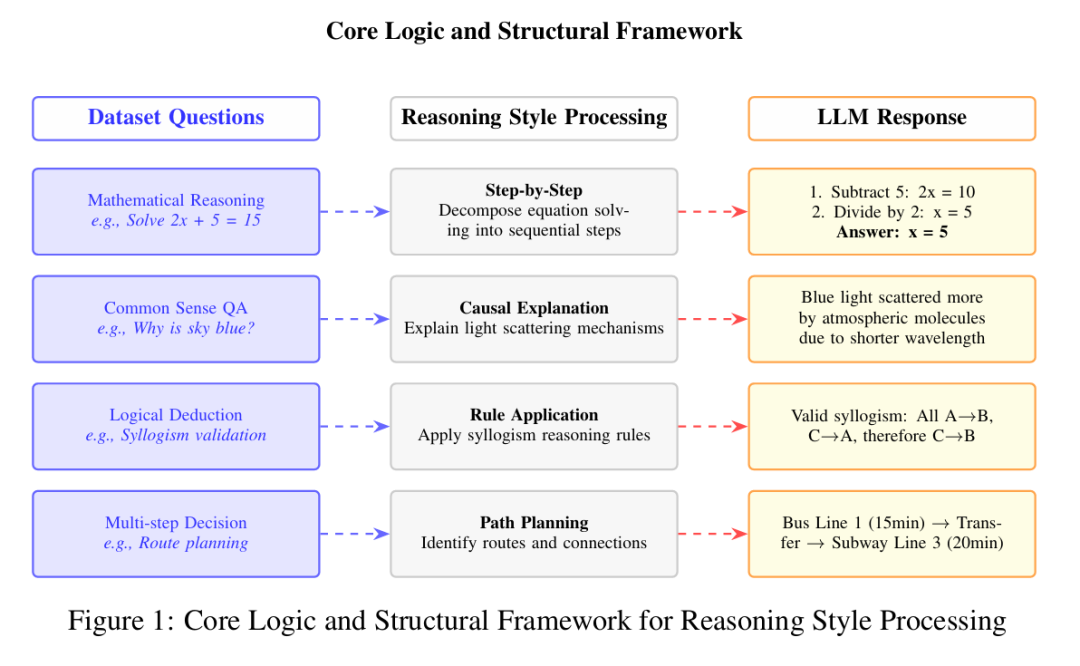
StyleBench对五种代表性“思维风格”进行分类评估,每种风格以不同方式构建模型的问题解决流程。理解这些风格是释放LLM全部潜能的关键。图1直观呈现了这些处理框架的核心逻辑。
序列式风格
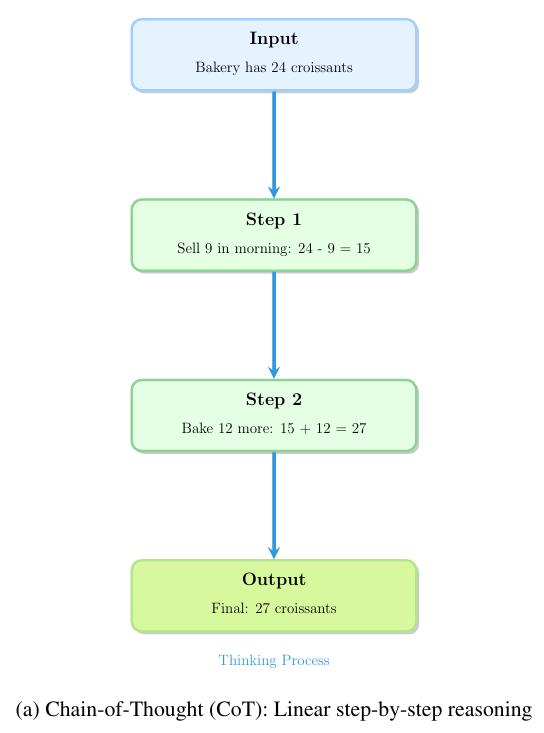
思维链(CoT):作为基础技术,它要求模型将问题分解为线性步骤序列,类似于人类展示解题过程。通过生成显式推理轨迹,该方法简单有效。示例可参见图4a。
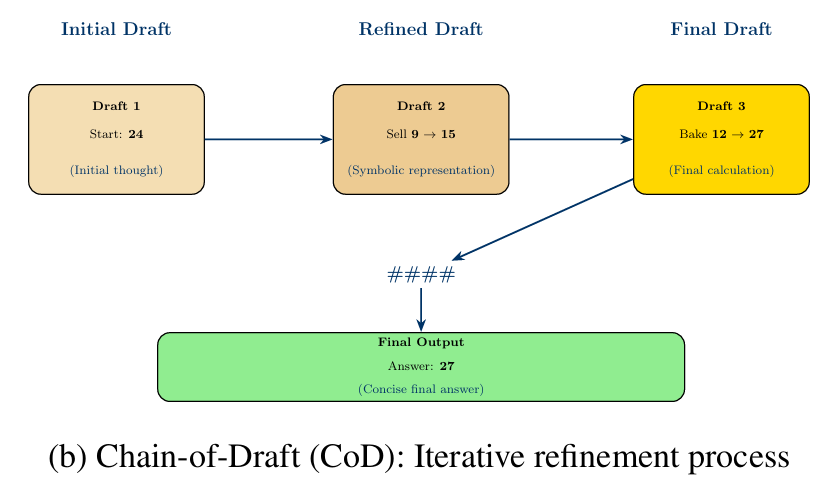
草稿链(CoD):该风格追求简洁性,约束模型生成凝练的符号化推理轨迹,通过迭代优化解决方案“草稿”。通过少样本示例引导,输出形式如,该过程如图4b所示。
路由式风格
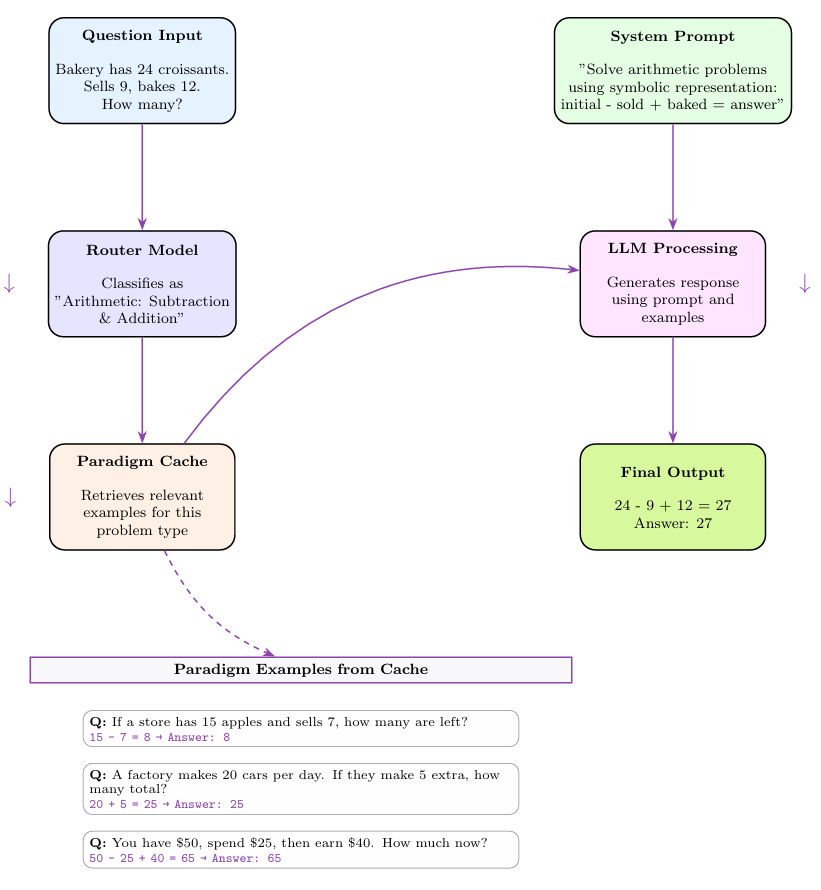
思维草图(SoT):采用巧妙的两阶段处理:首先由训练的“路由模型”识别问题类型,随后检索该类问题的解决范例来增强提示。在保持透明度的同时鼓励符号化简答,如图6所示。
搜索式风格
思维树(ToT):将推理视为搜索问题,允许模型同步探索多条并行推理路径(树的分支),评估后剪枝低潜力路径,实现解空间的系统性探索(图5b)。
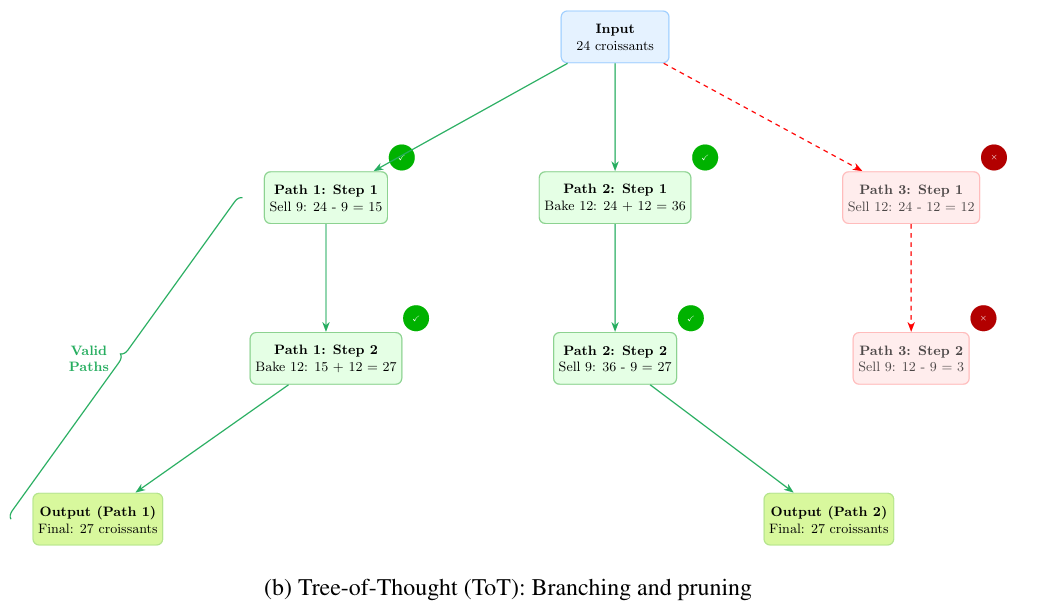
算法思维(AoT):受经典算法启发,该方法实现回溯搜索,使模型能够撤离无效推理路径并探索替代方案,通过避免死胡同有效模拟算法化问题解决(图5a)。
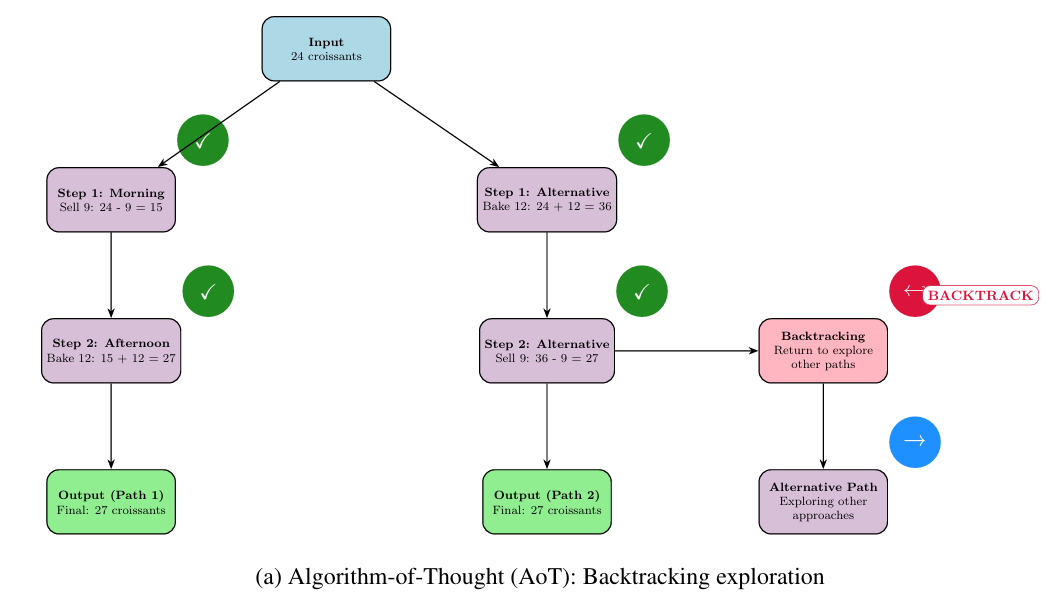
表1对比了这些风格在处理数学问题时的提示词构建方式。

规模效应:模型参数量的影响
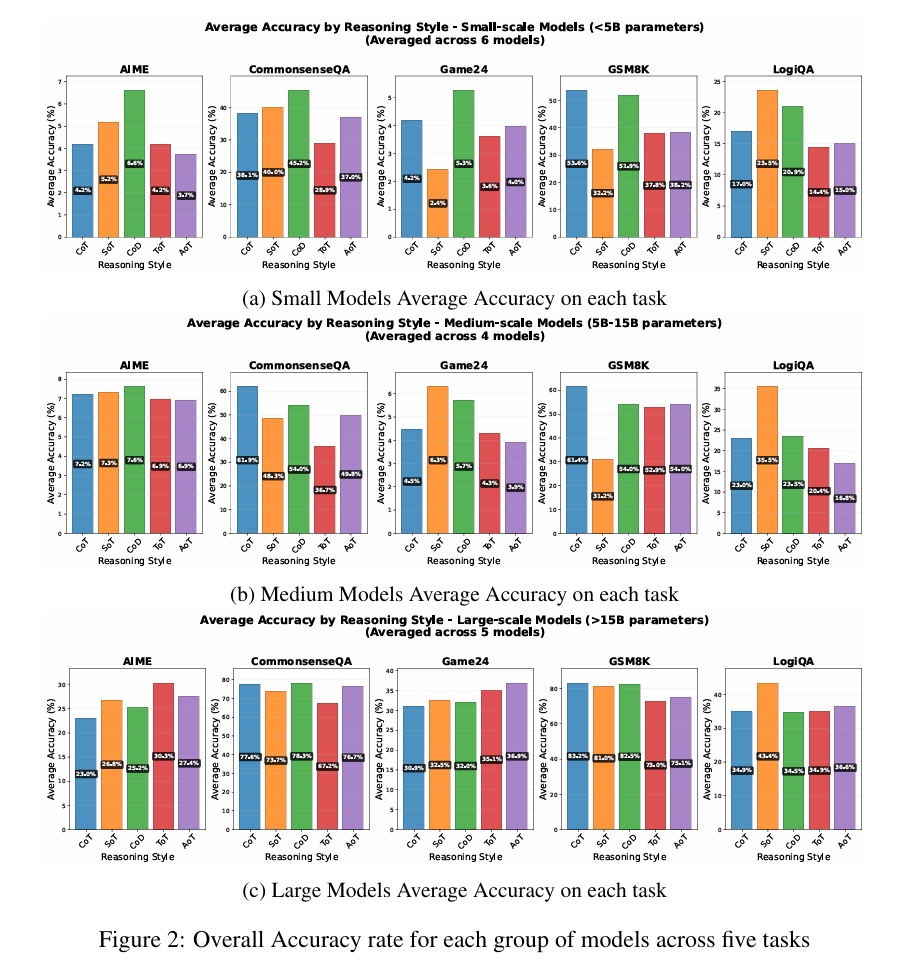
StyleBench的核心发现表明:虽然模型规模越大性能越优,但规模收益在不同思维风格间并不均衡。所有推理策略的性能随模型尺寸增加而提升,但提升速率存在显著差异。
基于搜索的策略(如ToT和AoT)呈现明显的缩放定律:它们在挑战性开放任务上的优势仅在大规模模型(超过150亿参数)上凸显;在中小型模型上,复杂搜索机制几乎不产生增益,表现为“平庸”结果。这表明有效管理复杂搜索空间是大型模型涌现的能力。
相比之下,CoD被证明是从最小到最大所有模型规模中最稳定、最鲁棒的风格,使其成为资源受限环境下的可靠选择。图2展示的不同规模模型组在跨任务中的聚合准确率清晰印证了这些缩放 dynamics。
无万能解:推理风格与任务匹配
研究最重要的结论是:不存在单一最优推理风格。最佳选择高度依赖于具体任务。研究发现了强烈的“任务-风格亲和性”,为实践者提供了急需的导航图。
数学推理(GSM8K):令人惊讶的是,最简单的CoT在所有模型规模上持续优于其他风格。这表明对于结构化多步问题(如小学数学),直接序列分解不仅足够且最优。
逻辑推理(LogiQA):需要逻辑演绎的任务中,SoT成为明显优胜者。研究推测这是因为逻辑任务极大受益于SoT提供的结构化符号轨迹和相关少样本示例,使模型能高效应用形式推理规则。
开放谜题(24点游戏):对于需要组合搜索的创造性谜题,ToT和AoT的分支回溯方法最有效,但该优势仅体现在能驾驭复杂搜索空间的大型模型中。
常识推理(CommonsenseQA):依赖知识检索的任务中,CoD和SoT的简洁风格通过高效直接的回答实现最佳性能。值得注意的是,大型模型中所有推理风格表现相当,表明模型更多依赖内在知识库而非复杂推理来解决问题。
从猜测到推理:不同规模模型的行为模式
除聚合准确率外,StyleBench揭示了不同规模模型间有趣的行为差异。
小模型的猜测游戏
关键发现是:小模型(<50亿参数)在困难任务上的失败并非因为耗尽生成长度,而是缺乏必要的推理能力。它们往往“默认采用猜测”而非尝试复杂推理链,可能生成表面结构化但逻辑荒谬的响应。例如在AIME数据集案例中,小模型执行多个正确步骤后却在验证阶段犯关键错误,仍自信输出错误最终答案(论文附录D.1详述)。这表明小模型的主要瓶颈是推理能力缺失而非生成能力不足。
指令跟随作为涌现技能
可靠遵循指令的能力(如用\boxed{答案}格式化输出)随模型规模显著提升。小模型频繁忽略此类指令,对依赖格式的自动评估系统构成挑战。该行为源于预训练模式,小模型缺乏覆盖这些模式的能力,即使获得明确指令。
token使用与效率
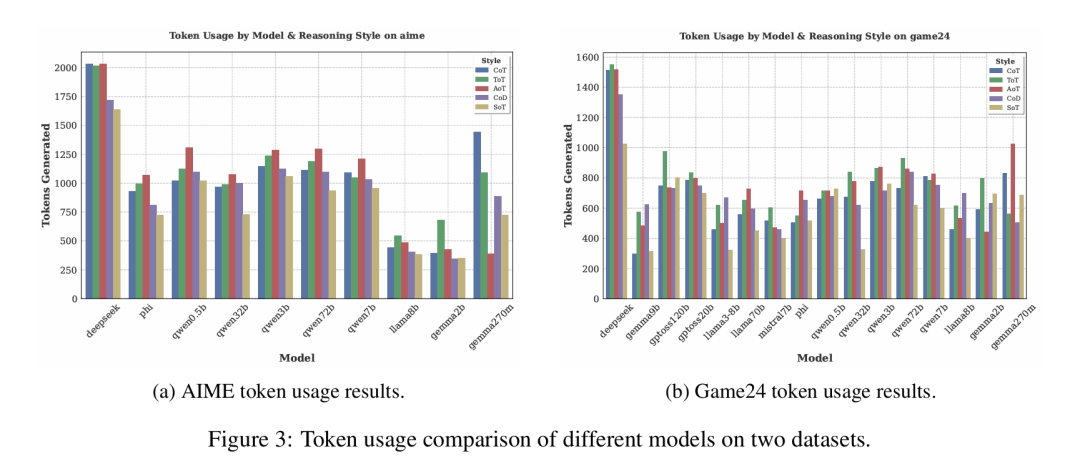
与直觉相反,小模型在困难任务上并不总是消耗更多token。如图3所示,它们常在生成猜测答案后提前终止生成。而基于搜索的AoT和ToT方法因探索性质天然需要更多token。对于LogiQA等结构化任务,SoT和CoD等简洁方法效率显著,在保持高精度的同时分别比CoT缩短94%和16%的生成长度。
选择最优推理策略的实践路线
如何将这些洞察应用于实践?研究探索了能否微调LLM使其自主选择最佳推理风格。结果表明这种“元推理”能力尚未成熟:经训练的模型仅学会默认选择训练数据中最频繁最优的风格(CoD),而非形成真正的上下文感知选择策略(图14)。
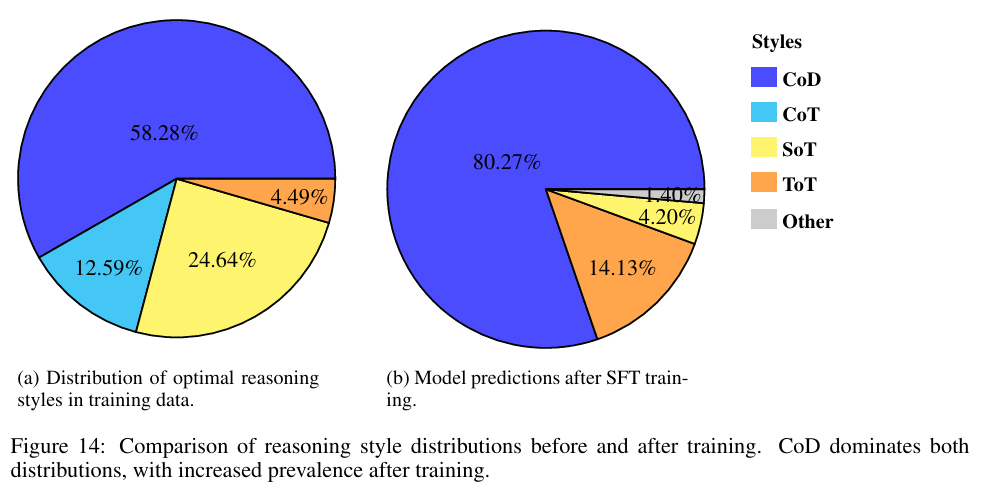
在模型能可靠自选策略之前,我们可以将StyleBench的发现作为实践路线图:
复杂开放问题(如谜题、战略规划):
若能使用大规模模型(>150亿参数),采用ToT或AoT等搜索方法,其探索回溯能力极具价值
否则(使用小模型时),这些方法可能无效,简易风格或更可靠(但不保证成功)
结构化序列问题(如数学应用题、逻辑演绎):
首选CoT,其简洁性和已验证效果使其成为强基线
对于符号表示有益的任务(如逻辑推理),考虑SoT以获得更优性能
效率关键场景(低延迟、低成本)或使用小模型时:
倾向SoT和CoD等简洁风格,它们在常识QA和符号推理等任务上提供精度与计算成本的最佳权衡
通过建立这些缩放定律和任务-风格亲和性,StyleBench研究为利用当今大型语言模型构建更高效、鲁棒且强大的推理系统奠定了重要基础。
来源(公众号):AI Signal 前瞻




