

作者:范老师|数据研发DE
来源(公众号):数据仓库与Python大数据
你有没有这样的经历?
早上9点,产品经理拿着新需求敲你工位:“这个报表今天能上线吗?”
下午3点,运营紧急找你:“昨天的数据对不上,能不能重新跑一遍?”
晚上8点,开发同事私聊:“上游表结构变了,下游逻辑要跟着改。”
凌晨1点,你终于提交代码,系统却报错:“历史分区数据类型不兼容。”
周六上午,你被电话叫醒:“上个月的财务数据要审计,麻烦回溯一下。”
如果以上每一条都戳中了你的心,那么——
欢迎来到数仓人的日常。
我是范老师,一名从业10年的数据仓库专家,带过3个团队,经历过5次大型数仓重构,也曾在凌晨三点为一条SQL跑通而热泪盈眶。
今天,我不想讲技术原理,不谈架构设计,只想和你聊聊——一个真实数仓人的“生存现状”。
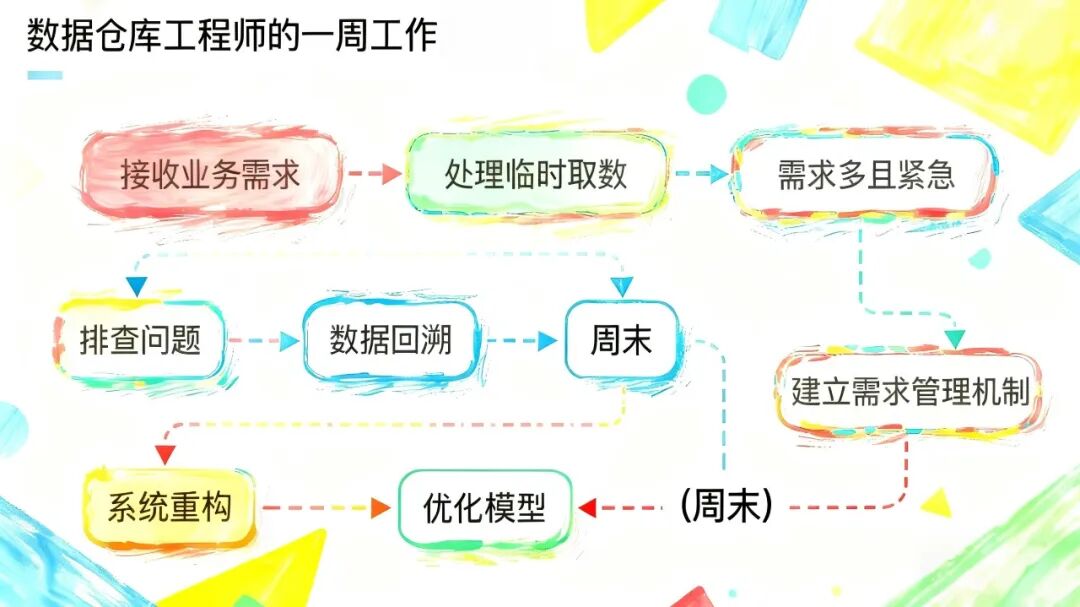
一、白天接需求:我不是开发,我是“人肉ETL”
在很多业务眼里,数仓工程师 = 会写SQL的Excel高手。
“范老师,能不能帮我加个字段?”
“能不能把A表和B表关联一下?”
“这个指标能不能按小时拆分?”
听起来简单?但每一个“能不能”,背后都是:
数据源是否稳定?
字段定义是否清晰?
指标口径是否统一?
历史数据是否可追溯?
更可怕的是,同一个指标,10个人有11种定义。
财务要的“GMV”不含退款,运营要的“GMV”含退款,老板看的“GMV”还包含虚拟订单……
而你,是那个必须把它们全部对齐的人。
我们不是在做技术,我们是在做“数据外交”。
二、晚上重构:昨天的方案,今天就过时了
三年前,我亲手搭建了一套基于Hive的离线数仓,引以为傲。
结果——
业务增长太快,T+1的报表已经不够看;
实时数仓兴起,Flink + Kafka 成了标配;
公司上云,数据湖方案又成了新方向;
最近老板说:“我们要做数据中台。”
于是,我花了三个月设计的架构,三个月就进了博物馆。
更扎心的是,每一次重构,都是从“历史数据回溯”开始的。
你得保证新旧系统数据一致,否则财务、审计、BI全部找上门。
我曾为了对平一个0.01%的差异,连续三天翻查日志、比对中间表,最后发现是某个字段的时区转换问题。
那一刻,我深刻理解了什么叫——
“数据无小事,差之毫厘,谬以千里。”
三、周末回溯:你以为的“技术债”,其实是“业务债”
“范老师,上个月的用户留存率为什么比前年同期低了5%?”
“能不能把2024年的数据重新算一遍?”
每当听到这种问题,我就知道——周末没了。
数据回溯有多难?
原始日志可能已经过期;
上游系统早已迭代,接口不复存在;
中间表被清理,血缘关系断裂;
当年的开发人员早已离职。
我们不是在查数据,我们是在“考古”。
更讽刺的是,很多问题,本可以在数据采集阶段就避免。
比如:
没有统一的数据标准;
没有完善的元数据管理;
没有数据质量监控;
没有版本控制和变更日志。
结果呢?技术团队背锅,数仓工程师加班。
四、为什么我们总在“救火”?——三大根源问题
根据我这10年一线实战经验,数仓团队陷入“永动救火模式”的根本原因,逃不开这三点:
1. 数据产业链生态不完善
“数据应用场景不够丰富,服务支撑存在不足。”
翻译一下:
业务方不懂数据,随意提需求;
缺乏专业的数据产品经理;
没有规范的数据服务流程。
结果:数仓团队成了“万能接口人”。
2. 数据开发利用技术存在短板
“国内在FPGA、GPU等领域缺乏具有竞争力的原创性产品,数据库领域对外依赖度高。”
虽然我们用的是Hive、Spark、Flink,但底层技术受制于人,性能调优难,扩展成本高。
更别提:
实时计算资源昂贵;
数据血缘工具不成熟;
自动化测试覆盖率低。
技术不成熟,只能靠人力填坑。
3. 数据要素市场化水平不高
“数据产权不明确,权责不清,交易模式不成熟。”
在企业内部也一样:
谁生产数据?谁拥有数据?谁负责质量?
没有明确的“数据Owner”机制;
数据资产无法量化,更无法入表。
数据成了“公共品”,谁都可以用,谁都不负责。
五、范老师给数仓人的5条生存建议
别灰心,问题虽多,但总有出路。
结合我在多家大厂的企业数据仓库与数据治理项目中的经验,送你5条“保命指南”:
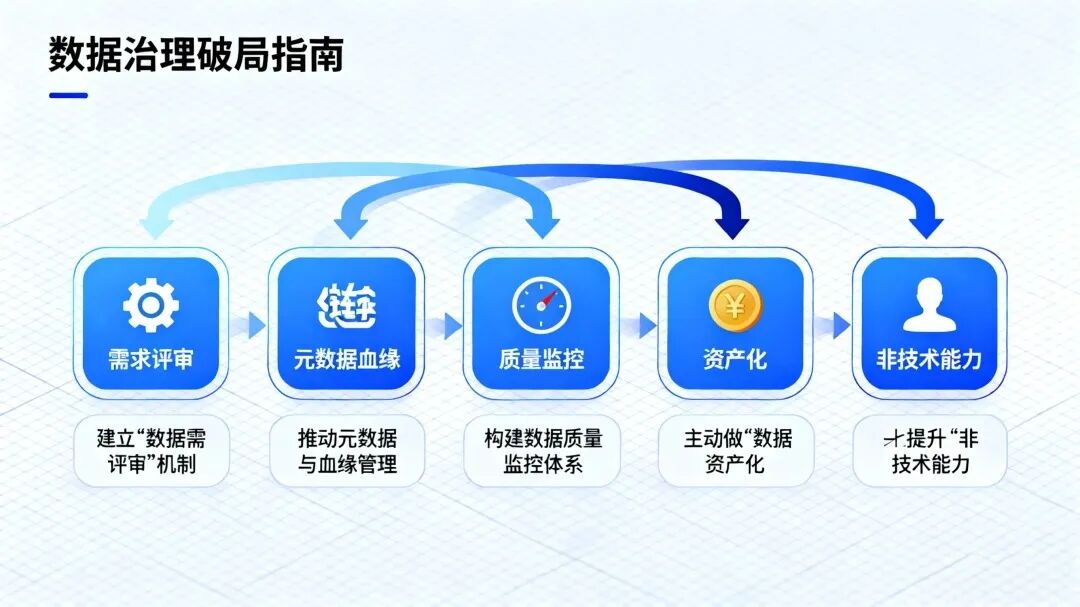
✅ 1. 建立“数据需求评审”机制
拒绝“口头需求”,所有需求必须走工单,明确:
指标定义
使用场景
口径来源
更新频率
让业务为需求负责,而不是你为结果背锅。
✅ 2. 推动元数据与血缘管理
用DataHub、Atlas等工具,自动采集表结构、字段说明、上下游关系。
当有人问“这个数据从哪来”,你能秒回一张血缘图。
可视化,是最好的防御武器。
✅ 3. 构建数据质量监控体系
空值率监控
唯一性校验
波动阈值告警
分区完整性检查
让问题在T+0暴露,而不是T+7被追责。
✅ 4. 主动做“数据资产化”
参考《关于构建数据基础制度更好发挥数据要素作用的意见》,尝试:
给核心数据表打标签(敏感度、重要性)
输出《数据资产目录》
推动“数据资源入表”试点
让数据变成看得见、管得住、用得好的资产。
✅ 5. 提升“非技术能力”
学点项目管理,学会说“不”;
懂点财务知识,理解业务逻辑;
练练表达能力,能把技术讲成故事。
未来的数仓人,不是码农,而是“数据翻译官”。




