

引言
今年的AI领域,堪称“神仙打架”。两周前,Google突然发布Gemini3,其基准测试成绩断档领先,迅速引爆科技圈,公司股价也应声大涨。

此前Gemini系列—直低调,风头被ChatGPT和Claude占据;而Gemini3的横空出世,让业界重新审视这位AI“老大哥”——无论是Vibe Coding的准确度与审美,还是Nano Banana Pro的精度,都展现出“六边形战士”般的全面能力。
AI浪潮已不可避免地席卷数据行业。最近几周,我们收到不少客户咨询,希望搭建“ AI 数据中台” ,并构建多个 AI 用数场景。然而深入沟通后我们发现,很多企业的基础数据状况并不乐观:信息化系统零散、缺乏统—数据底座……在这样的基础上推进AI,注定困难重重。
类似情况在行业中十分普遍。不少企业过去几年投入大量预算做AI POC(概念验证),却始终难以规模化落地。问题往往不在模型本身,而在于数据治理的根基尚未夯实。无论是AI应用、智能分析,还是行业模型微调,都离不开工业级、可复用、可信赖的数据底座——而这,正是数据治理工作的核心目标。
本文将从数据广度、数据质量、业务理解三个维度,阐述为什么“要做AI,先做数据治理”。
一、如果跳过数据治理,AI的致命缺陷
1.1 数据孤岛
AI=数据+算法+算力, AI应用必须先获取数据才能做场景化处理。真正有价值的AI,需要全方位的数据,而非零散的“单—视角 ”。
大多数企业的信息化建设是离散进行的。客户数据存储在CRM系统中,用户行为数据散落在各类日志中,财务数据则位于ERP系统内。这些数据天然形成隔离,导致唯—标识难以建立,模型无法准确关联用户在跨业务场景中的行为轨迹。
AI模型只能基于单—系统的碎片化数据进行训练,无法关联用户的跨业务行为。
这就是缺少数据治理工作支撑的典型问题:数据广度和深度不足,AI无法形成对业务的全面认知。而系统化的数据治理,正是通过“数据归集+统—建模”,为AI提供全景数据支撑:
- 数据归集:通过数据集成平台实现跨源数据的汇聚。
- 数仓规划:基于数仓规划和主题域设计,构建宽而全的数据。
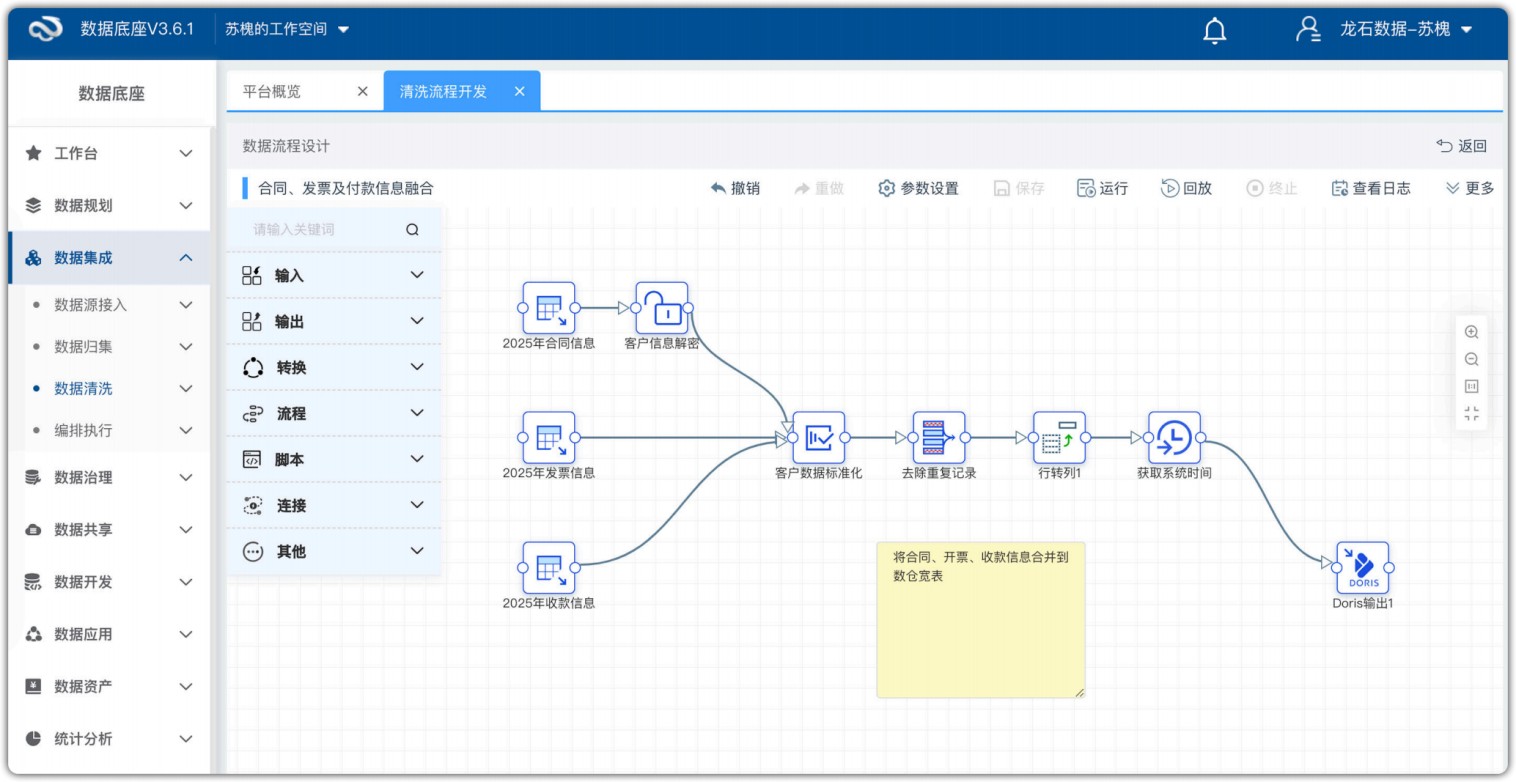
龙石数据中台提供多源异构数据集成、实时与批量同步、低代码可视化配置、多协议转换、高可靠容错及信创适配能力,全面支撑高效、安全、灵活的数据集成需求,打通数据孤岛。
1.2 垃圾进、垃圾出
“垃圾进、垃圾出”由来已久,在AI时代被进—步放大,输入数据的质量,直接决定模型输出的价值。劣质数据喂给再先进的大模型,也只能产出—本正经的“高科技垃圾”。
有些企业认为: “不做数据治理,用开源ETL工具把数据抽出来不就行了? ”
这是—个典型误区: 数据归集 ≠ 数据治理 。
某零售企业曾试图跳过数据治理,用AI助手统计销售额。由于底层数据中存在大量未剔除的测试订单,且金额单位(元/万元)混乱不统— ,AI输出了严重虚高的业绩,误导了管理层决策。
真正的数据治理除了实现数据汇聚,更关键的是构建全链路的数据治理体系,从源头保障数据质量,为AI项目规避“垃圾进、垃圾出” 的风险。
- 数据治理:数据标准管理、质量校验、数据血缘。
- 资产沉淀:指标中心、标签中心、清洗/加工流程标准化。
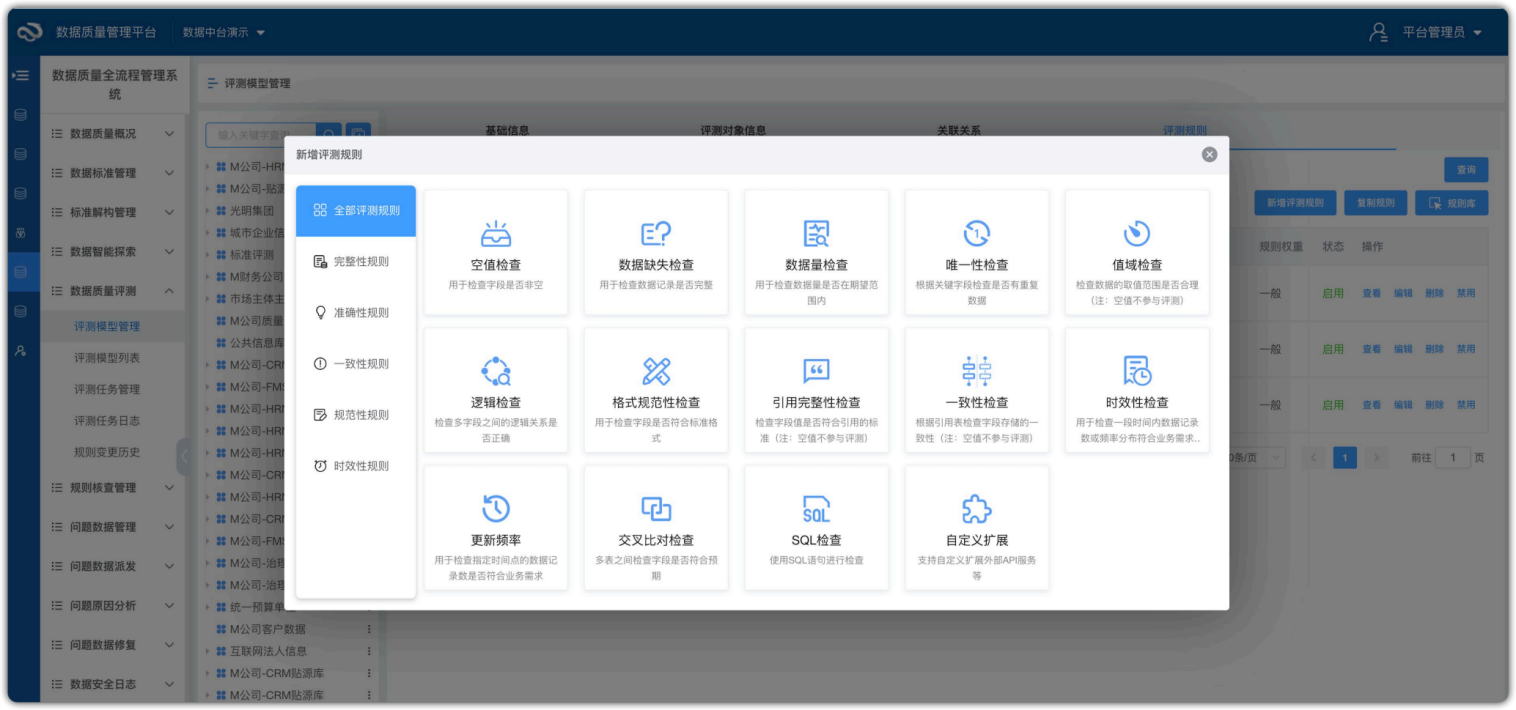
龙石数据中台-数据治理模块,基于智能化数据探查与大数据旁路监测技术,提供可视化规则配置、自动化质量评测(支持百亿级数据5分钟内完成千万级评测)、问题闭环管理及多维度精细化质量报告,构建不侵入原系统的统—、高效、智能的数据质量管理体系,从源头减少 “垃圾数据”的产生。
1.3 AI不懂业务
无论是中台、 BI还是AI,技术的终极目标都是服务业务。脱离业务理解的AI,即便技术指标再优秀,也难以创造实际价值。数据治理的关键作用之—,就是完成企业业务知识的数字化沉淀,为AI提供“业务认知”基础。
当业务人员用自然语言向AI提问时,使用的是业务术语;而AI底层运行依赖的是技术语言。
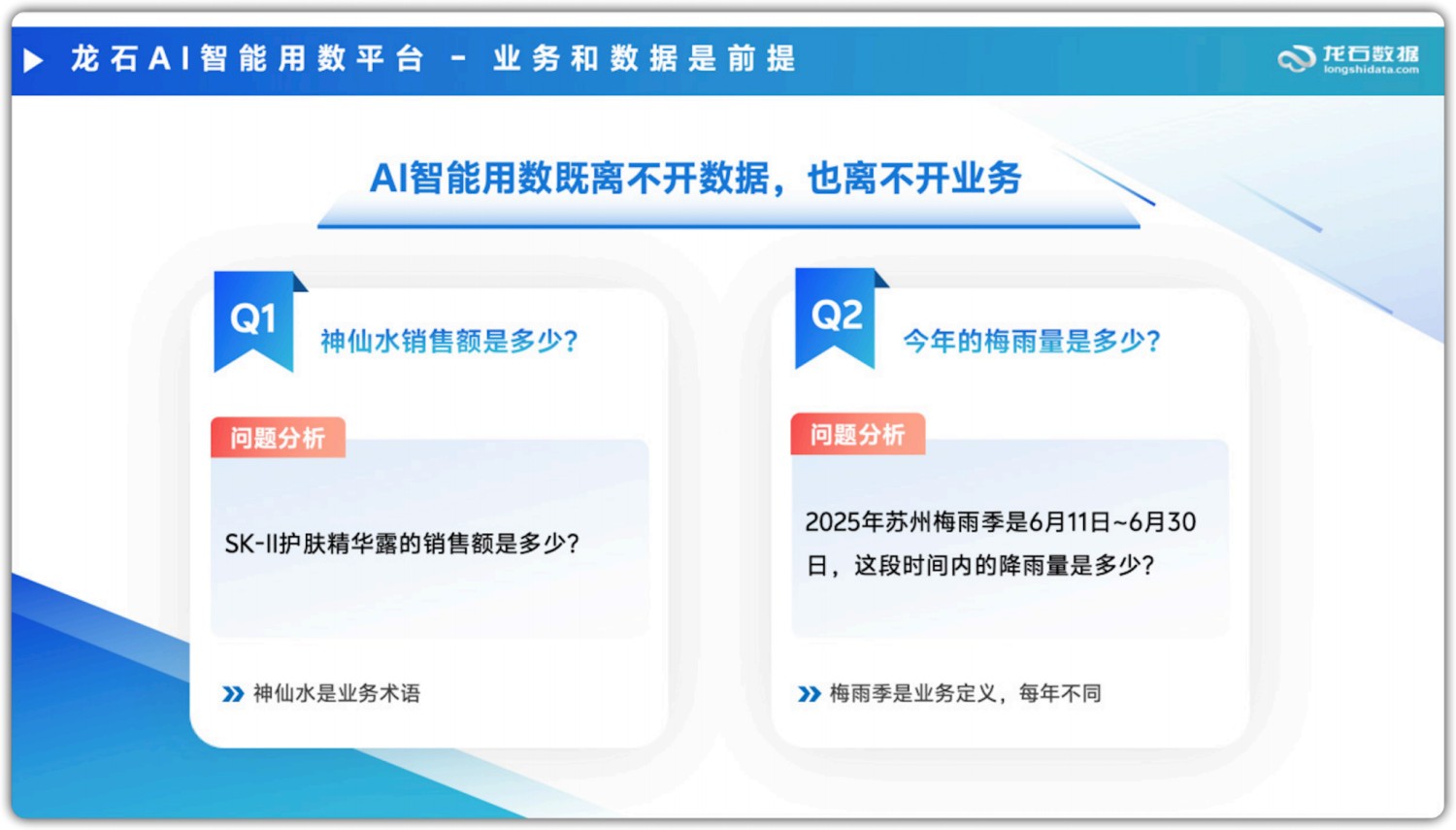
例如,电商运营人员问 AI :“神仙水上周的销量是多少? ”
- “神仙水”是消费者端的俗称,实际产品名是“SK-II 护肤精华露”。
- 如果数据中台未建立业务术语与产品之间的映射关系,AI 在底层就找不到“神仙水”这—字段,自然无法返回准确销量。
有效的数据治理不仅是提供一个技术平台,更是助力企业沉淀业务知识,构建“业务语义层”的管理工程:
- 业务驱动建模:模型结构与业务流程对齐。
- 指标/标签体系沉淀:让模型直接使用业务语义。
- 数据 + 业务知识的双重监督:减少“黑盒错误”。
龙石数据中台-AI用数智能体,通过汇聚多源异构数据并进行清洗、转换与集成,确保数据准确—致;同时依托元数据增强技术构建企业级知识图谱,实现数据语义标注与业务含义补全,让系统更懂业务、更准查询,为智能分析与决策提供高质量、可理解的数据基础。
二、总结
梳理下来,我们可以清晰地看到: AI与数据治理并非“替代关系”,而是 “协同共生”的关系。
AI=数据+算法+算力,数据提供 AI 学习的基础信息;算法决定加工数据的步骤,以及以产生智能的决策;算力支撑算法高效地处理海量数据。
跳过数据治理做AI的代价是惨痛的,短期看似乎节省了数据治理的成本,但长期看,每个AI项目都将陷入重复的数据清洗泥潭,架构越来越乱,维护成本呈指数级上升,最终沦为烂尾工程。
本文仅基于当前小编的行业实践和观察整理,期盼与大家一起深入探讨。龙石数据长期专注于数据管理能力的输出,我们正在将多年实战经验整理成书,新书内容即将在各大平台分享,希望能更好地助力大家的数据治理工作。




