

❝
上周五下午五点半,老张刚准备下班,产品经理突然冲到工位前:"
张工张工!老板要看全国各区域的销售数据汇总,现在就要!"老张抬头看了看窗外,心里一万头草泥马呼啸而过...华东的数据在杭州集群,华北的在北京集群,华南的在深圳集群,这要跨三个Doris集群做联合查询!
按照以前的套路,要么写JDBC Catalog慢慢等,要么就得临时把数据同步到一个集群——前者慢得让人怀疑人生,后者等数据同步完周末都过去了。
老张急忙翻阅了下 Doris 4.0.2版本的 release note,突然不紧不慢地说道:"给我半小时..."
Doris跨集群查询的老大难,终于有解了
说起跨集群数据分析,做过大数据的人都知道这有多头疼。
你们公司是不是也这样:业务发展快了,一个Doris集群不够用,就搞了好几个。交易数据在A集群,物流数据在B集群,用户画像在C集群。
平时各自安好,但老板一句"我要看全局数据",技术团队就开始抓狂。
传统的JDBC Catalog确实能用,但用过的人都懂那个痛。
协议开销大得吓人,查询优化策略用不上,简单查询还行,遇到复杂的Join和聚合,性能能把人逼疯。
有个朋友跟我吐槽过,他们用JDBC Catalog跨集群查个订单履约率,单表聚合查询愣是跑了45秒,老板在会议室等得直拍桌子。
更要命的是,数据量一大,JDBC那套基于MySQL协议的玩法就彻底歇菜。
你看着查询进度条一点点爬,心里默念"快点快点",但它就是快不了。这不是咱技术同学偷懒,而是协议层面的先天不足!
but,Doris团队这次是真狠,连自己都不放过。
他们大概也意识到,光支持Iceberg、Paimon、Hudi、JDBC...这些外部数据湖还不够,Doris自己跨集群访问性能不行,这个湖仓一体的故事就讲不圆。
于是乎,Doris Catalog应运而生,专门用来解决Doris集群之间的高效联邦查询。
测试数据更是让人眼前一亮。
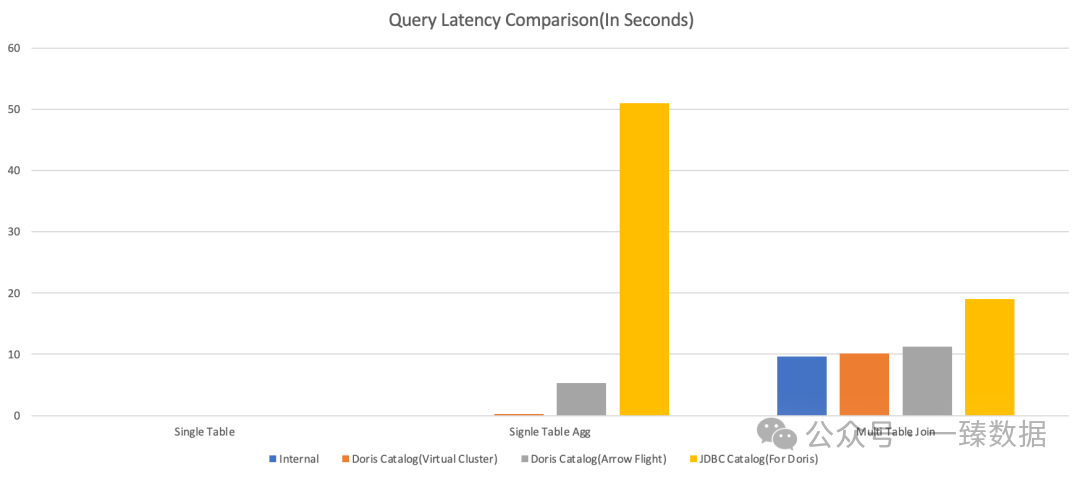
在TPC-DS基准测试中,单表聚合查询场景下,Doris Catalog虚拟集群模式的查询耗时只有0.21秒,而JDBC Catalog需要40+秒——性能提升超过200倍。
这已然不是小打小闹的优化了,可谓是质的飞跃。多表关联查询也有42%的性能提升。虽然没有单表聚合那么夸张,但对于复杂业务分析来说,这个提升已经足够显著。
两种模式各显神通,按需选择
Doris Catalog提供了两种访问模式:Arrow Flight模式和虚拟集群模式。
这个设计思路挺有意思,不是一刀切的方案,而是让你根据实际场景灵活选择。
Arrow Flight模式的设计很聪明。
它让本地集群的FE节点生成查询计划,针对远端表生成单表查询SQL,然后通过Arrow Flight协议直接从远端BE节点拉取数据。
整个过程就像是在本地集群做了个"远程调用",简单直接。
这种模式特别适合那种查询逻辑简单、但远端集群规模大的场景。
比如你只是想从另一个集群拉取某张表的数据做个UNION操作,用Arrow Flight模式最合适不过。
协议开销小,传输效率高,不需要复杂的查询优化。
虚拟集群模式就更有意思了。
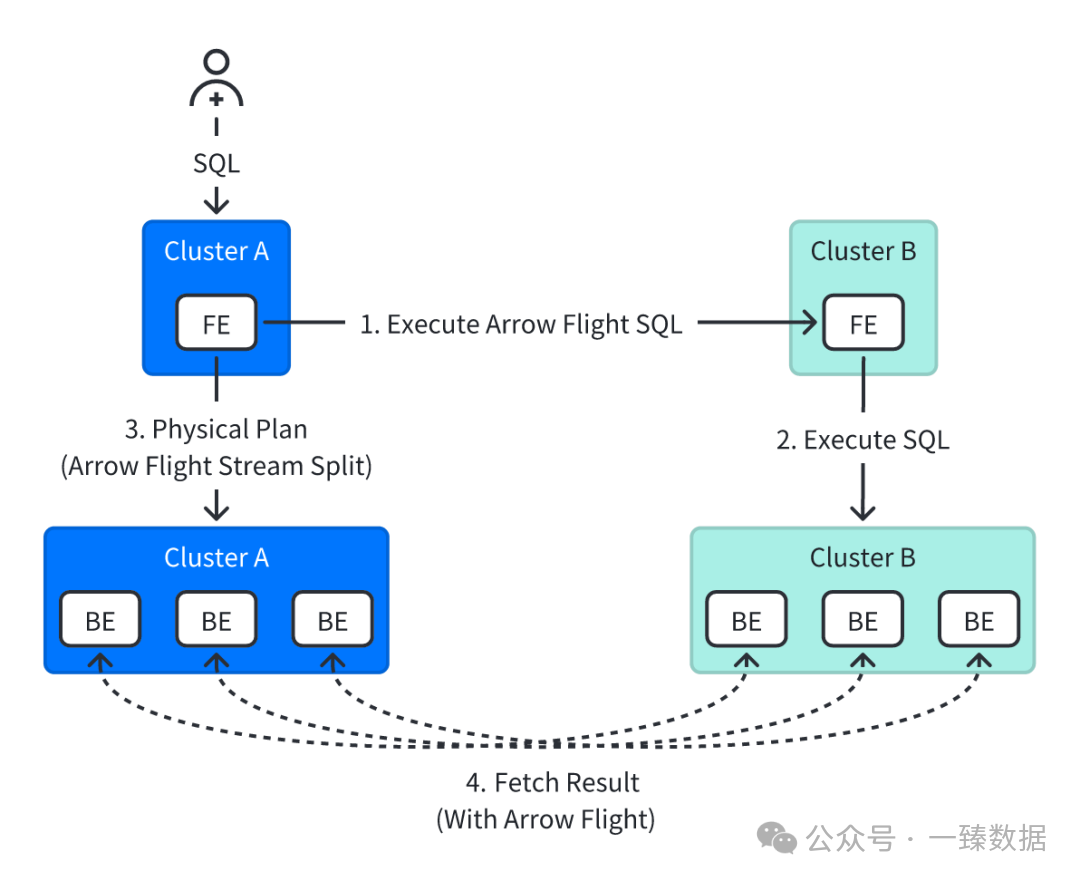
它把远端集群的BE节点当成虚拟BE,直接同步完整的元数据信息,然后生成全局统一的执行计划。
在Doris看来,两个集群的BE节点就是一个大集群,查询计划可以无缝分发执行。
这种设计带来的好处是显而易见的:所有Doris内表的优化策略都能用上,Runtime Filter、分区裁剪、列裁剪这些优化手段全部生效。
对于那种需要复杂Join和聚合的分析场景,虚拟集群模式是不二之选。
回到文章开头老张的故事,他用的就是虚拟集群模式。
配置Doris Catalog只需要一条SQL,指定远端FE的HTTP地址、Thrift地址、用户名密码,设置use_arrow_flight为false,就搞定了。
然后在查询时,用全限定名直接关联本地表和远端表,一条SQL解决战斗:
-- 创建Doris Catalog,启用虚拟集群模式(复用内表优化)
CREATECATALOGIFNOTEXISTS remote_ctl PROPERTIES (
'type' = 'doris', -- 固定类型
'fe_http_hosts' = 'http://logistics-fe1:8030,http://logistics-fe2:8030', -- 远端FE HTTP地址
'fe_arrow_hosts' = 'logistics-fe1:8040,http://logistics-fe2:8040', -- 远端FE Arrow Flight地址
'fe_thrift_hosts' = 'logistics-fe1:9020,http://logistics-fe2:9020', -- 远端FE Thrift地址
'use_arrow_flight' = 'false', -- false=虚拟集群模式,true=Arrow Flight模式
'user' = 'doris_admin', -- 远端集群登录用户
'password' = 'Doris@123456', -- 远端集群登录密码
'compatible' = 'false', -- 集群版本接近(4.0.3 vs 4.0.2),无需兼容
'query_timeout_sec' = '30'-- 延长查询超时时间(默认15秒)
);
-- 查询
SELECT
local.region,
SUM(remote.sales_amount) as total_sales
FROM internal.sales_db.orders local
JOIN remote_ctl.logistics_db.delivery remote
ON local.order_id = remote.order_id
WHERE local.create_date >= '2025-01-01'
GROUPBY local.region;
这种写法和在单集群查询没什么区别,唯一的差别是多了个Catalog前缀。
但对于查询引擎来说,这背后的优化逻辑完全不同——它会智能地把计算下推到远端集群,减少数据传输量,最大化利用两边的计算资源。
有个做电商的小伙伴用Doris Catalog解决了订单履约率分析的问题。他们的订单数据在交易集群,履约数据在物流集群,以前用JDBC Catalog跑一次查询要好几分钟。换成Doris Catalog虚拟集群模式后,查询时间直接降到秒级,业务人员终于不用盯着进度条发呆了。
面对两种模式,很多人会纠结该用哪个:

其实选择逻辑很简单。
如果你的查询主要是简单的单表过滤、投影操作,或者需要跨集群做UNION,那Arrow Flight模式就够用了。它轻量、高效,不需要同步完整元数据,对FE内存压力小。
但如果你的分析涉及复杂的Join、聚合操作,或者需要依赖Doris的各种查询优化特性,那毫不犹豫选虚拟集群模式。虽然它会同步元数据,对FE内存有一定要求,但换来的性能提升是实打实的。
还有一个考虑因素是集群版本。如果你的多个Doris集群版本不一致,用Arrow Flight模式更稳妥,兼容性更好。
结语
Doris Catalog目前还是实验性特性,官方明确表示会持续优化。
说到底,Doris Catalog的出现,让湖仓一体这个概念更加完整了。
以前Doris可以无缝对接各种外部数据湖,现在连自己的多个集群也能高效互联,真正做到了无界。
数据在哪里不重要,重要的是你能不能高效地查询和分析它。
这种对内对外都不妥协的态度,才是一个成熟数据库应有的样子吧。
来源(公众号):一臻数据




