大语言模型为何说谎?幻觉问题探析
大型语言模型(LLMs)已展现出令人惊叹的能力,但其在医疗、金融和法律等高风险领域的广泛应用仍受制于一个关键缺陷:幻觉现象。即模型倾向于生成听起来合理且自信、但事实错误的陈述。我们都曾见过此类现象——LLM 引用不存在的法律案例,或言之凿凿地编造历史事件。
但为何会出现这种情况?最新研究表明,幻觉并非随机错误,而是模型训练方式可预测的统计结果。当前微调LLM的标准方法,特别是基于人类反馈的强化学习(RLHF),通常采用简单的二元奖励机制:回答要么正确(+1分),要么错误(-1分)。
在此范式下,以最大化预期得分为目标的模型,只要其内部正确概率大于零,就会被激励进行猜测。而选择弃权或承认不确定性则会受到惩罚。这会将模型训练成“应试高手”——始终为最大化得分而提供确定性答案,而非成为承认认知边界的“诚实交流者”。训练目标与认知诚实之间的根本性错位,是幻觉现象持续存在的根源。
培养诚实性:行为校准的新方法
要构建真正可信的ç,我们需要将范式从单纯奖励正确性转向奖励诚实性。本文引入名为行为校准的框架来实现这一目标。其核心思想简洁而有力:一个可信的模型应能根据用户的风险承受能力,动态调整其回答意愿。
试想您可以告知模型:“仅当正确把握超过95%时才作答。”行为校准后的模型应能理解该指令,在其置信度低于该阈值时保持沉默。这一概念通过风险阈值(记为 )进行形式化。理想模型仅当其内部置信度 大于指定风险阈值 时,才提供实质性答案;否则应通过输出特殊标记(如 <IDK> 表示“我不知道”)来弃权。
此方法不仅防止错误答案,更使模型外部行为与其内部知识状态保持一致。通过训练模型做到要么自信正确地回答、要么弃权,我们可以教会它们“知所不知”这一宝贵能力。
运作原理:基于校准奖励的强化学习
实现行为校准的关键在于重新设计强化学习中的奖励函数。本文系统探讨了三种策略,以超越简单二元奖励并激励诚实的置信度报告。
显式风险阈值设定
直接方法是在训练时向模型告知风险阈值 。模型接收评分规则提示,并根据其行动获得奖励。奖励函数定义为:
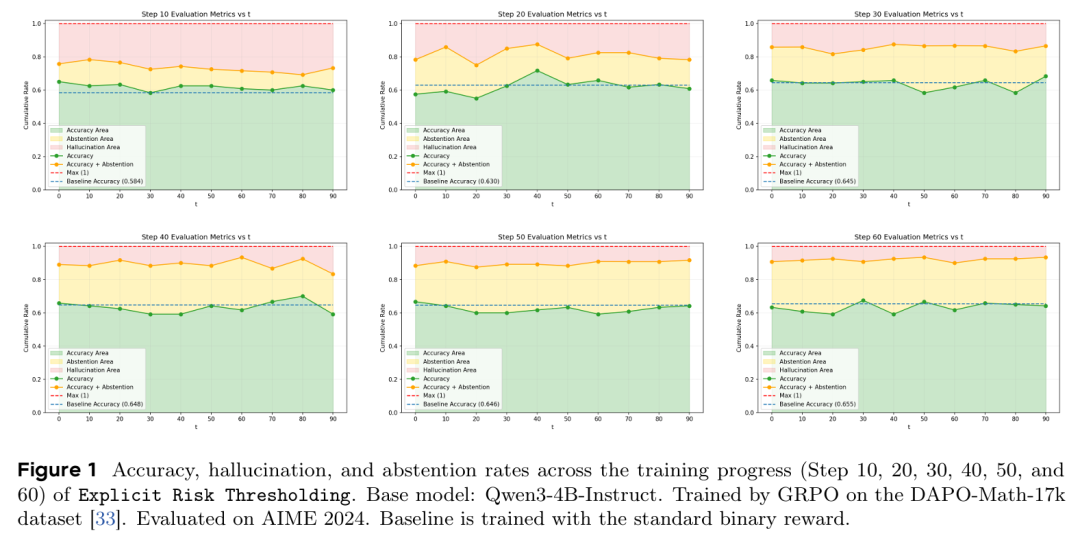
此处,ANS 表示作答,ABS 表示弃权,valid(y) 检查回答是否正确。尽管理论合理,实验显示此方法不稳定。如 Figure 1 所示,模型难以学习适应不同 值的连贯策略,常变得过度保守。
语言化置信度
更有效的策略是让模型通过输出标量分数 及其答案来“语言化”其置信度。训练目标随后通过对可能风险阈值的先验分布积分来转换。这一优雅的数学步骤将训练目标转化为优化严格适当评分规则,激励模型报告真实反映其实际正确概率的置信度 ,即 。
基于此原理推导出两种奖励函数:
均匀先验(类Brier奖励): 假设所有风险阈值等可能,得到类似Brier分数的奖励函数:。这直观地同时奖励正确性( 项)和校准性(通过最小化平方误差 )。
Beta先验(类交叉熵奖励): 使用强调风险谱极端值( 和 )的Beta分布,产生类似交叉熵的奖励函数,对错误答案的过度自信施加重罚。
评论家价值函数
第三种策略巧妙利用了PPO等行动者-评论家RL算法中的现有组件。评论家网络经训练以估计预期未来奖励。由于主要奖励基于正确性,评论家的价值函数自然学会预测成功概率。本文证明,评论家的最终标记价值可直接用作校准置信度分数,无需模型生成显式置信度标记。此方法被证明是非常强大且高效的基线。
理论付诸实践:复杂数学问题上的实证
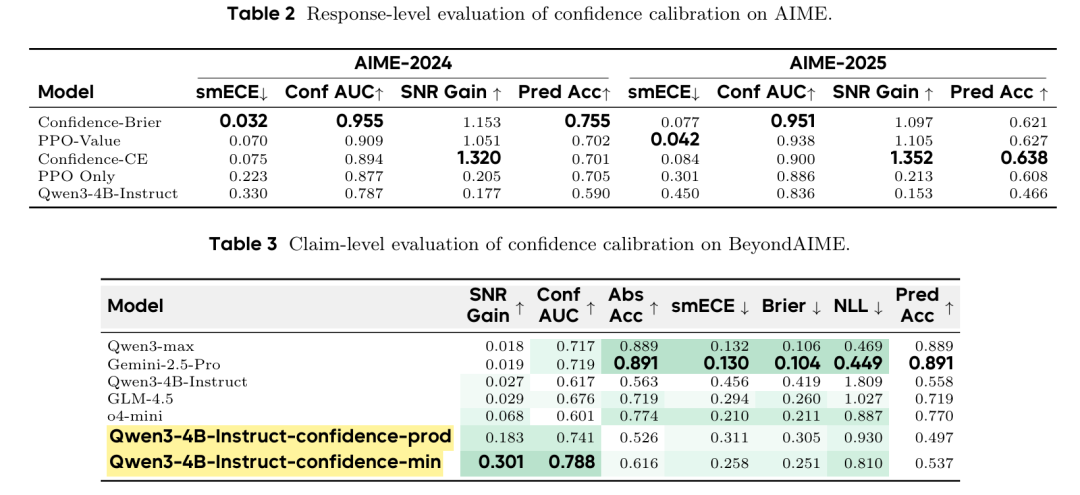
为测试这些方法,研究人员使用 BeyondAIME 基准数据集——包含100道抗简单记忆的“超难”数学问题。实验在相对较小的 Qwen3-4B-Instruct 模型上运行。Table 1 所示结果引人注目。
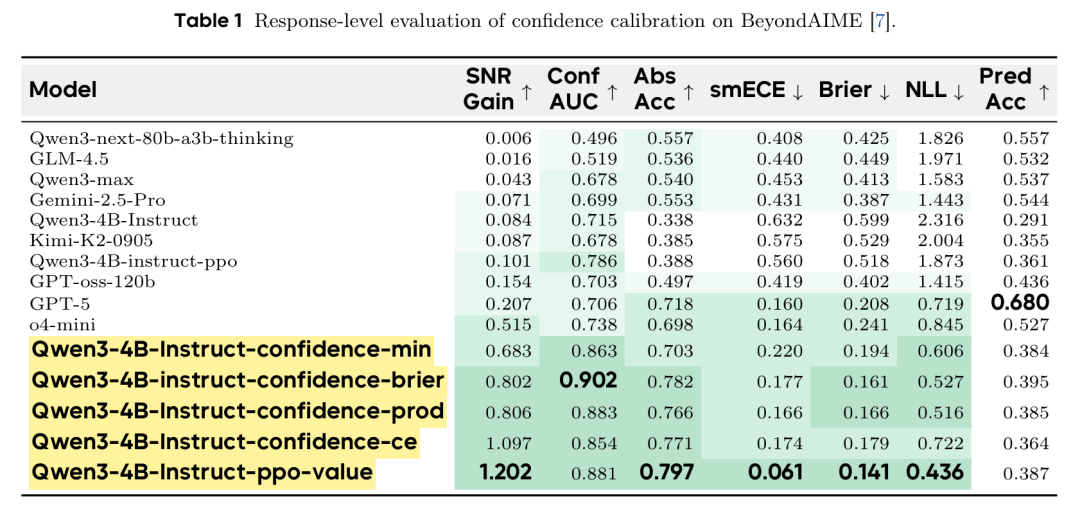
经校准奖励训练的模型在所有校准指标上均显著优于基线模型乃至更大规模的前沿模型。关键指标信噪比增益衡量模型随风险容忍度增加而降低幻觉率的能力。
在数学推理任务上训练后,本文的4B模型在准确率-幻觉比上的对数尺度增益(0.806)超过了GPT-5(0.207)。
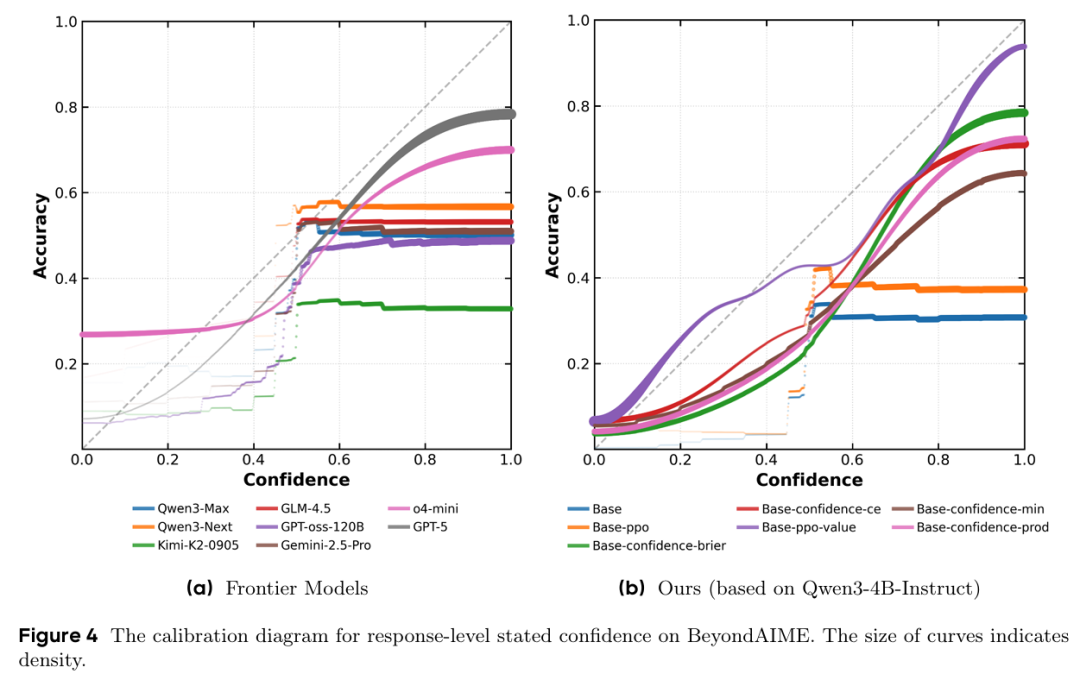
此外,Figure 4 中的校准图显示,校准模型的陈述置信度与实际准确率之间存在清晰、单调的关系。相反,大多数前沿模型的准确率与其陈述置信度几乎无关联,表明校准性差。这证明通过恰当训练,即使较小模型也能学会准确报告其置信度。
可迁移技能:跨领域校准的泛化能力
诚实性是仅能针对特定任务学习的技能,还是可泛化的“元技能”?为解答此问题,研究人员进行了零样本跨领域评估。仅在数学领域训练的模型在 SimpleQA(一个长尾事实问答基准)上接受测试。
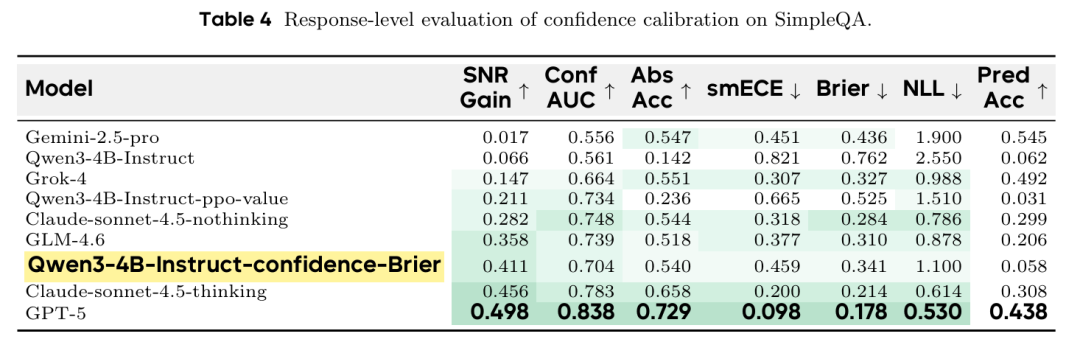
Table 4 呈现的结果令人瞩目。尽管在新领域的事实准确率很低(对于小型专用模型属预期之内),其校准性能却异常出色。Qwen3-4B-Instruct-confidence-brier 模型的校准错误率(smECE、Brier 分数)与Grok-4、Gemini-2.5-Pro等巨型前沿模型相当甚至更优。
这一发现意义深远。它证明校准是一种可学习的“元技能”,可与原始预测准确率解耦,并能跨领域泛化。 我们可以教会模型在某一领域如何保持诚实,而面对完全不同领域的问题时,它仍能保持这种认知谦逊。本文还成功将该框架扩展至声明级校准,如 Table 3 所示,允许模型在较长思维链中标记个别不确定步骤。
校准的未来:构建可信AI
本研究为缓解现代AI最重大风险之一提供了清晰实用的路径。它挑战了“模型越大越好”的单一思路,表明针对诚实性的定向训练能产生非凡效果。
核心结论明确:
诚实性是可教技能: 幻觉并非必然。通过使用基于适当评分规则的校准奖励进行强化学习,我们可以训练模型诚实面对不确定性。
小模型可更诚实: 经过恰当校准的40亿参数小模型,对自身局限性的认知能力可远超参数规模数百倍的前沿模型。
校准是可泛化元技能: “知所不知”的能力可跨领域迁移,为即使在核心训练数据外操作仍更安全可靠的模型铺平道路。
通过将焦点从培养“应试高手”转向塑造“诚实交流者”,我们有望培育出不仅强大且值得信赖的新一代LLM。AI的未来不仅关乎获得正确答案,更关乎知晓何时无法做到并勇于承认的诚信。
来源(公众号):AI Signal 前瞻