

研究意义
阅读ChatGPT生成的摘要时,你或许会注意到一个奇特现象:模型尤其偏爱“delve”(探究)、“intricate”(复杂)、“nuanced”(微妙)这类光鲜的学术形容词。越来越多文献将这种词汇过度使用视为大语言模型(LLMs)与人类写作者差异的体现。但究竟是什么驱动了这些词汇选择?

Juzek与Ward的研究试图解答这一问题。他们的研究探讨了人类反馈学习(LHF)环节——即人类对模型输出进行排序或比较的过程——是否会系统性推动LLMs偏向使用一小部分受青睐的术语。若确实如此,这种过度使用就并非神秘的程序错误,而是为了让模型更符合人类偏好而设计的流程所产生的副作用。
通俗解读核心发现
研究者对比了LHF训练前与LHF训练后的模型,识别出指令微调后使用频率显著上升的词汇,随后通过人类实验让参与者在两版仅含目标词汇差异的文本中做出选择。结果发现:经LHF训练的模型(Meta的Llama 3.2 Instruct)确实比基础模型更频繁使用某些词汇,而人类偏好那些包含更多此类词汇的版本(≈52% vs. 48%)。简言之:LHF似乎是词汇过度使用的主要推手,而它偏好的词汇恰恰也是反馈环节中人类更青睐的。
方法论逐步解析
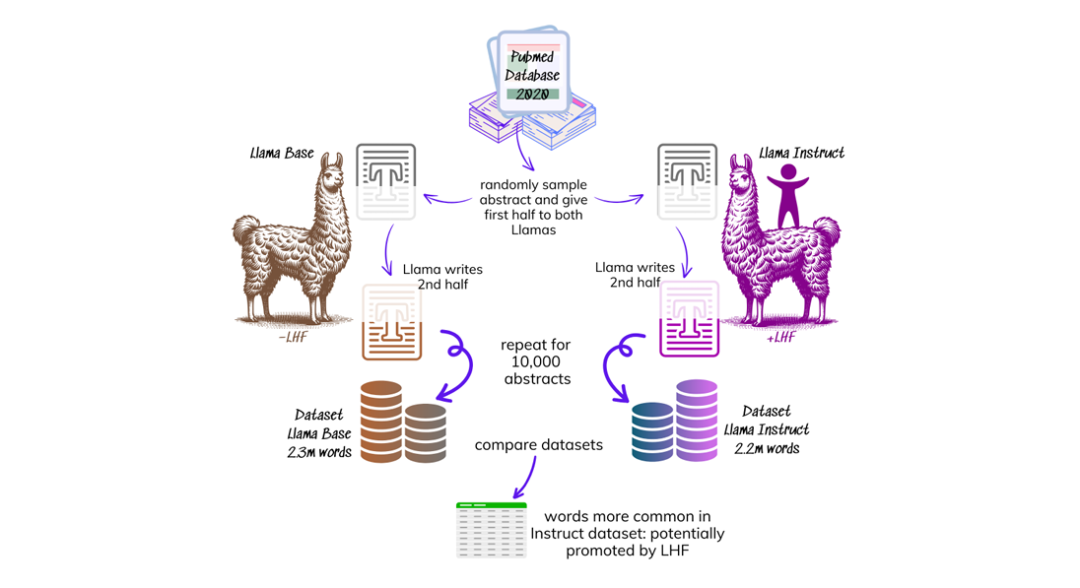
3.1 模型选择
基础模型:Llama 3.2‑3B Base——未经人类反馈微调的标准语言模型。
指令微调模型:Llama 3.2‑3B Instruct——相同架构,但经过直接偏好优化(DPO)(一种通过最大化人类偏好分数实现LHF的技术)。
这对模型是唯一公开的、仅因LHF步骤产生差异的配对,适合进行纯净对比。
3.2 构建“词汇指纹”
数据源:从PubMed(2020年)选取10,000篇科学摘要(确保其成文于LLMs普及前,代表人类基准)。
过滤:剔除少于40词的摘要,保留9,853篇。
生成续写:将每篇摘要分为两半,以前半段为提示输入模型:
续写以下学术文章:'{前半段}'
模型生成续写内容(长度不超过输入的两倍)。
清洗:使用GPT‑4o自动去除生成循环、元评论及非摘要内容的杂项文本。
生成语料库:
基础模型续写:约230万词
指令模型续写:约220万词
3.3 标注与计数
词性标注:通过 spaCy (v3.8.3) 标记每个词汇(如名词、动词),区分同形异义词(如“run”作动词或名词)。
词元归并:将词汇还原为词典形式(如“delve”“delves”“delving”→“delve”)。
频率计算:对每个词元-词性组合计算每百万词出现次数(opm)。
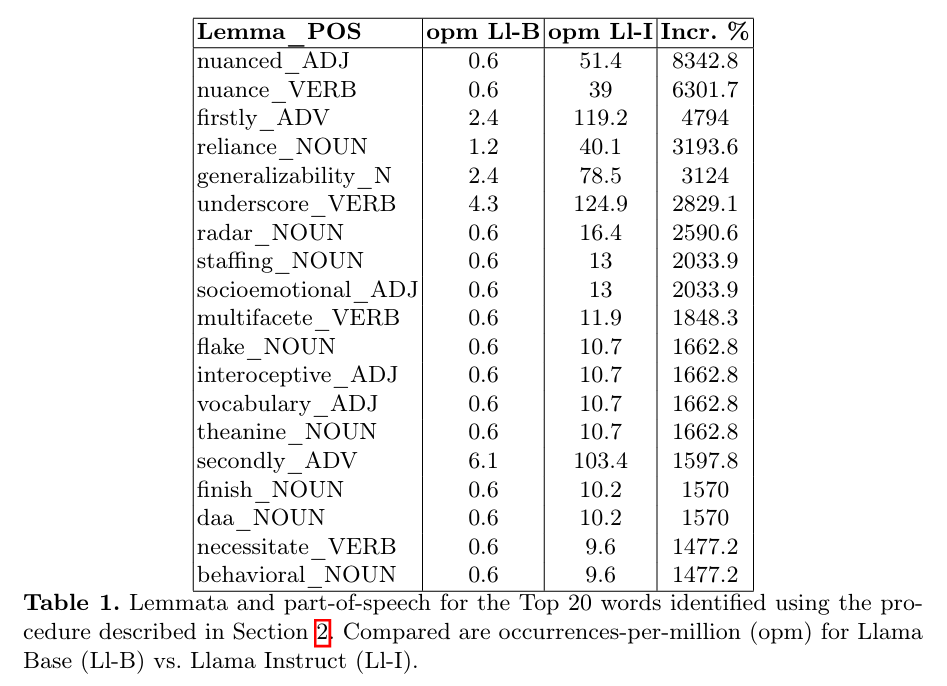
3.4 统计检测过度使用词汇
卡方检验比较两语料库的词汇计数。
显著性上升(p < 0.01)的词汇被标记为潜在LHF诱导项。
3.5 从检测到实验验证
目标:证明人类在文本排序时偏好的词汇与LHF过程一致。
生成变体:将50篇随机PubMed摘要转化为关键词列表,输入Llama Instruct生成每篇500个变体(共25,000个)。清洗后保留8,710个有效变体。
评分:为每个目标词汇分配LHF分数(基于其在指令模型中的相对增幅),变体总分为所含词汇分数之和。
筛选对比组:对每篇摘要,选取LHF分数最低与最高的变体,最终保留差异最大的30组作为实验刺激集。
人类受试者:通过Prolific招募400名参与者(主要来自全球南方),每人评估25组(20组关键对比,5组控制组)。剔除低质量数据后保留4,039条有效评分(≈每组135次评分)。
统计分析:主检验为卡方检验(对比高/低LHF分数选择比例与50/50基准),辅以混合效应逻辑回归验证稳健性。

结果解读
实验揭示三大发现:
总体偏好:52.4%的案例中参与者选择高LHF分数变体,虽微弱但显著高于随机水平。
混合效应模型:逻辑回归(含受试者与项目的随机截距)确认固定效应显著,表明偏好模式跨文本与人群均成立。
词汇特异性:当高分数变体含“nuanced”时,偏好率反降至46.6%,暗示某些过度使用词汇若过于显眼可能适得其反。
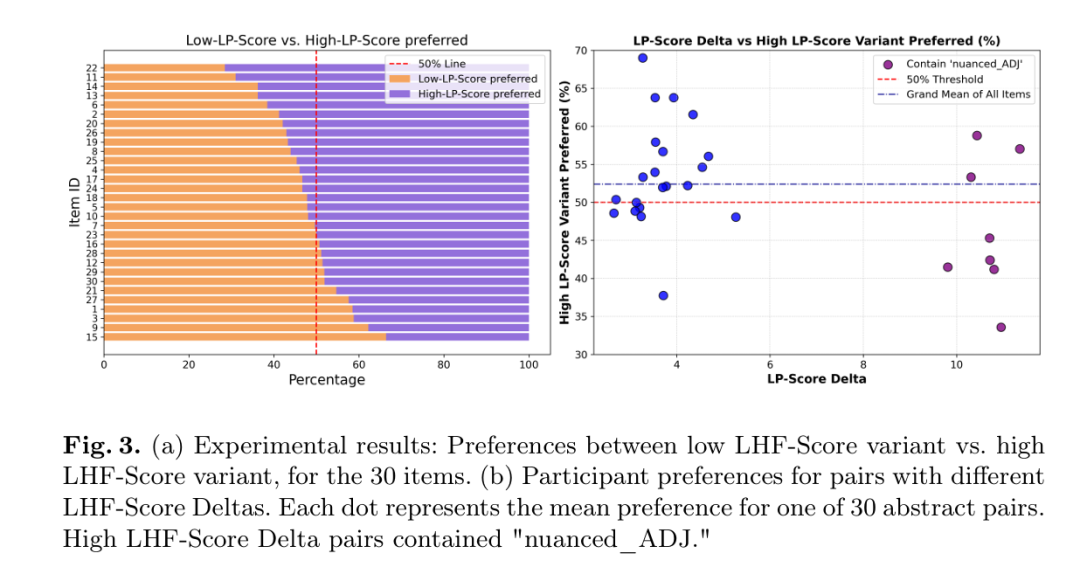
核心结论:LHF评估者确实偏爱那些被后LHF模型过度生成的词汇,由此形成因果链:人类评估者→LHF微调→模型偏差。
影响与更广语境
对齐与错位:LHF旨在使模型对齐人类偏好,但实际对齐的是LHF劳动力(多为全球南方年轻群体)的偏好,可能与终端用户(学者、记者)反对的“delve效应”冲突。
语言演变:某些术语的过度使用早于LLMs,LHF可能加速代际语言变迁,使模型模仿反馈提供者的语言习惯。
数据透明度:不透明的LHF流程(未公开数据集、隐藏工作者人口统计)阻碍诊断与修正偏差。公开LHF数据可实现针对性去偏。
缓解措施:研究者的检测流程(第2部分)为开发者提供低成本自动化工具,可在模型发布前识别极端词汇过度使用。结合劳动力多样化或偏好数据再平衡,或减少“AI词汇”泛滥。
AI文本检测:过度使用词汇是LLM输出的标志,此方法可改进AI文本检测工具(如基于相对熵或概率曲率的工具)。
核心启示
人类反馈学习是一把双刃剑。它推动LLMs使用评估者(多为全球南方年轻工作者)偏好的语言,却导致模型过度使用少量华丽的学术词汇——许多读者视此现象为与更广泛用户期待的错位。
Juzek与Ward的研究首次实证连接LHF与词汇偏差,既提供诊断工具,也呼吁反馈环节的更高透明度。若要LLMs服务真正多元的受众,我们必须超越当前LHF劳动力,多样化其生成的数据,并警惕模型重复的词汇。
来源(公众号):AI Signal 前瞻




