

在人工智能日新月异的发展浪潮中,构建更强大的语言模型往往伴随着高昂代价——计算与内存需求呈指数级增长。
谷歌DeepMind、KAIST AI和Mila的研究人员在其2025年发表的论文《Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation》中提出的混合递归框架(MoR),正是这一困局的破局者。

这一开创性架构能够在保持大规模语言模型性能的同时,大幅降低资源消耗,或将重新定义高效AI的未来图景。让我们深入解析MoR的革命性突破,探寻其被誉为"游戏规则改变者"的深层原因。
核心挑战:如何实现高效扩展
像GPT-3和PaLM这样的大型语言模型(LLMs)已展现出惊人能力——从诗歌创作到复杂问题求解无所不能。然而,它们的算力需求同样惊人。训练和部署这些模型需要消耗海量资源,导致其几乎成为资金雄厚的科技巨头专属品。
以往提升效率的努力通常聚焦于两种策略:参数共享(通过复用模型权重缩减规模)或自适应计算(根据输入动态分配算力资源)。但问题在于——这两种方法长期未能有效结合,直到 MoR 的出现。
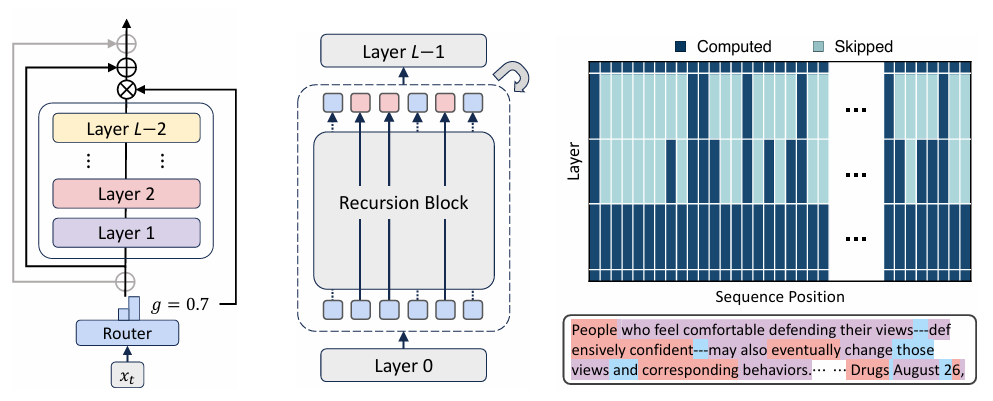
MoR 通过将参数共享与自适应计算统一纳入递归 Transformer 框架,直击这一难题。最终实现的模型既能达到大模型的性能水准,又只需小模型的资源开销,为AI效率树立了全新的帕累托前沿。
什么是混合递归架构(MoR)
MoR(混合递归)架构的核心是通过两种关键方式提升基于Transformer的语言模型效率:
递归式参数共享机制:不同于传统模型为每层计算分配独立参数,MoR采用共享的Transformer层堆叠结构进行多步递归计算。这种设计大幅减少唯一参数数量,使模型在训练和部署时更紧凑高效。
自适应token计算策略:模型通过轻量级路由网络动态分配不同递归深度——对复杂token进行深层计算,而简单token则提前退出。这种细粒度资源分配有效避免了冗余运算。
该架构还创新性地采用了动态KV缓存技术:仅选择性存储当前递归步骤活跃令牌的键值对,显著降低内存占用并提升推理速度。其变体递归KV共享更进一步复用首步递归的键值对,在几乎不影响性能的前提下,大幅减少预填充延迟和内存消耗。
MoR 如何运作
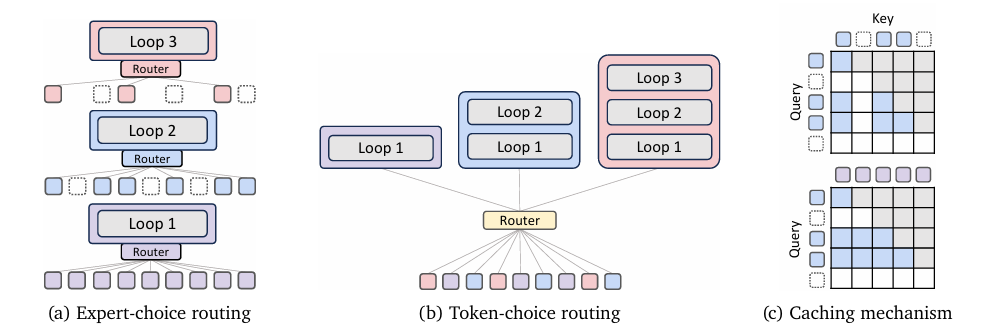
想象一个编辑团队正在润色一份复杂文档。在传统 Transformer 架构中,每个编辑(层)都是独立的,需要消耗大量资源。而 MoR 则如同一位技艺高超的编辑,通过多次迭代审阅来优化文档。以下是MoR的核心组件解析:
递归式Transformer架构
MoR将模型划分为递归块,通过重复应用同一组共享层实现优化。其参数共享策略包含三种模式:
循环模式:层参数按周期循环复用
序列模式:连续重复使用相同层
中间变体:保留首尾层的独立参数,共享中间层参数
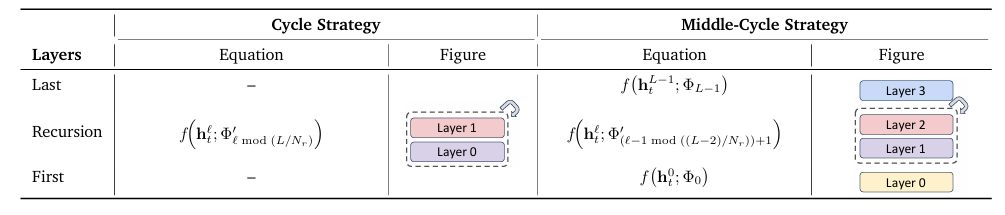
这种设计减少了独特参数数量,既提升了训练效率,又通过"连续深度批处理"等技术消除了计算"气泡"。
动态递归路由
全新训练的路由模块会根据token的复杂度分配递归深度:复杂token获得更多计算资源,简单token则提前退出。与事后路由方案不同,MoR的路由机制在预训练阶段就深度集成,确保训练与推理行为的一致性,实现最优性能。
高效KV缓存
MoR采用"递归感知KV缓存"技术,仅存储当前递归步活跃token的键值对,大幅减少内存访问。其"递归KV共享"变体通过复用首轮递归的键值对,可降低50%内存占用,某些场景下推理速度提升达2倍。
MoR为何重要:结果说明一切
MoR框架在1.35亿至17亿参数的模型规模范围内进行了严格测试,结果令人瞩目:
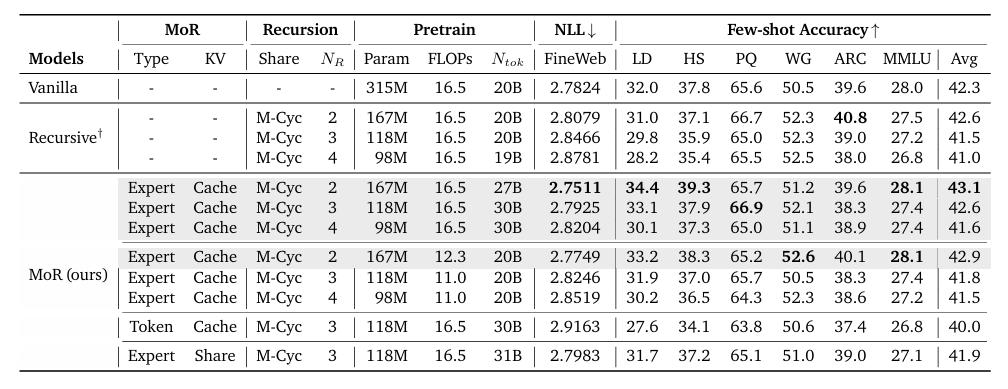
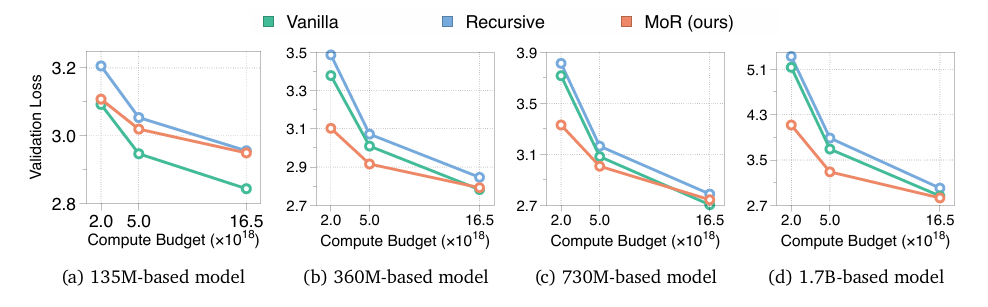
性能优势:在同等训练计算量(FLOPs)条件下,相较于传统Transformer和现有递归基线模型,MoR以更小的模型规模显著降低了验证困惑度,并提升了少样本学习准确率。
吞吐量提升:通过聚焦活跃令牌的计算优化及KV缓存机制,MoR实现了更高的推理吞吐量,使部署速度更快、成本效益更优。
内存高效:该框架将KV缓存内存占用减少约50%,直击大语言模型部署中最关键的瓶颈之一。
扩展性强:MoR的设计兼容现有硬件和架构,成为现实场景应用的实用解决方案。
这些突破性进展确立了MoR作为效率新标杆的地位,以"大模型性能、小模型成本"实现了优质低耗的完美平衡。
迈向更智能、更廉价AI的关键一步
MoR 的意义不仅限于技术效率的提升。通过降低部署大语言模型的计算与资金门槛,这项技术使小型机构和研究者也能用上尖端AI模型,推动了先进人工智能的民主化进程。其自适应计算机制更模拟了某种"计算智能"——像人类分配脑力处理复杂任务那样,动态调配计算资源到最需要的地方。
X平台上的技术爱好者甚至将MoR称为"Transformer杀手",暗示它可能引发传统Transformer架构的范式转移。虽然这种说法略显夸张,但MoR通过参数共享与自适应计算的创新结合,确实为高效AI设计树立了新标杆。
挑战与未来方向
尽管混合递归(MoR)是一项重大突破,但它仍面临挑战。动态路由机制需要精细训练以避免性能下降,而递归KV共享的权衡方案仍需在不同任务中进一步探索。此外,与所有注重效率的方法一样,需要确保该技术在现实应用中始终保持稳健性能。
未来研究可在MoR基础上整合其他技术,如专家混合(MoE)或DeepMind自研的混合深度(MoD)。该框架的灵活性还为动态样本调度和连续深度批处理等创新开辟了道路,有望进一步提升吞吐量(某些情况下可实现高达2.76倍的加速)。
结论:面向未来的蓝图
混合递归不仅是一项技术创新,更是构建更智能、更经济、更高效AI的蓝图。通过统一参数共享与自适应计算,MoR实现了曾被视作不可能的目标:既能达到大规模模型的性能,又能保持小规模模型的效率。当AI界苦于扩展成本不可持续之际,MoR为平衡性能与实用性提供了可行路径。
随着DeepMind与合作者不断突破AI效率的边界,MoR以其创造性的架构设计证明了创新的力量。无论它是"Transformer杀手"还是变革性的一步,有一点毋庸置疑:混合递归正在为更普惠、更可持续的AI未来铺平道路。
更多细节请参阅arXiv上的原始论文:《Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation》
来源(公众号):AI Signal 前瞻




