

大型语言模型(LLMs)如 OpenAI‑O3、DeepSeek‑R1 和 Qwen 系列,在解决数学问题、回答科学问题甚至进行多步骤推理方面展现出惊人能力。然而这些强大系统中一直隐藏着一个缺陷:它们经常过度思考。即使是像 这样简单的问题,也可能触发冗长曲折的思维链,消耗数千 token 并推高计算成本。

一项题为《DRQA: Dynamic Reasoning Quota Allocation for Controlling Overthinking in Reasoning Large Language Models》的最新研究揭示了一个惊人现象:当多个问题以批处理形式输入时,模型会自动压缩推理过程,生成比单独处理时更简短的答案。作者将这种 emergent 的「资源竞争压力」转化为系统性技术——动态推理配额分配(DRQA),使单问题推理也能获得同等效率。
1. 过度思考
作者从三个维度描述了该问题:
过度思考导致冗长且通常冗余的思维链及不必要的 token 消耗
后果包括推理延迟增加、GPU 内存占用扩大、API 成本上升以及实际应用的可扩展性降低
思考不足(另一极端)会导致解释过于简略、步骤缺失以及在难题上准确率下降,影响模型在挑战性基准测试中的表现
现代 LLMs 擅长思维链(CoT)提示,即模型在给出最终答案前逐步写出推理过程。这种方式能提升复杂任务的准确率,但在简单任务上可能造成浪费。该研究提出:
我们能否鱼与熊掌兼得?
模型能否学会在问题简单时保持简洁,在问题困难时保持严谨——而无需人工设置 token 预算?
2. 批处理推理的启示
2.1 作者的观察
实验:作者比较了三个数学问题被单独回答与批量回答时的 token 消耗量(图 1)

结果:批量回答节省约 45% 的 token(648 vs. 1205),且准确率相当
解读:当多个查询共享同一上下文窗口时,模型会直觉性地为有限推理配额展开竞争并修剪非必要步骤——作者称之为资源竞争压力
2.2 效应扩展性
作者测量了不同批量大小下每个问题的平均 token 消耗量(使用 DeepSeek‑R1 在 DeepScaleR 数据集约 3 万道数学题上测试):
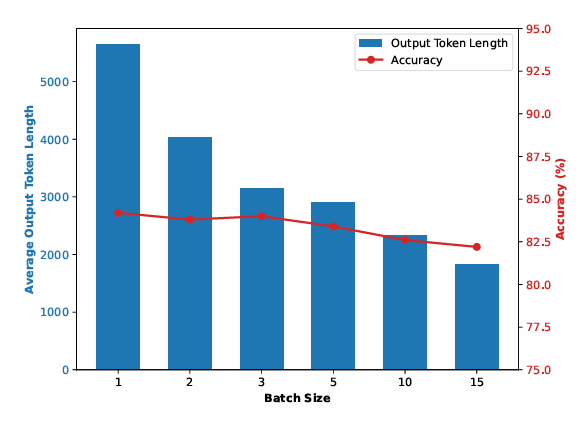
即使批量增大,准确率仅轻微下降,证实模型会自动为难题分配更多推理资源,同时压缩简单问题的推理过程
3. 从观察到方法:DRQA 的实现
该研究的核心贡献是将批处理诱导的效率迁移至单问题推理的强化学习(RL)框架。以下详细解析各组件
3.1 框架概览图
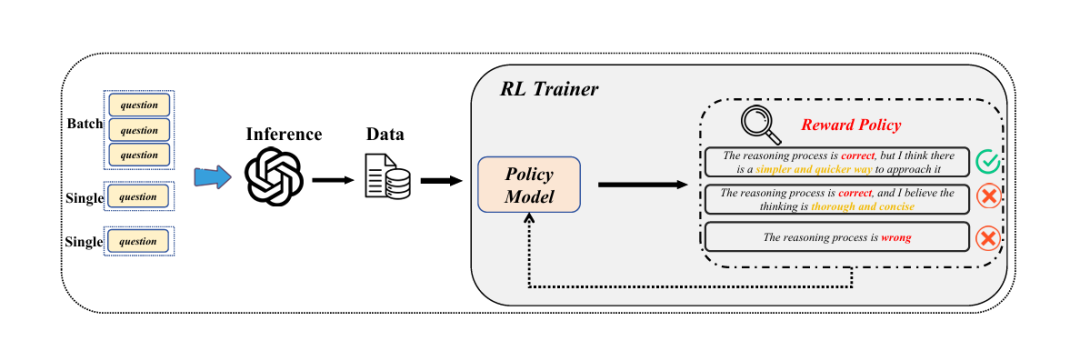
3.2 逐步方法论
3.2.1 通过批处理推理收集数据
使用 DeepSeek‑R1 在 DeepScaleR 数据集(约 3 万道数学题)上运行批量大小为 2/3/5的提示,为每个问题提取对应 CoT
提供模型在资源竞争下自然压缩推理的真实样本
3.2.2 偏好标签构建
每个 CoT 被赋予以下标签之一:
‑ A:正确但可更简洁
‑ B:正确且简洁(理想状态)
‑ C:错误
标注规则:
‑ 原始(单问题)CoT → 标签 A(正确)或 C(错误)
‑ 批量 CoT → 标签 B(正确)或 C(错误)
提供区分「足够好」推理与「不必要的冗长」推理的分级信号
3.2.3 偏好数据集
生成包含 5 万以上 (问题, 推理链, 三选一标签) 元组的数据集
该数据集是 RL 智能体的训练场
3.2.4 基于 GRPO 的强化学习
通过组相对策略优化(GRPO) 训练模型。这种策略梯度方法在最大化正确标签概率的同时,惩罚与旧策略的较大 KL 散度(避免灾难性遗忘)。形式化表示为:
其中 是相对优势(选择标签与真实标签一致时为正,反之为负)
该目标函数显式奖励简洁且正确的推理(标签 B),抑制冗长或错误响应。KL 项用于稳定学习,防止模型「遗忘」解决难题的能力
3.2.5 推理(单问题模式)
测试时,模型接收单个问题并照常生成 CoT。但由于已内化对简洁性的偏好,它会根据难度评估自动分配推理配额
无需额外提示、token 预算或手工规则——模型实时自主决策
3.3 为何监督微调(SFT)不足
SFT:作者首先尝试在批量生成的「简洁」数据上直接进行监督微调
结果:token 数大幅下降(GSM8K 上减少 69%),但准确率显著受损(如 AIME 2024 准确率从 74% 跌至 9%)
原因:模型学会了表面简洁性而未理解何时可简洁,导致灾难性遗忘深度推理能力
因此,需要基于奖励的方法(DRQA)来平衡这两个目标
4. 实验结果
4.1 基准测试与设置
| 数据集 | 领域 | 典型难度 |
|---|---|---|
|
GSM8K |
小学数学 |
简单-中等 |
|
MATH‑500 |
代数、几何、数论 |
中等-困难 |
|
AIME 2024/2025 |
高中奥数 |
困难 |
|
AMC 2023 |
竞赛数学 |
中等 |
|
GPQA‑Diamond |
研究生级科学问答 |
困难 / 分布外(OOD) |
评估的两个蒸馏模型:
DeepSeek‑R1‑Distill‑Qwen‑1.5B
DeepSeek‑R1‑Distill‑Qwen‑7B
所有基线方法(GRPO、O1‑Pruner、DAST、Shorter‑Better 等)均在相同推理配置下复现(温度 0.6,最大长度 32 K)
4.2 主要结果(摘要)
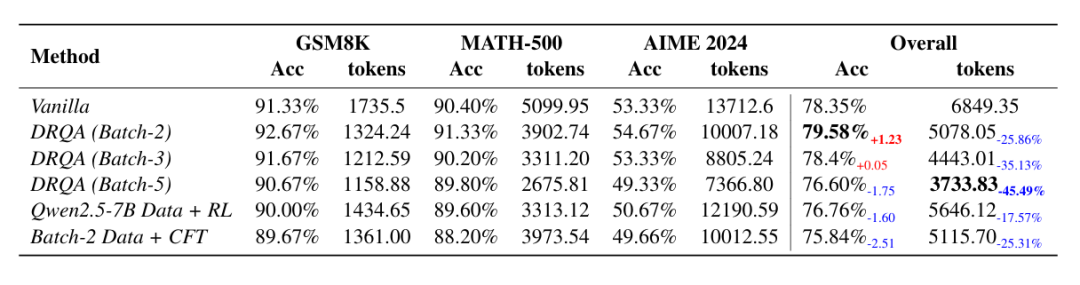
原始模型(无 DRQA)在 GSM8K 上达到 84.67% 准确率,平均每问 1 929 token;在 AIME 2024 上获得 28.67% 准确率,消耗 14 395 token
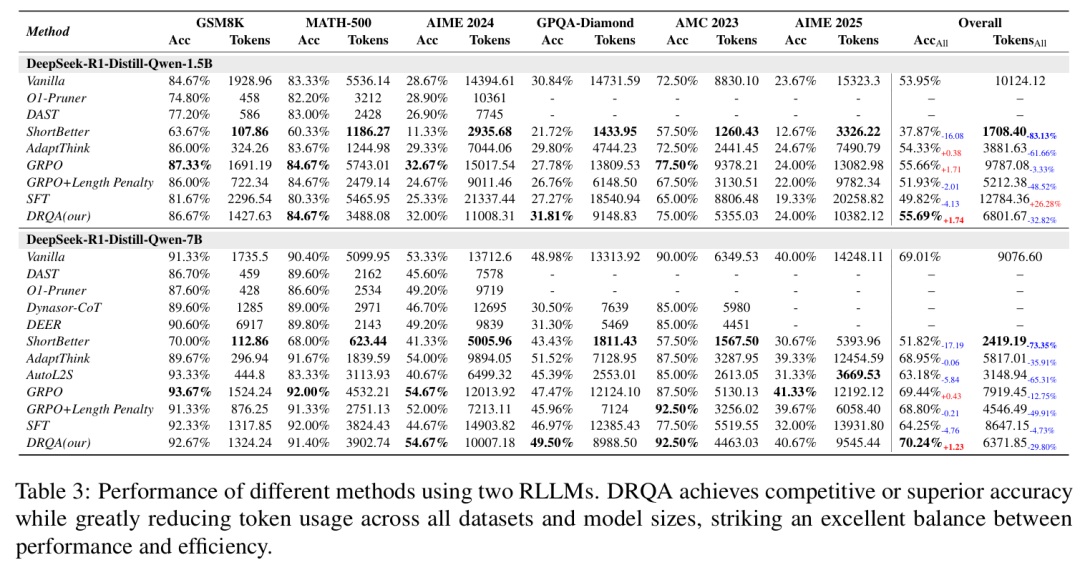
DRQA (1.5 B) 将 GSM8K 准确率提升至 86.67%(+2 个百分点),token 数降至 1 428(约 ‑26%);在 AIME 2024 上准确率升至 32.00%(+3.3 个百分点),token 数减至 11 008(约 ‑23%)
DRQA (7 B) 在 GSM8K 上达到 92.67% 准确率,仅用 1 324 token(‑24%);在 AIME 2024 上获得 54.67% 准确率,消耗 10 008 token(‑27%)
激进压缩方法如 Shorter‑Better 虽大幅减少 token(GSM8K 上 ‑94%),但准确率崩溃(降至 63.67%)
DAST 与 O1‑Pruner 获得中等 token 节省(‑70% 至 ‑76%),但准确率提升有限,均未达到 DRQA 的平衡性
总体而言,DRQA 在各类数学科学基准测试中持续减少约 30% token 用量,同时保持甚至提升准确率
4.3 消融研究(摘要)
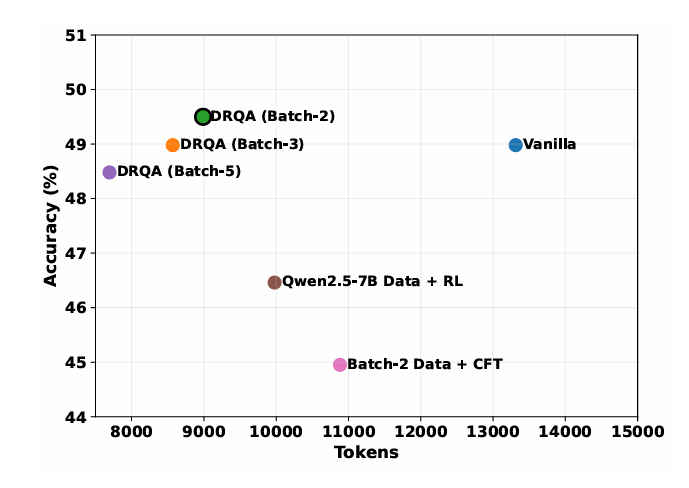
批量-2(使用批量大小 2 训练)获得最佳权衡:token 减少约 30%,整体准确率约 79.6%
批量-3 与 批量-5 的 token 节省略少,准确率微降,表明过大的批量可能稀释「资源竞争」信号
使用非批量数据(如 Qwen2.5‑7B)或批判性微调(CFT) 会导致效率或准确率下降,证实批量生成的偏好数据与 RL 目标均不可或缺
4.4 分布外鲁棒性
在 GPQA‑Diamond 基准上,DRQA 仍减少约 31% token 消耗,同时保持 31.81% / 49.50% 的准确率,优于过度压缩或泛化失败的其他基线
5. 意义
成本节约——对于按 token 收费的服务(如 OpenAI API),DRQA 可在保持质量的前提下降低约三分之一月成本
延迟降低——更短的输出意味着更快的推理,对辅导机器人或科学助手等实时应用至关重要
可扩展部署——凭借更低的内存与计算占用,模型可在相同硬件上处理更多查询
无需人工 token 预算——与许多「早退」或 token 预算方法不同,DRQA 无需额外提示技巧,模型学会自主调节推理长度
6. 局限性与未来方向
| 当前局限 | 潜在改进方案 |
|---|---|
|
仅在数学与科学推理数据集上测试 |
将 DRQA 扩展至代码生成、对话或多模态任务 |
|
方法仍依赖批量生成的偏好数据集,对超大语料库成本较高 |
探索合成生成或自博弈以自举偏好数据 |
|
仅优化token 用量;未直接处理其他效率维度(如 GPU 内存、推理延迟) |
将 DRQA 与动态早退或模型规模剪枝框架结合 |
7. 结论性思考
DRQA 框架巧妙捕捉了 LLMs 在共享上下文窗口时表现出的微妙涌现行为——资源竞争。通过将该现象转化为强化学习信号,作者赋予模型自调节推理配额的能力:问题简单时简短清晰,问题困难时深入严谨。
结果令人印象深刻:在多种数学科学基准测试中实现token 消耗降低 30%,同时保持甚至提升准确率。重要的是,DRQA 无需硬编码 token 限制或额外提示技巧,使其成为任何以推理为核心的 LLM 部署的即插即用式升级方案。
来源(公众号):AI Signal 前瞻




