


API开发功能提供零代码配置式开发方式,使非编程人员也能参与API的开发工作,通过直观的界面进行API的设计,包括URL格式、输入参数、输出参数、转换规则等信息,无需深入了解编程语言和技术细节。
依据相关的国家标准、行业标准和地方标准,建立科学、客观的数据质量评价体系,充分运用大数据相关技术和机器学习相关理论,实现海量信息的异常探查和智能修复,实时监控数据质量波动,以数据质量通报和考核为抓手,建立数据状态可感知、数据问题可追溯、质量责任可落实的数据质量管理和运营体系。
各行业积累了大量的结构化和非结构化数据,如何高效地处理和分析这些数据,进而从中挖掘有价值的信息,是当前面临的重大挑战。建立一个高效、可靠的大数据开发平台,能够为数据分析和应用提供强有力的支撑,是大数据时代的必然选择。面向具体的数据标签、数据指标、可视化报表等应用场景,提供简单易用的数据开发、处理和分析功能,有助于更好的释放数据价值。
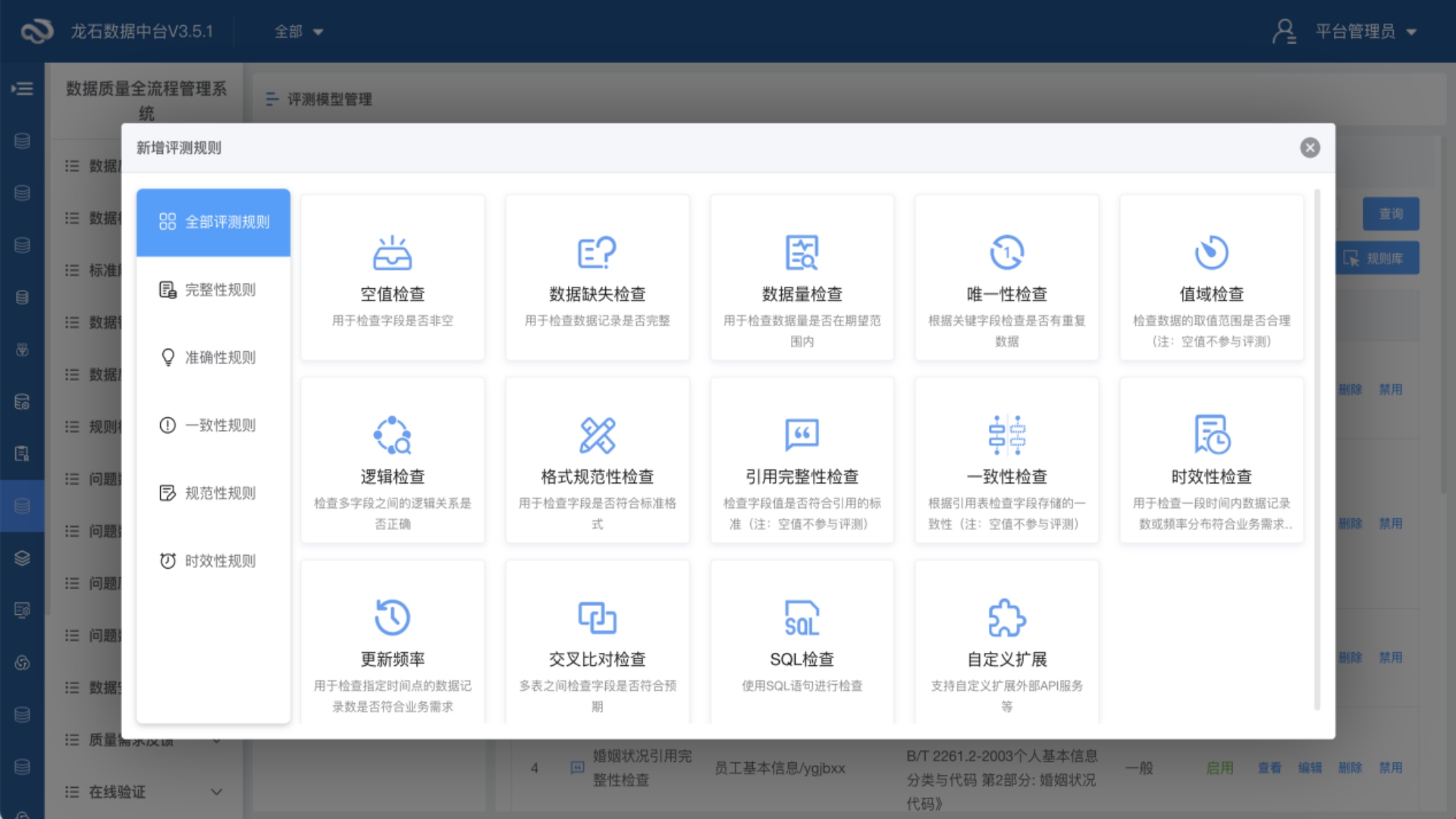
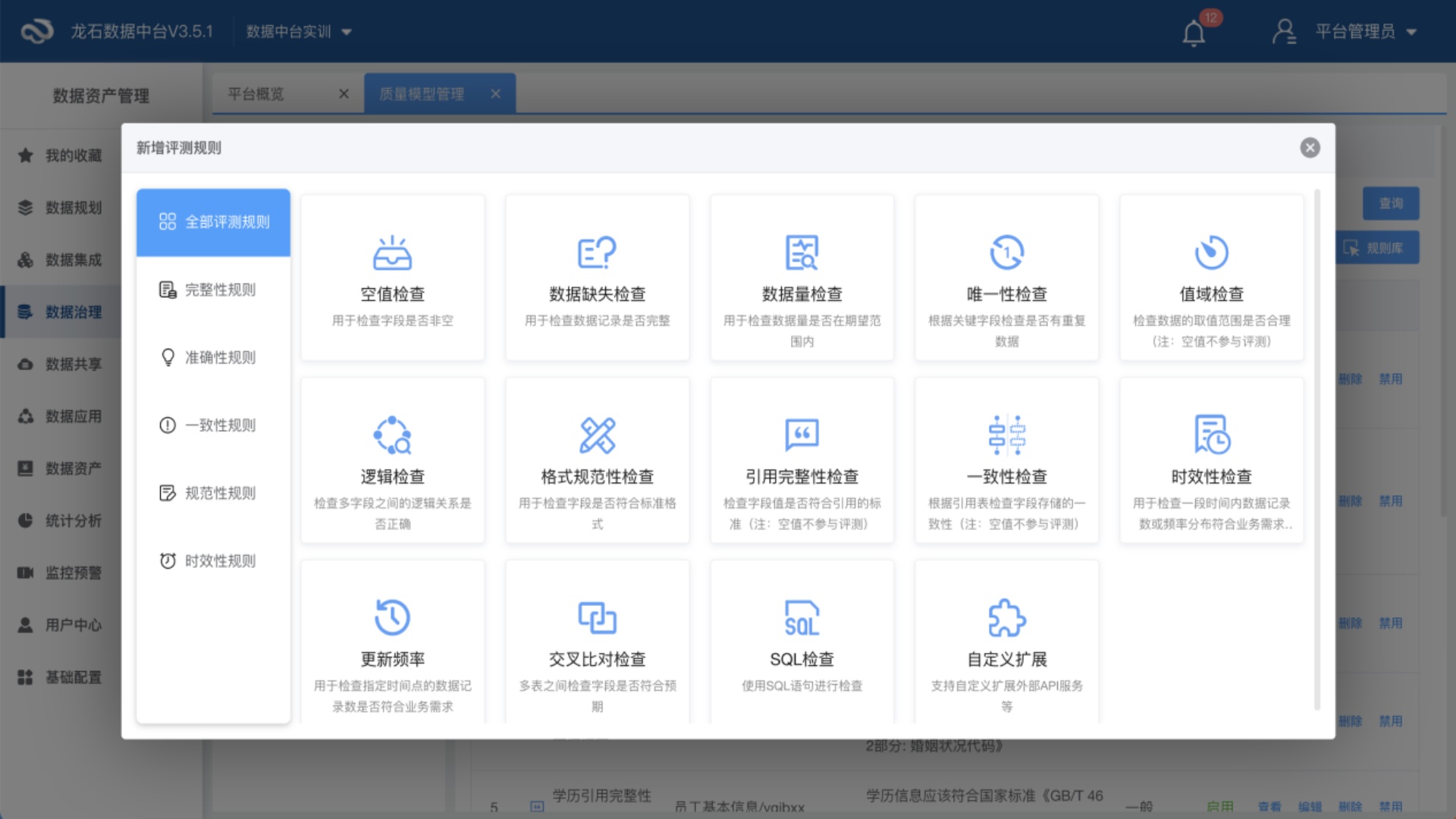
数据质量规则是一组定义和规范,用于指导数据的收集、处理和存储的过程。它要求参与者遵守一定的标准来确保数据的有效性、准确性、完整性和一致性。

数据共享交换平台已逐渐成为推动跨部门、跨组织、跨系统间数据互通与整合的重要工具。一个完善的数据共享交换平台管理体系对于确保平台的高效运行、数据的安全可靠以及资源的充分利用具有重要意义。数据共享交换平台的管理体系包括平台架构、数据安全、资源共享、目录管理、权限控制、监控日志、运维支持以及法规遵从等方面。

API接口管理能力包括API开发、测试、发布、维护、运行到下线的完整周期,以及API安全管理、监控预警、统计分析等综合管理能力。

API平台是以对API进行全生命周期管理为核心,提供全面、精简的API统一管理服务,涵盖无代码API开发、API测试、API编排、外部API接入、内部API共享、版本管理、协议转换、鉴权授权、流量控制、数据加密、黑白名单、集群部署和监控预警等。广泛适用于系统集成、能力整合、连接伙伴和能力变成的应用场景。
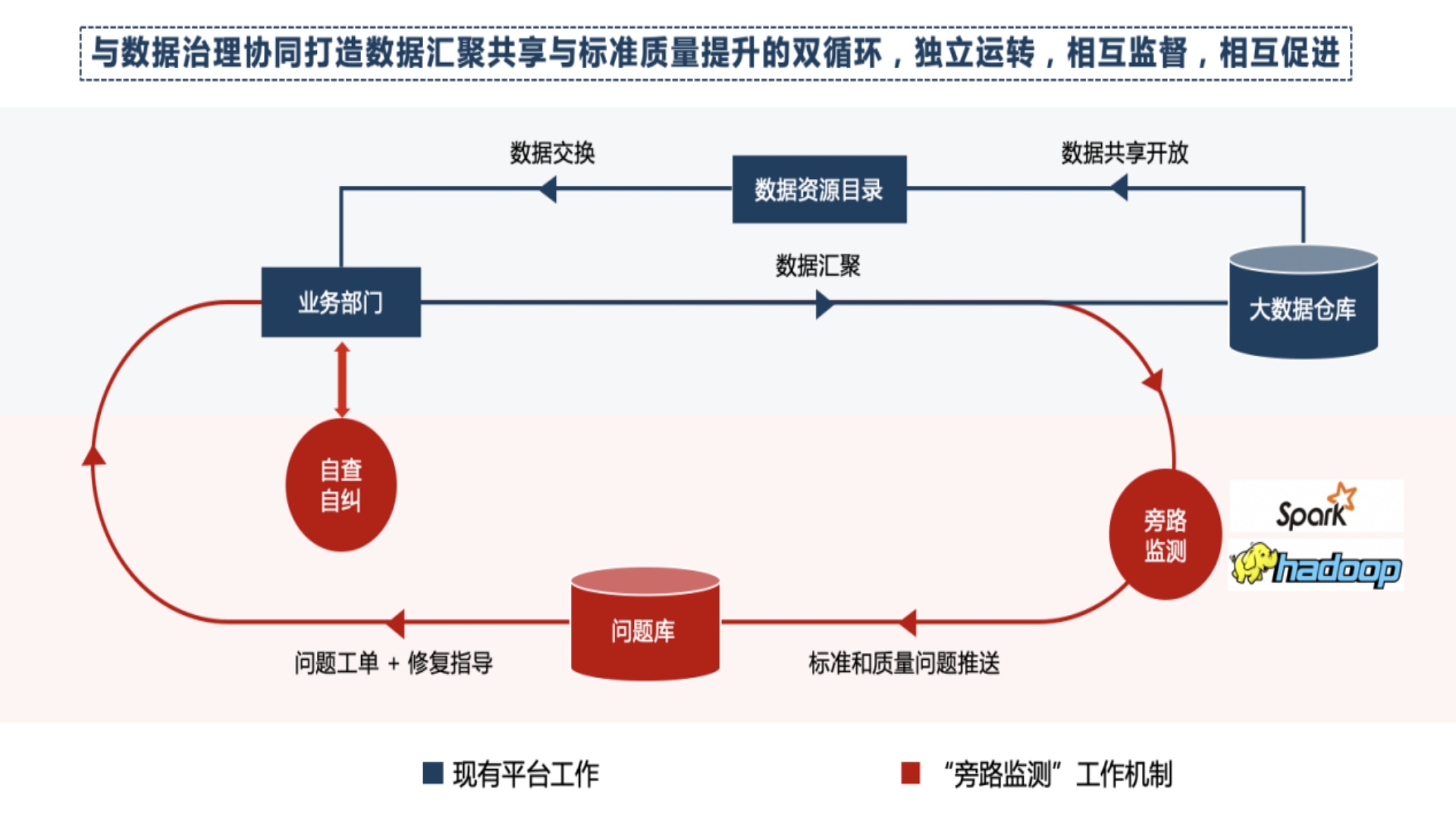
依据国家标准、行业标准、地方标准、团体标准,建立事前、事中、事后的数据质量监测和全面评价指标,建立数据质量考核评价体系,充分运用大数据相关技术和机器学习相关算法,实现海量信息的异常探查和智能修复,实时监控数据质量波动,以数据质量通报和考核为抓手,建立数据状态可感知、数据问题可追溯、质量责任可落实的数据质量管理体系和运营体系,而第三方数据质量管理服务则侧重于监测源头的数据质量,发现源头问题,并推动源头解决问题。

2024年7月4日,《数据资产入表百家讲坛》系列活动第十一期通过线上直播的形式召开。苏州龙石信息科技有限公司(简称龙石数据)数据质量业务总监杨毓慧女士在活动上分享了龙石数据针对数据质量的管理经验。杨总监分享了以一数一源一标准为核心的管理经验,通过摸底、规则的制定、旁路监测、问题分析、工单派发、源头修复和督办考核通过质量的七步法,来提升质量意识。

数据共享交换平台依照安全性、易用性、高可靠性、可扩展性以及整体性原则,助力客户实现数据的互联互通。




