

本文将详细介绍五种重要的数据格式:
•CSV
•JSON
•Parquet
•Avro
•ORC
在大数据时代,数据源之间的数据迁移和存储需要更具策略性的方法。如果没有优化的决策,通过 ETL 流程处理 TB 级数据可能会耗费大量时间和成本。本地部署系统虽然相对容易发现问题,但其基础设施不会自动适应新的情况,问题必须手动解决。
然而,在云端,资源可以自动扩展。虽然我们可能认为一切运行顺畅,但一些被忽略的小步骤却可能导致数万元的不必要成本。在我看来,根据项目需求选择合适的数据格式是大数据时代最关键的决策之一。
存储在 S3 中的物联网数据应该采用 CSV 格式还是 Parquet 格式?每周销售报告文件的最佳格式是什么?大小文件是否应该使用相同的格式?只有充分了解每种数据格式的特性,才能有效地做出这些决策。
近年来,某些格式——尤其是 Parquet 和 Avro——越来越受欢迎。尽管它们存在一些缺点,但它们的灵活性,尤其是在云环境中,极大地促进了它们的应用。在本文中,我将解释这些格式的特性、优势和劣势,并讨论哪种格式最适合特定场景。
一 CSV
CSV是一种基于文本的表格数据格式,其中每一行代表一条记录。记录中的列或字段通常用分隔符(最常见的是逗号)分隔。第一行通常包含列名作为标题。CSV 格式被广泛支持,因此成为数据交换的热门选择。
1.编码
CSV 文件通常采用UTF-8编码,这样可以确保字符兼容性并使文件可压缩。
2.优势
•易于阅读: CSV 文件易于阅读和理解。
•通用性强: 几乎所有编程语言和工具都支持它。
•易于使用:可以手动生成、编辑和检查。
•兼容性:与电子表格和临时分析工具兼容。
3.缺点
•我认为,这种格式最大的缺点之一是它不存储元数据,不强制执行模式或数据类型,并且默认情况下将所有数据都视为文本。(例如,当使用其他工具读取 CSV 文件时,包含年龄等数值的列可能会被解释为整数,但这完全是一种解释,可能不正确,需要手动验证。否则,错误在所难免。)
•由于其体积庞大且 I/O 速度慢,因此对于大型数据集来说效率低下。与 Parquet 格式相比,根据具体情况,它可能占用大约 10 倍的空间。
•CSV格式不适用于嵌套数据,这是由于CSV格式本身的设计缺陷造成的。例如,在更适合嵌套数据的格式(例如JSON)中,嵌套结构如下所示:
{
"user" : { "id" : 123 , "name" : "Alice" } ,
"actions" : [ { "type" : "click" , "time" : "2025-11-05T12:00Z" } ]
}
相同的 CSV 数据必须以 JSON 字符串的形式表示在单个单元格中:
user_id,user_name,actions
123,Alice,"[{""type"":""click"",""time"":""2025-11-05T12:00Z""}]""[{" "type" ":" "click" "," "time" ":" "2025-11-05T12:00Z" "}]"
这使得阅读、筛选和分析变得更加困难。
4.何时选择 CSV 格式
•适用于对人类可读性要求较高的中小型数据集。
•应用程序、分析师或团队之间轻松共享数据。
•不支持二进制或列式格式的系统或工具。
•快速原型制作或从电子表格(Excel、Google Sheets)导出。
二 JSON
多年来,JSON 一直是最流行的数据格式之一。它可以被视为一种通用语言,使不同的应用程序能够相互理解。其主要目的是促进 Web 服务和应用程序之间的数据交换。在 JSON 出现之前,XML 曾被广泛用于此目的,但它存在诸多缺陷。
XML格式非常冗长,难以阅读,尤其是在处理冗长且嵌套结构的情况下。它占用大量存储空间,解析XML文件会消耗大量的CPU和内存资源,因此不适合处理大数据。此外,XML的兼容性也有限,通常需要专门的库才能解析。
一个简单的 XML 结构示例:
<user> <id>
1 </id> <name> Alice </name> <is_active> true </is_active> <address> <city> Berlin </city> <postal_code> 10115 </postal_code> </address> <hobbies> <hobby> music </hobby> <hobby>
cycling </hobby> </hobbies> </user>
JSON 随后应运而生,它是一种更简洁、更紧凑、人机可读且通用兼容的格式,极大地简化了跨语言数据交换。JSON以文本格式存储键值对数据。它支持嵌套和层级结构,能够自然地表示复杂且深度嵌套的数据。其通用性使其被广泛用于 API 数据传输和配置文件。
一个简单的JSON结构示例:
{
"id" : 1 ,
"name" : "Alice" ,
"is_active" : true ,
"address" : {
"city" : "Berlin" ,
"postal_code" : "10115"
} ,
"hobbies" : [ "music" , "cycling" ]
}
1.编码
UTF-8 通常被使用,因为它既兼容 ASCII,又支持国际字符。由于采用了 UTF-8 编码,JSON 文件可以在不同的平台上无缝共享。
2.优势
•人类可读: JSON 文件是基于文本的,易于人类阅读。
•支持嵌套数据:可以自然地表示复杂和分层的数据结构。
•通用互操作性:几乎所有现代编程语言都支持。
•无模式灵活性:每条记录可以有不同的字段;不需要严格的模式。
•API友好: REST和GraphQL服务的标准格式。
3.缺点
•存储效率低下:每个记录中都重复出现键,这会增加大型数据集的大小。虽然它适用于消息传递,但并不适合大规模存储。
•不强制类型:数字、布尔值或空值均被视为文本;正确的类型由应用程序自行决定。这种缺乏强制的做法可能是一个缺点,尤其是在 ETL 流程中,新数据可能需要持续关注以避免类型错误。
•解析成本:与二进制格式相比,CPU 和 RAM 使用率更高,尤其是对于大文件而言。
•无元数据: JSON 中不包含最小值、最大值或空计数等信息。
•大文件处理:大文件需要流式传输或分块传输;一次性将整个文件加载到内存中是不切实际的。
4.何时选择 JSON
•API 数据交换(REST/GraphQL): JSON 非常适合在不同系统和编程语言之间传输数据。它为 Web 服务、微服务和移动应用程序提供了一种标准、快速且易于解析的格式。
•适用于快速原型设计和共享的中小型数据集:虽然 JSON 不是存储大型数据的最佳选择,但对于中小型数据集来说效果很好。
•人的可读性很重要:与 XML 或二进制格式相比,其基于文本的键值结构使得错误和缺失字段更容易识别和调试。
•嵌套和分层数据: JSON 自然地支持嵌套对象和数组,可以轻松地以清晰有序的方式表示复杂的结构,例如包含地址和订单的用户对象。
三 Parquet
Parquet 是当今最流行的数据格式之一,专为Apache Hadoop 生态系统中的大数据分析而设计。它的主要目标是在高效存储大型数据集的同时,优化查询和分析性能。其最重要的特性是列式结构,这显著提升了查询和存储性能。从很多方面来看,Parquet 都可以被视为大数据时代的主流。
Parquet文件的结构
Parquet文件由三个主要层组成:
Parquet 文件

•行组: Parquet 文件的一部分(例如,100 万行一组)。
•列块:行组中特定列的数据(e.g., user_id, age, country)。
💡注意:每一列(例如,country)并没有存储在整个文件的单个连续块中,而是作为每个行组中的单独列块存储。
行组允许并行读取和基于行的过滤(谓词下推),从而只读取必要的行块,降低 I/O 成本并提高读取性能。
1.编码
Parquet 格式以二进制列式结构存储数据。虽然 Parquet 中的文本数据可能使用 UTF-8 编码,但其效率并非源于编码本身,而是源于其他特性,我们将在下文讨论这些特性。
2.优势
(1)列式结构
采用列式结构可以显著提高 Parquet 格式的效率。其最大的优势在于,在大型查询中,系统只会读取所需的列,而忽略不必要的列。这不仅提高了I/O 性能,还降低了成本。
对基于行的格式(例如 CSV)和基于列的格式(例如 Parquet)的数据进行查询的方式如下:
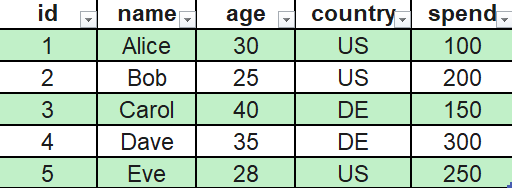
(2)基于行的查询(CSV)
在 CSV 文件中,所有行都以文本形式存储:
1,爱丽丝,30,美国,100
2,鲍勃,25,美国,200
3,卡罗尔,40,德国,150
4,戴夫,35,德国,300
5,伊芙,28,美国,250
查询: “美国客户总消费额”→ 仅需要列country和spend
因为 CSV 是基于行的,所以会读取和解析所有行,包括id、name、age。
I/O 成本: 5 行 × 5 列(读取整个文件)。
(3)列式查询(Parquet)
在 Parquet 格式中,列存储在单独的块中:
列ID:1、2、3、4、5 ;
列名称:Alice、Bob、Carol 、Dave 、Eve;
列年龄:30、25、40、35、28 ;
列国家/地区: US 、US、DE 、DE、US ;
列消费金额:100、200、150、300、250
•查询: “美国客户总支出”→ 仅读取country和spend列块。
•id、name 和 age 不会从磁盘读取,从而降低了 I/O 和 CPU 开销。
•列式格式结合字典编码、游程编码(RLE)和位打包(bit-packing)可减小文件体积并加速读取。
格式 | 读取的数据 |I/O
-----|-------------|------
CSV(行式)|所有行 + 所有列|高
Parquet(列式)|仅 country 和 spend 的数据块|低
(4)行组
行分组不仅按列划分数据,还按行划分数据,具体如下:
•提高I/O 性能
•减少过多的随机磁盘访问
例如:一个文件有 3 个行组,每个行组有 50 万行:
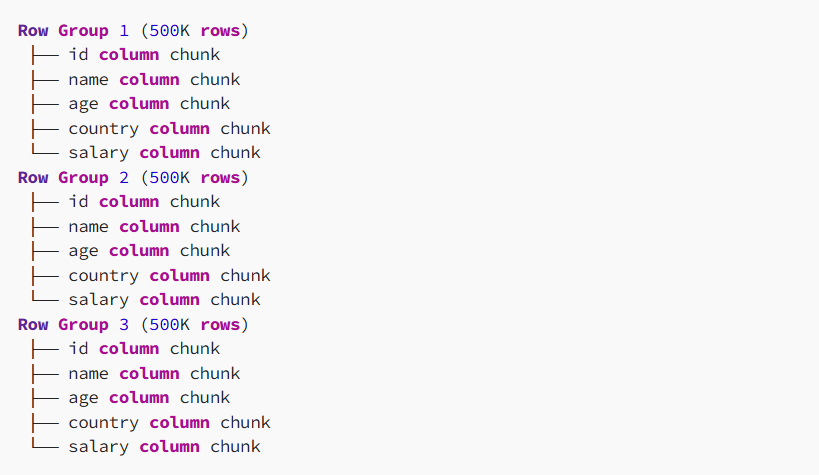
如果我们只查询 ` idA` 和 ` ageB`,就不会访问 `C` name、country`D` 和 `D`salary中的 450 万行数据,从而节省大量资源。行组也可以并行读取,进一步提升性能。
如果我们需要的数据只在一个行组中,则跳过其他行组,从而节省高达 80-90% 的 I/O。
(5)字典编码
Parquet 的另一个效率提升之处在于字典编码。重复值存储在字典中,并通过索引进行引用,从而减少了高度重复数据的存储空间。
例子:
列:[美国, 美国, 德国,美国,德国, … ]
字典:{ 0 :美国, 1:德国}
编码列: [ 0 , 0 , 1 , 0 , 1 , … ]
如果我们有 10K 行:6K United States+ 4K Germany,我们存储索引而不是完整的字符串,最多可以节省约 90% 的空间。
原始文本(CSV):
6,000 × 13 = 78,000字节4,000 × 7 = 28,000字节总计:106,000字节≈ 103.5 KB字典编码(Parquet ) 10,000行→ 2个类别→每行1字节(或至少1位)总编码:10,000字节≈ 9.8 KB
(6)游程编码(RLE)
RLE 对连续重复的值进行数值计数:
列: [ 0 , 0 , 0 , 1 , 1 , 2 , 2 , 2 , 2 ]
RLE: [ (0 , 3 ) , (1 , 2 ) , (2 , 4 ) ] # 前三个值为 0 等
•数值使用最少位数。
例如:值为 0-3 的列只需要2 位而不是 32 位。(7)模式强制执行与元数据
Parquet 文件包含有关文件及其数据类型的元数据。
元数据存储模式和数据类型,以便下游消费者可以信任数据类型,而无需重新定义模式或依赖自动检测(自动检测容易出错)。
元数据还包括 Parquet 版本、创建者、写入工具(Spark、Pandas 等)、列最小值/最大值(启用谓词下推)、空值计数和值计数。
3.缺点
Parquet 格式不具备可读性:它是一种二进制格式;直接读取它只会显示原始二进制数据。需要使用专门的工具(例如 PyArrow、Pandas、Spark、DuckDB)来检查或处理数据。
小型数据集的写入开销:元数据、编码信息和字典表会使 Parquet 文件比小型 CSV 文件大得多。例如,一个包含几百行的 CSV 文件可能只有 10 KB,而相同数据的 Parquet 文件则可能需要 100 KB。
兼容性问题:并非所有系统或轻量级工具都直接支持 Parquet 格式,包括:
•遗留系统
•基本电子表格或商业智能工具
•小型嵌入式或基于脚本的解决方案
•通常需要中间库(例如 Pandas、PyArrow、Spark)才能读取。
4.何时选择Parquet
•大规模分析和大数据查询: Parquet 格式非常适合拥有数百万甚至数十亿行数据的数据集,尤其适用于对查询性能和 I/O 效率要求极高的情况。其列式结构允许仅读取必要的列,从而减少磁盘和内存使用量。
•嵌套或复杂的数据结构: Parquet 支持结构体、数组和映射等复杂数据类型,使其适用于分层或半结构化数据,而这些数据在 CSV 等基于行的格式中会显得很繁琐。
•云存储和成本效益:在云环境中,仅读取所需列可降低 I/O 和计算成本。Parquet 的压缩和编码特性可进一步减少存储占用。
•ETL管道和分析框架: Parquet可与Spark、Hive、Presto和DuckDB等大数据工具无缝集成。当数据将被多个下游分析系统使用时,它堪称完美之选。
•基于列值过滤场景:当查询涉及基于列值进行过滤时(例如,WHERE country = 'US'),Parquet 的行组和元数据允许跳过不相关的数据块,从而大幅提高查询速度。四 Avro
Apache Avro 是 Apache Hadoop 生态系统中最古老、最成熟的数据格式之一。它由 Hadoop 的创建者 Doug Cutting 开发。其主要目的是解决数据可移植性和模式定义方面的不足。Avro基于行,与早期格式不同的是,它采用二进制而非文本格式。这使其更高效、更快速、更节省空间。
例如,考虑一个 10 位数:
1234567890
•在 CSV 或 JSON 格式中,每个数字都存储为一个字符(每个数字占用 1 个字节):
'1' → 00110001
'2' → 00110010
...
'0' → 00110000
•总计:10 字节。解析需要将每个字符转换回整数。
•在像 Avro 这样的二进制格式中,该数字以 int32(4 字节)形式存储,节省了约 6 个字节,并且允许直接内存访问而无需解析,从而显著提升了速度。
Avro 也像 Parquet 一样提供模式强制执行,这意味着模式存储在文件元数据中。
1.文件结构
Avro 文件由三个主要部分组成:
Avro 文件

•头部:包含描述数据结构的“魔数”和模式定义(JSON 格式)。
•数据块:以压缩二进制形式存储实际数据。数据块支持并行处理;程序可以跳过不需要的数据块以加快访问速度。
•同步标记:充当断点,帮助在文件损坏时恢复数据。
编码
•Avro 以二进制格式存储数据,比 JSON 或 CSV 格式小得多。
•无需进行文本解析,因此CPU 使用率低。
2.优势
•模式演化与类型强制执行
•该模式嵌入在文件中,确保类型安全和向前/向后兼容性。
向后兼容性示例:
旧模式:
{
"type" : "record" ,
"name" : "User" ,
"fields" : [
{ "name" : "id" , "type" : "int" } ,
{ "name" : "name" , "type" : "string" }
]
}
旧数据(二进制表示,以 JSON 格式显示):
{ "id" : 1 , "name" : "Alice" }
{ "id" : 2 , "name" : "Bob" }
新增模式,添加了字段(is_active)及其默认值true:
{
"type" : "record" ,
"name" : "User" ,
"fields" : [
{ "name" : "id" , "type" : "int" } ,
{ "name" : "name" , "type" : "string" } ,
{ "name" : "is_active" , "type" : "boolean" , "default" : true }
]
}
使用新模式读取旧文件会产生以下结果:
{ "id" : 1 , "name" : "Alice" , "is_active" : true }
{ "id" : 2 , "name" : "Bob" , "is_active" : true }
•旧数据不包含新字段,但Avro 会使用默认值填充该字段,从而确保向后兼容性。向前兼容性则以相反的方向实现。
紧凑二进制格式
•比文本格式小得多(大约是 JSON 大小的 10-20%),但比 Parquet 大。
快速序列化和反序列化
•序列化和反序列化数据时 CPU 使用率极低,使其成为Kafka、Flink 和 Spark Streaming 等实时系统的理想选择。
与语言无关
•模式在 JSON 中定义,数据是二进制的 → 可以轻松地在 Python、Java、Go、C++、Scala 等中使用。
非常适合流媒体播放
•基于行的结构意味着每个记录都是独立的,非常适合基于事件的处理(Kafka 主题、消息传递系统)。
3.缺点
人类无法阅读
二进制格式无法直接读取;需要 PyArrow、Avro 工具或 Spark 等工具进行检查。
基于行的结构
SELECT AVG(price)对于分析查询(例如,在大数据集上),列式格式(Parquet/ORC)效率较低。
读取模式所需
没有模式就无法读取数据。模式必须嵌入在文件中或可从外部获取。
压缩技术不如Parquet/ORC先进
行式存储限制了压缩效率;列式格式可以实现更好的存储空间缩减。
4.何时选择 Avro
流式传输和消息传递系统: Kafka、Flink、Pulsar 等,其中事件需要快速序列化。
模式管理和向后兼容性:跨版本自动模式演化。
类型安全:与 JSON 不同,Avro 强制执行数据类型。
适度的存储优化:比文本格式小,但不需要列式压缩。
高频 ETL 和微服务:适用于服务间数据流密集的系统。
五 ORC(优化行列式)
ORC 是一种专为 Hadoop 生态系统开发的高性能列式二进制数据格式。它专为分析海量数据而设计,因此具有很高的查询效率和压缩率。它也像 Parquet 一样具有模式强制执行功能。
1.文件结构
ORC 文件包含三个主要部分:

Postscript:数据以大块形式存储,每列都是独立的。也就是说,一个条带包含一组行的逐列数据。
Footer:包含所有架构、统计信息和条带位置。
Stripes:提供有关压缩、文件格式版本和页脚长度的信息。
下面我们通过一个例子来更清楚地理解这三个部分;
假设我们有一个客户表;
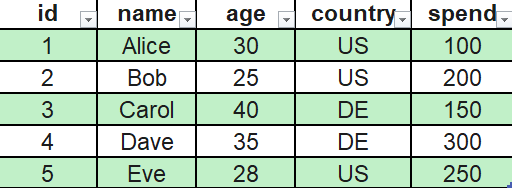
ORC 文件
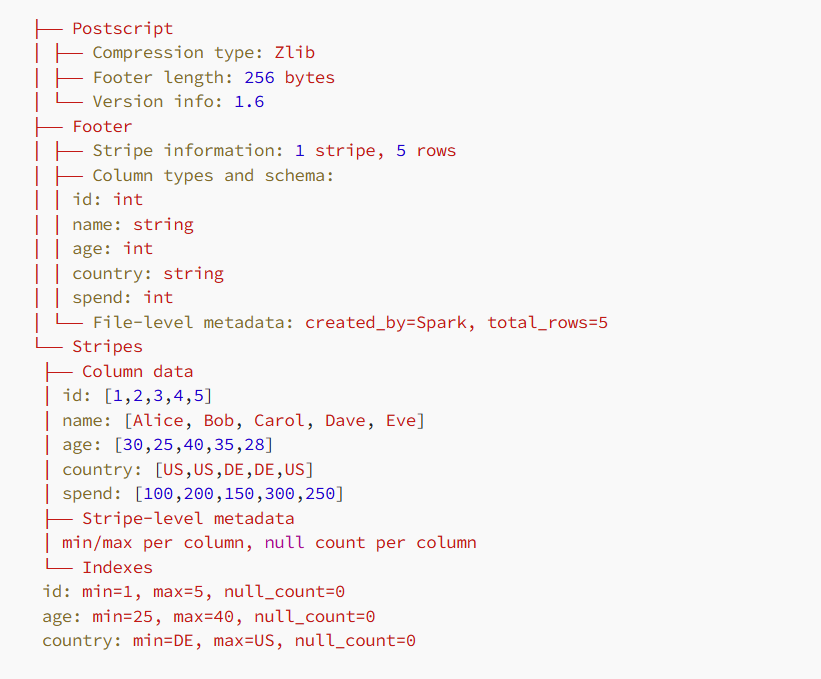
2.编码方法
ORC 的编码方式与 Parquet 非常相似;我们在此不再赘述。您可以在上面的 Parquet 部分阅读相关内容。不过,我们可以大致讨论三种基本方法;
字典编码:对于重复值,创建一个字典,并存储字典中的索引而不是数据本身。
游程编码(RLE):连续相同的值用一个值及其重复次数表示。
位打包:对于数值,使用最少的位数,例如,对于 0 到 3 之间的值,只需 2 位就足够了。
3.优势
•高压缩比: ORC 具有很高的压缩比。这主要是因为数据是按列存储的,并且相似的数据是连续存储的。我们在 Parquet 部分已经提到过这一点,并指出这种方法称为游程编码 (Run-Length Encoding)。
•模式强制执行:与 Parquet 格式一样,ORC 也具有模式强制执行机制。我们前面已经讨论过它的重要性。
•快速分析: ORC 与 Parquet 类似,仅在需要时才访问数据,从而显著提升读取性能。更多详细信息,请参阅 Parquet 部分。
4.缺点
ORC的缺点与Parquet的缺点非常相似;简而言之,这些缺点包括:
•不可读:由于 ORC 是二进制格式,因此无法浏览或读取。
•基于行的更新很困难:它专为追加或批量分析而设计,而非事务性的行级更新。它更侧重于分析,因此不适合行级更新。这是因为数据以列为单位存储在较大的数据块(条带或行组)中;更改单行需要重写所有相关的列数据块。
•小数据集的元数据开销:对于非常小的表,元数据和条带开销可能会使 ORC 比 CSV 或 Avro 更大。
•工具依赖性:某些轻量级工具或旧系统可能不支持 ORC 原生支持。
5.何时选择 ORC
•对大型数据集进行分析查询: ORC 在读取密集型分析工作负载(如 Hive 或 Spark 中的聚合、过滤和连接)中表现出色。
•需要高压缩率:重复性或低基数数据集可受益于 ORC 的列式压缩。
•Hadoop 生态系统集成:与 Hive、Spark、Presto、Impala 或 HDFS/S3 存储配合使用时非常理想。
•谓词下推/更快的过滤: ORC 的条带级元数据可以高效地跳过不必要的数据。
•具有批量追加功能的稳定模式:非常适合追加密集型管道,但不太适合事务性行更新。
6.Parquet 与 ORC区别
这两种文件类型都是二进制、列式存储,并且在许多方面都使用非常相似的方法。然而,它们在某些方面也存在差异。首先,ORC 格式的优化更为激进。因此,在某些情况下,ORC 格式可以获得更好的压缩效果,并且由于其元数据更详细、更全面,因此也能提供更好的读取性能。
我们将在平台上使用的工具也很重要。ORC 主要面向 Hive 和 Hadoop,因此在这里速度可能更快;而 Parquet 在云端和异构系统中表现更佳,具有更强的平台兼容性和通用性。虽然这两种工具通常都适用于批量分析,但使用 ORC 添加少量数据或进行基于行的数据更改效率较低。Parquet 在这方面则更加灵活,可以根据具体情况用于此类操作。让我们简要比较一下这两种工具:
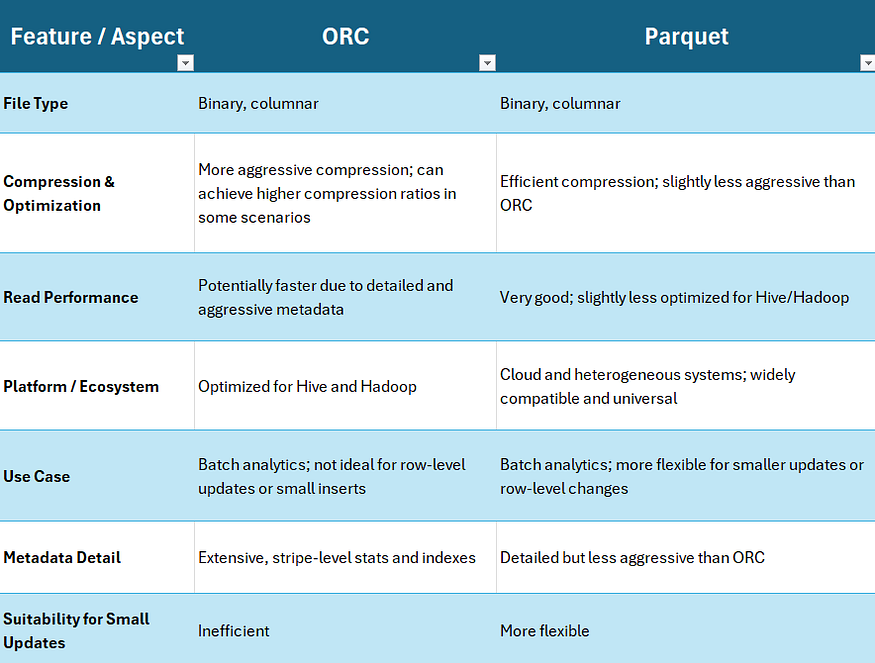
今天,我们介绍了大数据生态系统中的关键数据格式:CSV、JSON、Parquet、Avro 和 ORC。我们分析了它们的主要特性、优势、劣势以及各自最适用的场景,包括存储、性能、模式强制执行、压缩和兼容性等方面的考量。您可以在下方找到总结表。

来源(公众号):数据驱动智能




