

引言
在本系列前面的文章中,我们分别介绍了《什么是数据中台》和《为什么数据治理是持续性的?》
也为大家介绍了龙石数据“理采存管用”的数据治理方法论。
不少读者反馈,对“数据仓库”这个词还不太清楚:它和数据中台到底是什么关系?数据中台既然覆盖“理采存管用”,那数据仓库又在其中扮演什么角色?
在深入探讨“理”(梳理)和“采”(采集)之前,我们可以先把“存”(存储)这个环节讨论一下。
- 数据中台和数据仓库的区别与联系
- 数据仓库为什么需要分层
- 业界常用的分层思路有哪些
- 龙石数据在实战中总结的分层模型是怎样的
一、数据中台 vs 数据仓库
数据中台:是一个承载“理采存管用”全流程的“工具与管理平台” ,核心是让数据能力可复用、可服务化。
数据仓库:是中台体系中负责 “存”的 “数据地基”。
它们的关系是:
数据经过中台的治理(理)和采集(采)后,存入数据仓库;再通过中台的调度和管理(管),最终以服务形式(用)支撑业务应用。
通俗来讲,数据中台操作数据,负责把数据治好。数据仓库存储数据,负责把数据存好。

二、数据仓库为什么一定要分层?
数据仓库的命名源于“仓库”的概念,其设计核心在于解决数据管理中的混乱与低效问题。若将原始数据、加工数据及应用数据混杂存储于单一存储层,将导致数据定位困难、管理复杂、查询性能低下。数据仓库分层设计正是为应对这一挑战,通过结构化组织实现数据的高效治理与利用,数据仓库有以下优点:
结构清晰:像“俄罗斯套娃”一样,采用分层架构(如ODS、DWD、DWS、ADS),每层职责单一,将复杂数据流程简化为可管理的模块化处理,复杂问题简单化。
数据复用:沉淀公共指标和宽表,避免“重复造轮子”,极大提升下游开发效率。
任务解耦:复杂任务拆成多个步骤,便于运维和重跑,一层失败不影响全局。
查询加速:空间换时间,通过预处理和汇总,让上层应用(AI用数、BI、大屏)查询更快。
水平扩展:多数数仓基于分布式架构支持弹性扩容,无缝适配数据量增长场景,确保系统在高负载下保持高性能与高可用性。
三、业界主流的分层思路
3.1 经典两大流派
Inmon(自顶向下):
主张先建企业级数据仓库(EDW),再建数据集市。
Kimball(自底向上)
主张先围绕业务过程建数据集市,再通过一致性维度整合成企业视图。

Inmon(自顶向下)就像先建一个巨型中央仓库,把所有货物标准化后,再分发给各部门小店;
而Kimball(自底向上)则像先为各部门开专业零售店,但使用统一的商品编码和会员体系,让这些店能轻松连锁成一个大超市。
前者强调整合与统一,后者追求速度与实用。现代数据平台通常结合两者思想。
3.2 当前共识:五层模型
融合了经典思想,互联网和大厂普遍采用五层结构:
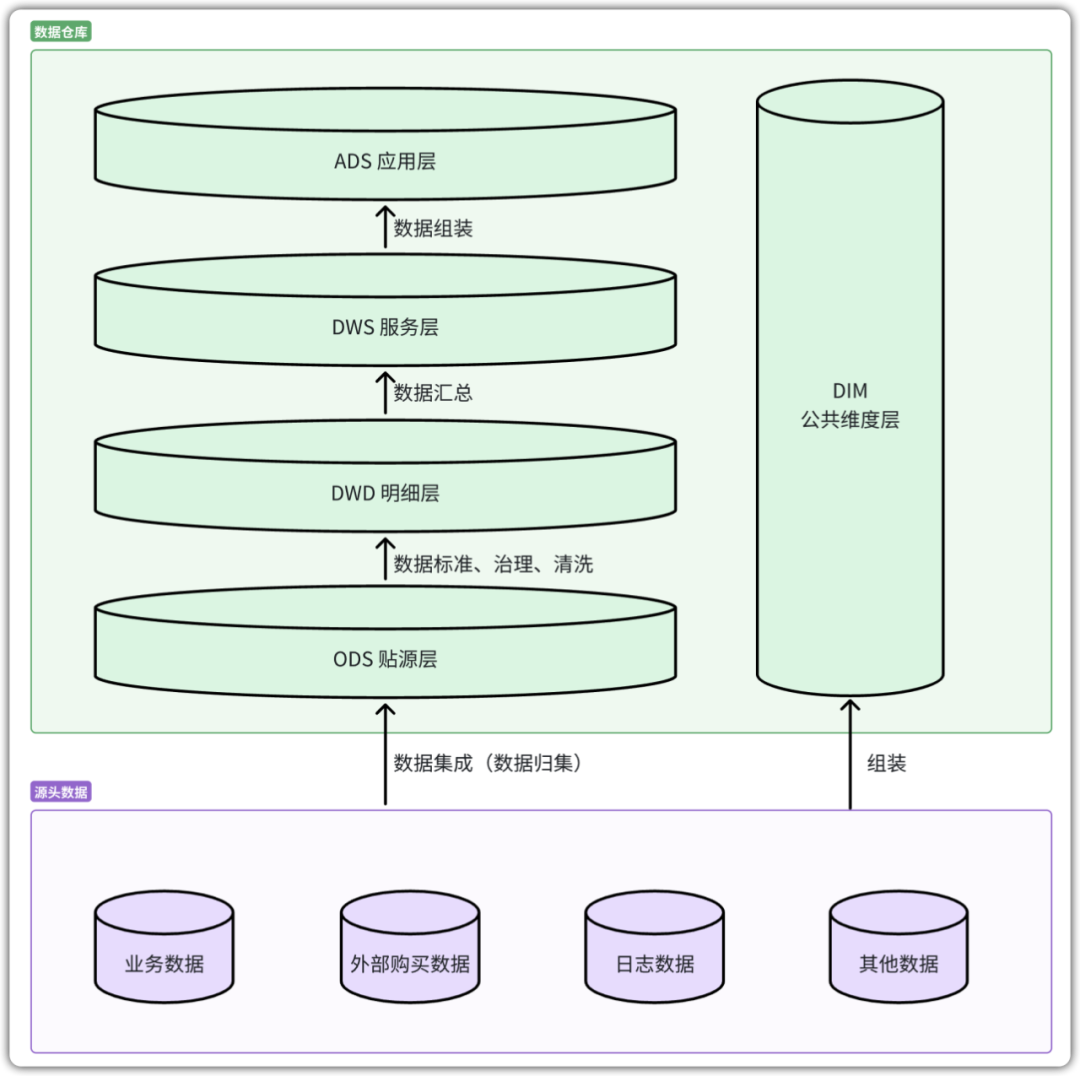
- ODS(贴源层)
贴源层顾名思义是从源头粘贴数据,同城使用数据集成工具(ETL),将源头业务系统数据进行归集,保持数据的原貌,不做任何修改,隔离源头业务系统,不影响原系统的运行。
- DWD(明细层)
当原始业务数据进入ODS层时,会对数据进行标准、治理的检查,将问题数据进行清洗、转换、去重、标准化等动作,实现数据的自优化。
- DWS(服务层)
DWS服务层,更多地贴近业务场景,在DWD明细层的基础上进行汇总加工和聚合计算,例如将事实表中的聚合度量值和维度表中的数据进行汇总聚合,借助DIM公共维度层的不同维度,计算分析出多维度的业务信息。
- ADS(应用层)
ADS层为数据产品、报表和分析服务提供可直接使用的数据,支撑业务决策的数据应用和报表分析。
- DIM(维度层)
DIM贯穿于ODS、DWD、DWS、ADS,确保各层数据计算中维度的一致性和准确性。提供通用的维度属性,常见的维度包括,时间维度:年、季度、月、日、时等;空间维度:物理位置、网络地址等。
五层结构相互独立又协同工作,形成高效的数据处理与分析体系,支持智能化的业务应用。
数据流向:ODS → DWD → DWS → ADS
DIM 贯穿所有层次,确保维度一致性
这种架构兼顾高内聚、低耦合的数据仓库建设思路,但对团队建模能力要求较高,不少中小企业在落地时感到吃力。
四、龙石数据的实战分层模型
如果说 3.2 的五层模型是学院派,龙石数据的数仓分层就是实战派。龙石数据中台目前支持多种常见数仓,也对信创数据库(如达梦、人大金仓)做了良好适配。无论底层选Doris、StarRocks还是PostgreSQL,都将分层思想内嵌到平台中,提出一套更实战、易用、低门槛的分层模型:
SRC(来源层) → ODS(贴源层) → DW(治理层) → ADS(应用层) → DS(共享层)
4.1 设计思路:让数据好管好用
1. 可行性与易用性
架构不是为了“炫技”,而是为了更快更好地实施和使用。考虑到数据工作未来会引入更多业务人员,以及“中国式速度”的要求,我们的模型必须“开箱即懂”。
2. 强化“理采”与“用”的映射:
将「SRC-来源层」纳入: 明确映射“理采存管用”中的“理”和“采”的起点,方便从源头理解数据。
将「DS-共享层」纳入: 明确映射“用”的出口,让数据提供者和消费者清晰知道“数据成品”在哪。
3. 降低“存”与“管”的门槛:
弱化DW细化分层: 将业界DWD(明细)和DWS(汇总)合并简化为「DW-治理层」。
解耦DIM维度层: 将「DIM-维度」的管理从数仓ETL中剥离,交由龙石中台的“数据标准、数据清洗”模块进行维护。
让实施人员无需精通复杂的Kimball建模,大幅降低数据工作的门槛。
4. 确保规范(前提):
简化不等于随意。没有规范的敏捷是“灾难”。龙石模型通过中台工具将规范(如标准、质量等)“嵌入”到数据的归集、清洗、共享流程中,确保“简化”后的数据质量。
4.2 龙石五层模型详解

- 第 0 层:SRC(来源层)
逻辑层,不存实际数据。作用是梳理数据资产,比如“CRM系统-客户表”,这是数据治理的起点。
- 第 1 层:ODS(贴源层)
物理层,把源系统数据原样同步过来,只做轻微格式处理,不做业务加工。作用是可回溯、解耦业务库压力。
- 第 2 层:DW(治理层)
核心层,融合了明细和汇总功能。在这里执行数据清洗、标准化、关联和轻度汇总,产出可信、可复用的数据。
- 第 3 层:ADS(应用层)
面向具体业务场景做深度加工,比如大屏数据、报表数据、算法样本等。DW 层保持稳定,ADS 层灵活响应需求。
- 第 4 层:DS(共享层)
逻辑层,将 ADS 的数据包装成 API 或数据目录,供业务系统或人员直接调用。使用者无需关心数据存在哪里。
五、龙石数据的实战分层模型
数据中台是平台,数据仓库是地基。分层是为了让数据更清晰、可复用、易治理。
业界有 Inmon、Kimball 等经典思路,也有通用的五层模型,但对实施能力要求高。龙石数据在此基础上,提出更注重实战的五层模型(SRC/ODS/DW/ADS/DS),通过中台工具降低建模门槛,能更快落地“存好、管好、用好”数据的目标。
本文基于小编当前实践经验整理,数据仓库领域发展迅速,数据湖等新概念也不断涌现,但分层管理的核心思路始终未变。龙石数据长期专注于数据管理能力的输出,目前我们正在将多年实战经验整理成书,未来也会在书中更系统地介绍数据仓库相关内容,希望能更好地助力大家的数据治理工作。




