

前言
“数据驱动业务”是几乎所有企业数字化转型的口号。然而,现实却很骨感:不少公司建了庞大的数据中台,买了昂贵的BI工具,组建了专业的数据团队,但最终产出的报表和模型,要么被束之高阁,要么对业务决策影响甚微。为什么?因为大家不约而同地掉进了以下三个看似不起眼、实则致命的落地陷阱。
陷阱一,指标满天飞,口径无人管——“数据驱动”沦为“数据打架”
这是最普遍也最基础的问题。市场部说的“活跃用户”和产品部统计的不是一个数;销售团队汇报的“季度业绩”和财务系统里的对不上。当核心指标的定义、计算逻辑、数据来源都不统一时,所谓的“用数据说话”就成了一句空话,甚至会引发部门间的信任危机。
实践真知,我们曾服务过一家快速扩张的电商公司,其内部有超过5个不同版本的“GMV”定义。每次开经营分析会,各部门都要先花半小时解释自己用的是哪个口径,效率极低,结论也互相矛盾。
我们的解法是回归根本:建立企业级的指标管理体系。这不是简单地建一个指标字典,而是要完成三步走:
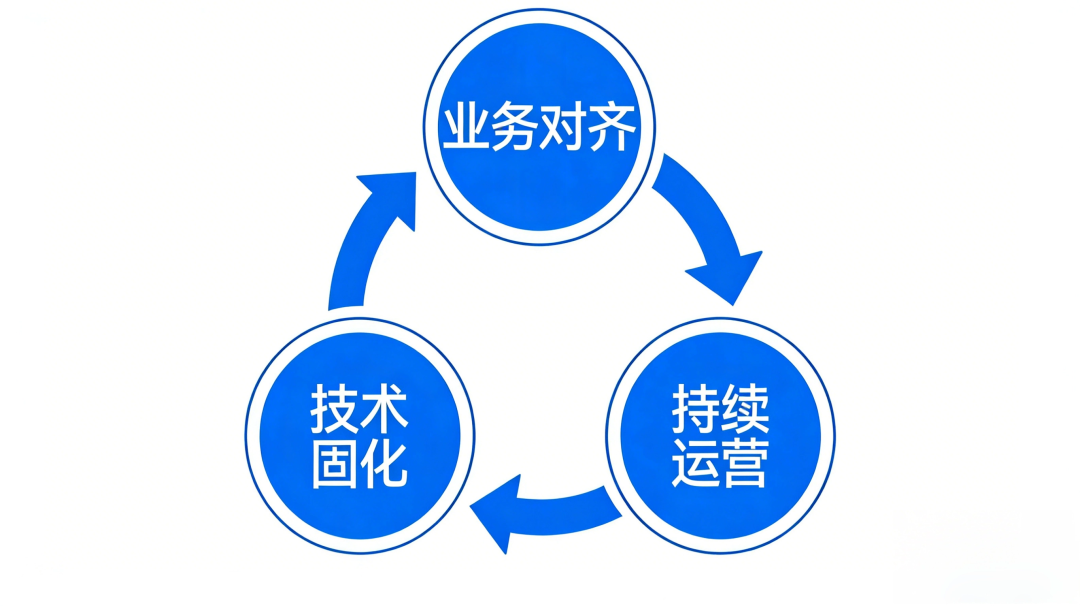
1. 业务对齐,召集所有关键干系人,共同确认哪些是公司的“北极星指标”和核心过程指标。
2. 技术固化,将达成共识的指标口径,以原子指标+派生指标的方式,在数据开发平台中进行标准化封装,确保“一处定义,处处使用”。
3. 持续运营,设立指标Owner,负责指标的解释、变更管理和问题答疑。这个过程需要极大的耐心和跨部门协调能力,但它是一切数据驱动的基石。没有可信、一致的数据,后续所有分析都是空中楼阁。
避坑指南
不要追求大而全,初期聚焦最关键的10-20个核心指标,打透做透,比维护几百个无人问津的指标更有价值。
不要只靠文档,指标口径必须通过技术手段固化到数据生产流程中,而不是躺在Confluence里吃灰。
优化方向,将指标管理与数据血缘深度结合,任何指标的变动都能自动追溯到上游影响范围,并通知到所有相关方,实现真正的闭环治理。
陷阱二,技术很先进,业务看不懂——“数据驱动”变成“数据自嗨”
很多数据团队容易陷入技术优越感,热衷于追逐最新的算法、最复杂的架构。结果是,辛辛苦苦做出的用户画像、智能推荐模型,业务部门却表示“看不懂、不会用、不敢信”。
实践真知,在一个零售客户的项目中,我们的算法团队开发了一个非常精妙的销量预测模型,准确率高达95%。但门店店长们却更愿意相信自己的经验。后来我们才明白,模型给出的只是一个冰冷的数字,而店长需要知道“为什么是这个数”,比如“因为天气预报说周末有雨,所以雨具销量会上升”。
于是,我们调整了策略,不再只交付一个预测结果,而是提供可解释的洞察。我们将模型的关键因子(如天气、促销、历史趋势)可视化,并用业务语言描述出来。这样一来,模型从一个“黑盒”变成了一个“参谋”,真正融入了店长的日常决策流程。
避坑指南
不要闭门造车,在项目启动之初,就必须让业务方深度参与,明确他们的真实痛点和期望的交付形式。
不要忽视“最后一公里”,再好的分析结果,如果不能无缝嵌入业务人员的工作流(比如CRM、ERP系统),就很难产生实际价值。
优化方向,培养“翻译型”人才,即既懂数据又懂业务的桥梁角色。同时,推动建设低代码/无代码的数据应用平台,让业务人员也能自助地探索和消费数据。
陷阱三,重建设轻运营,项目结束即终点——“数据驱动”无法形成正向循环
很多企业把数据项目当作一次性工程来对待。项目验收后,数据资产便无人维护,模型效果随时间衰减,用户活跃度日渐低迷。这导致数据驱动无法形成“应用-反馈-优化”的正向循环,最终项目成果被废弃。
实践真知,我们见过太多漂亮的BI看板,在上线三个月后就再也没人点开过。原因很简单:看板内容一成不变,无法响应业务的新问题;数据偶尔中断,也没人修复,久而久之大家就失去了信任。
真正的解决方案是建立数据产品的运营思维。这意味着:
设立专职的“数据产品经理”或“数据运营”角色,负责持续收集用户反馈,迭代优化数据产品。
建立数据健康度监控体系,对数据的时效性、完整性、准确性进行常态化监控,并设置告警机制。
将数据使用情况纳入考核,鼓励业务部门主动使用数据,并分享成功案例,形成组织内的数据文化。
避坑指南
不要把预算全花在建设期:务必为项目的长期运营预留资源和人力。
不要只关注技术指标:除了系统稳定性,更要关注业务指标,如DAU(日活用户)、报表采纳率、由数据驱动产生的业务收益等。
未来展望
跨越这三个陷阱,数据驱动才能从一句口号变为企业的核心能力。未来的竞争,不再是看谁拥有更多的数据,而是看谁能更高效、更敏捷地将数据转化为行动和价值。这条路没有捷径,唯有脚踏实地,从业务中来,到业务中去,才能让数据真正成为驱动企业增长的澎湃引擎。
来源(公众号):数据仓库与python大数据




