

概念鸿沟:为何大语言模型在数学推理上举步维艰
大语言模型(LLMs)已展现出令人惊叹的能力,能够解决曾被认为远超其能力范围的数学问题。它们可以解答竞赛级别的题目并执行复杂的数值计算。然而,仔细观察便会发现一个关键弱点:许多LLMs擅长程序性的模式匹配,但在真正的概念理解方面却有所欠缺。这一现象常被描述为 “定义-应用鸿沟”。

一个LLM或许能够完美地复述数学定理,如有理根定理,但在正确应用该定理解决问题时却会失败,尤其是当问题的表述方式稍有不寻常时。如研究中的图1所示,一个最先进的模型可以正确陈述该定理,但在将其应用于一道分子和分母角色被互换的多选题时,仍然会出错。这表明模型的解题过程往往固守于僵化的、基于启发式的模式,而非由对底层概念的灵活理解所引导。
流行的训练方法,如带可验证奖励的强化学习(RLVR),加剧了这一鸿沟。这类流程通常根据最终答案的正确性来奖励模型。虽然这能提升性能,但奖励信号过于粗糙。它并未告诉模型应使用哪个概念、在推理过程的何处应用它,或如何正确使用它。结果,模型学会了优化其搜索启发式方法并复用熟悉的解题模板,但未必学会了概念本身。这使得它们在面对需要真正概念推理的干扰和新问题时显得脆弱。
引入CORE:面向概念的强化学习
为应对这一根本性挑战,研究人员开发了 CORE,一种新颖的强化学习框架,旨在弥合数学推理中的定义-应用鸿沟。CORE的核心思想是在训练过程中,将抽象的数学概念转化为直接的、可控的监督信号。
CORE不仅奖励正确的最终答案,还提供细粒度的概念监督,以强化整个推理路径。其目标是教会模型不仅知道正确答案是什么,更要理解为什么它是正确的,通过将解决方案锚定在相关的数学原理上。通过这种方式,CORE鼓励模型超越表面的模式匹配,发展出更稳健的概念能力。
CORE框架的关键优势之一在于其通用性。它被设计为与算法和验证器无关,这意味着它可以与标准的策略梯度强化学习算法(如GRPO或PPO)集成,而无需改变模型架构。这使得CORE成为一个实用且可推广的工具,用于增强各种LLMs的数学推理能力。
CORE如何运作:从教材整理到概念对齐的测验
CORE的基础是一个精心整理的、高质量的数据集,该数据集明确地将数学概念与相关练习联系起来。该过程始于一个提供结构化、逻辑化课程大纲的规范来源。
从规范教材进行数据整理
研究人员选择了一本经典教材《高等代数(第三版)》,主要基于两个原因。首先,它提供了全面的课程大纲,每个章节都介绍了核心概念定义(C),提供了说明性示例,并包含了主要测试该章节概念的概念对齐练习(E)。其次,通过将原始中文文本手动翻译成英文,研究人员显著降低了困扰许多现有英文语料库的训练数据污染风险。这一初步整理工作产生了236个概念文本以及超过700个相关示例和练习。
用于可扩展训练的综合概念探针
为创建更大、更直接的训练和评估信号,CORE引入了概念探针 的想法。这些是从教材的概念定义直接生成的有针对性的多选题测验。研究人员使用了一个强大的生成器模型来创建一个包含1200个测验的候选池。为确保质量并减少偏差,一个独立的、强大的评估器模型执行了严格的验证,将候选池筛选至1110个高质量测验。
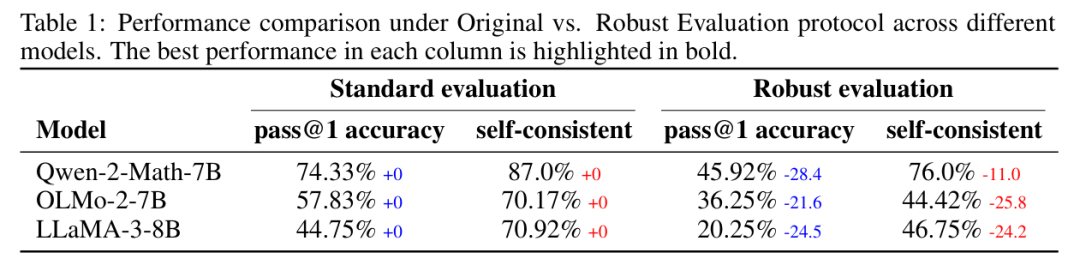
这些概念探针构成了一项诊断实验的基础,该实验量化了概念鸿沟。如表1所示,当模型在“稳健评估”协议下进行评估时——即多选题选项的顺序被随机打乱——其性能急剧下降。例如,某个模型的准确率从超过70%降至50%以下。这提供了强有力的经验证据,表明模型依赖于浅层启发式方法,而非对底层概念的深层结构性理解。
为理解而训练:轨迹替换与正则化
在具备概念对齐数据的基础上,CORE采用了一种巧妙的强化学习方案来灌输概念理解。其核心机制是一个条件干预,该干预在模型表现出概念失败时(即针对某个问题生成的所有解决方案均不正确)精确激活。该过程在图2中可视化,并主要有三种变体。
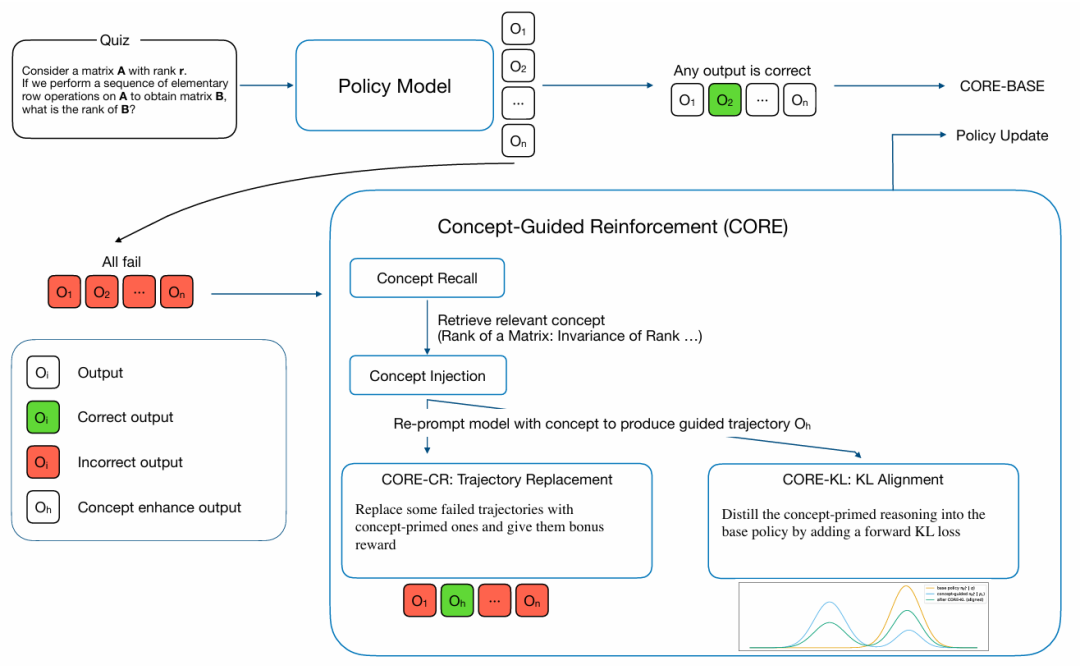
CORE-Base:这是基础方法。模型使用标准RL算法直接在整理好的概念测验集上进行训练。它作为衡量仅在概念丰富数据上训练所带来的益处的基线。
CORE-CR(概念引导的轨迹替换):此方法提供明确的纠正性反馈。当模型未通过测验时,CORE-CR进行干预:
检索与该测验相关的真实概念文本。
使用原始问题加上概念文本重新提示模型,以生成新的、“概念启动”的轨迹。
然后,随机用这些新的、概念引导的轨迹替换部分原始失败轨迹,并赋予它们一个增强的奖励:。 这直接激励模型学习概念与其正确应用之间的联系。
CORE-KL(概念引导的KL正则化):此方法提供一种更隐式的、细粒度的信号。同样在失败时触发,它鼓励模型的标准推理过程与其更稳健的、概念启动的过程对齐。这是通过向RL目标添加一个前向KL散度损失项来实现的:
该损失本质上迫使模型在原始问题()上的内部推理,忠实地模仿其在被明确给予指导概念()时会遵循的过程。
这些变体共同提供了通过显式替换和隐式正则化将概念信号注入训练过程的互补策略。
检验CORE:跨基准测试的性能提升
实证结果有力地证明了CORE框架的有效性。使用CORE训练的模型不仅在内域任务上表现出持续且显著的性能提升,在一系列外域基准测试中也同样如此。
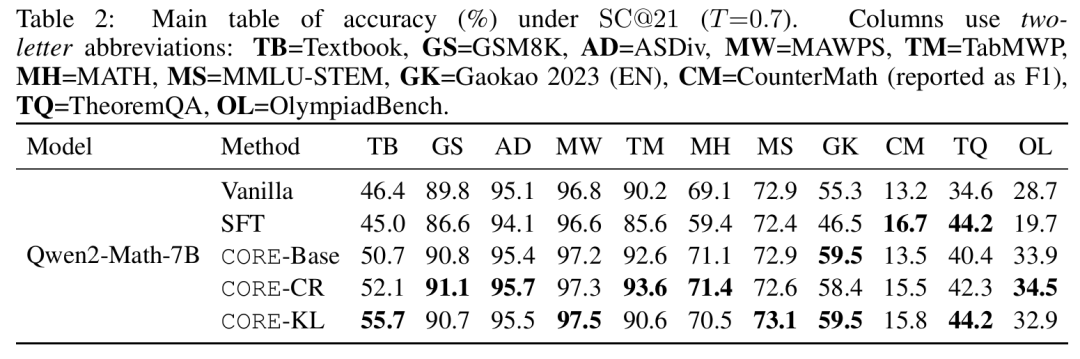
如表2所示,使用CORE变体训练的Qwen2-Math-7B模型相较于原始基线取得了显著提升。在内域的Textbook测试集上,使用CORE-KL时,准确率从46.4%跃升至55.7%。更令人印象深刻的是,这些提升具有泛化性。在明确测试定理应用的THEOREMQA基准上,准确率从34.6%上升至44.2%。在GSM8K、MATH和其他具有挑战性的数据集上也观察到了类似的改进。
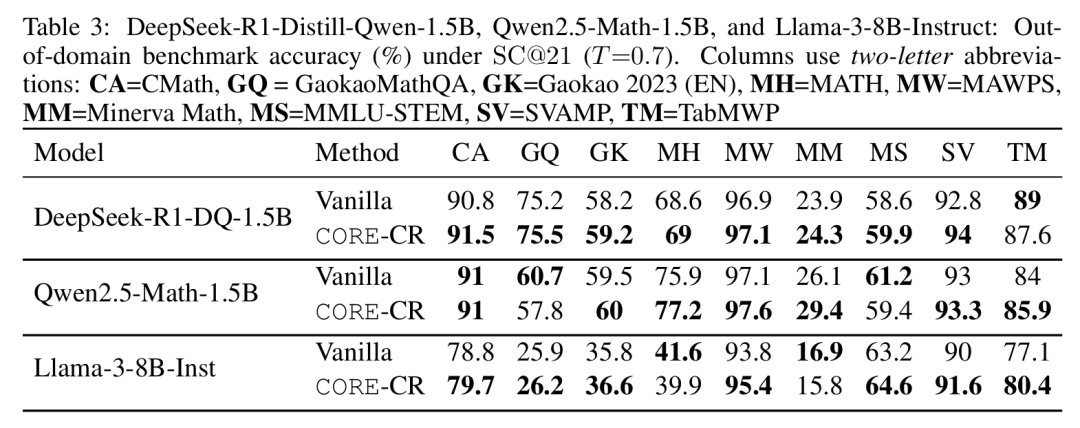
进一步的实验证实,CORE的益处并不局限于单一模型。表3显示CORE是模型无关的,为不同的模型(如DeepSeek-R1-Distill-Qwen-1.5B、Qwen2.5-Math-1.5B和Llama-3-8B-Instruct)在基础版和指令调优版设置下均带来了一致的改进。
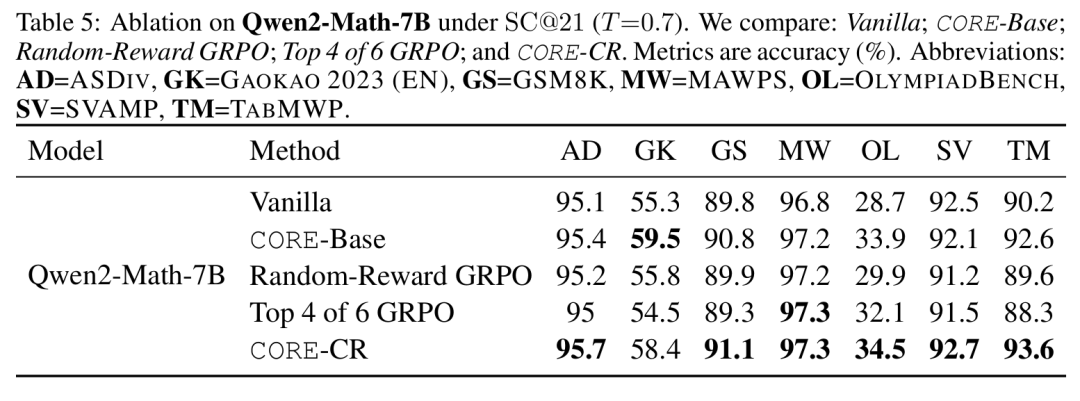
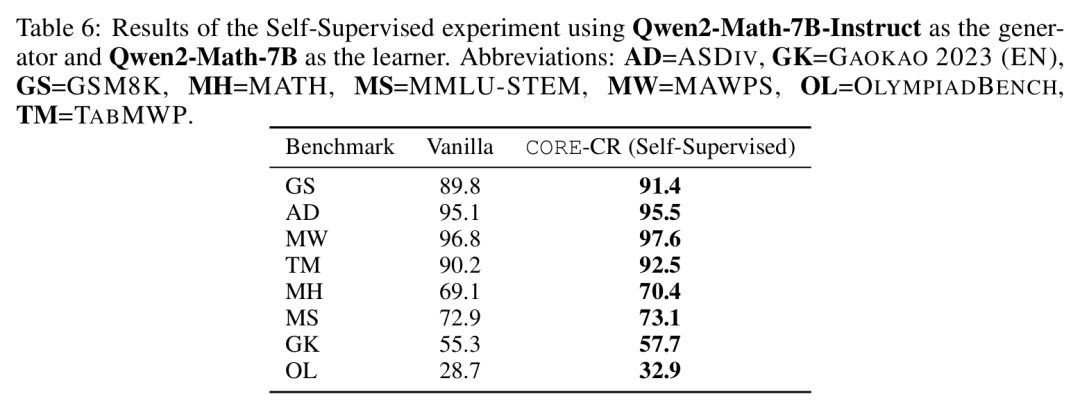
关键的是,消融研究验证了这些提升归因于CORE的独特机制。表5显示,仅使用随机奖励或在GRPO中增加候选解决方案的数量并不能复现这些改进。此外,一项在表6中详述的“自监督”实验(整个流程被限制在单一模型家族内)证明,CORE的有效性并不依赖于从优越教师模型进行知识蒸馏。 驱动学习的是概念引导干预的内在逻辑,而非外部专业知识。
超越模式匹配:在AI中培养真正的概念能力
CORE的成功为开发更强大、更可靠的AI系统指明了一条充满希望的道路。该框架不仅仅是提高准确率分数;它似乎诱导了LLMs处理数学问题方式的根本性“机制转变”。
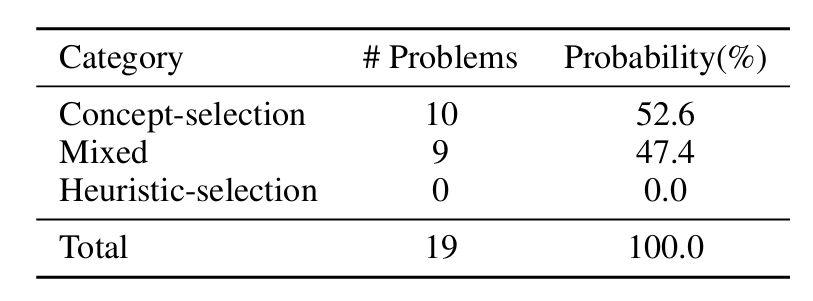
对CORE训练模型成功而基线模型失败的问题进行分析,揭示了一个清晰的模式。如表4详述,在这些案例中超过半数(52.6%被归类为纯概念选择),CORE模型在其推理中明确调用并正确应用了目标数学概念,而基线模型则没有。
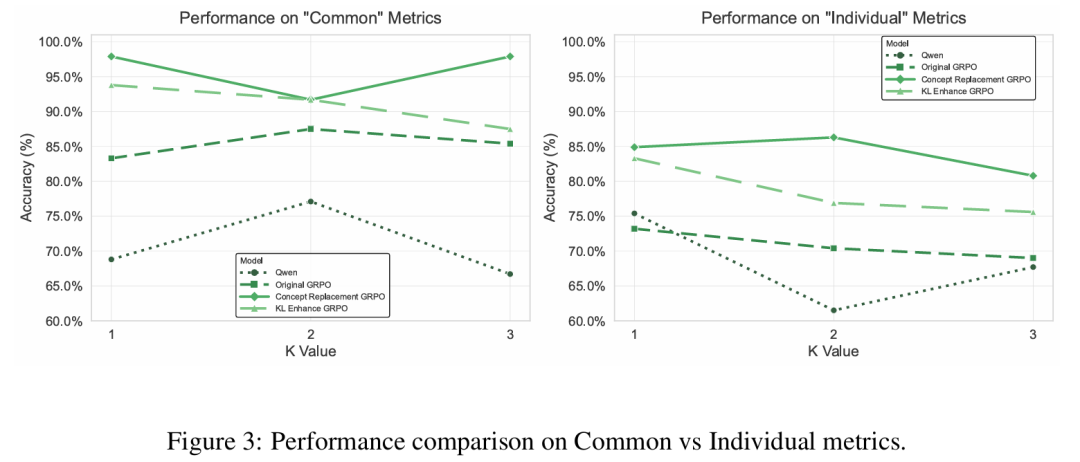
此外,CORE增强了LLMs的鲁棒性。在一项将无关的“干扰”概念附加到问题提示前的实验中,CORE训练的模型表现出显著更好的答案保持能力。图3中的性能曲线显示,CORE模型,特别是CORE-CR变体,对此类概念干扰具有更高的稳定性。
总之,CORE框架证明了将强化学习明确地建立在数学概念基础上,可以显著增强LLMs的推理能力。 通过超越粗糙的、基于结果的奖励,并提供细粒度的概念监督,CORE帮助模型从脆弱的模式匹配向真正的概念能力迈进。这项工作不仅为改进AI的数学推理提供了实用解决方案,也激励了在所有需要原则性、结构化推理的领域中对以概念为中心的训练进行更广泛的探索。
来源(公众号):AISignal前瞻




