实测|DeepSeek vs 阿里Qwen3,大模型问数到底哪家强?
视频简介
本次AI智能问数场景测试对比了DeepSeek和Qwen3等主流大模型的表现,各模型在响应速度和准确率方面展现出不同的性能特点。
视频内容
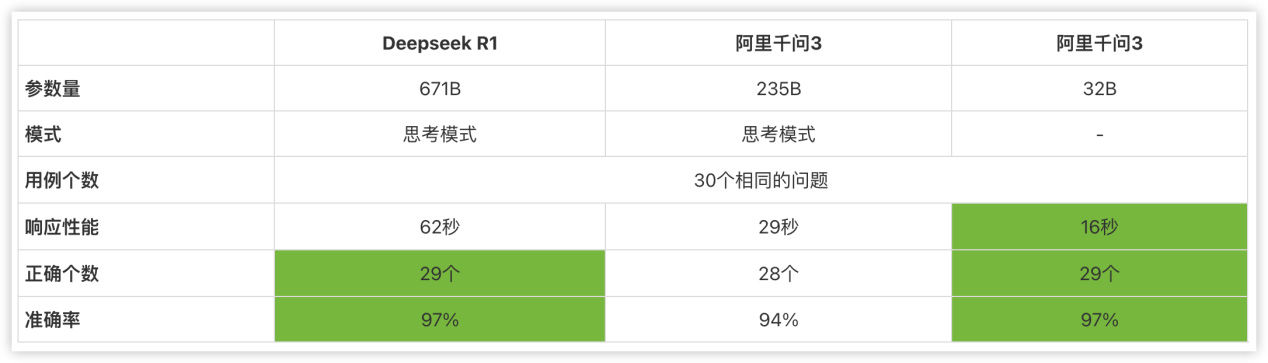
最近,我们针对AI智能问数场景,对比了DeepSeek R1和千问3这两个最热门的大模型。
DeepSeek R1满血版的平均耗时是62秒,正确率是97%。
Qwen3 235B模型的平均耗时是29秒,正确率是94%。
但Qwen 3 32B模型的平均耗时是16秒,正确率是97%。准确率与DeepSeek一致,但性能是DeepSeek的4倍。
所以,Qwen3 32B这个小模型完胜。
Qwen3 235B这个大模型多了一个不应该的错误,它使用开票金额当成成交金额,正确的应该是使用合同金额,惜败。
【图(1)】
测试环境说明:
1、测试环境:阿里云在线接口。
2、测试场景:某品牌CRM数据,包括客户、跟进记录、商机、合同、发票、收款等信息。
3、测试用例:30个(18个低难度、7个中难度、5个高难度)




