

每隔几个月,同样的架构争论就会再次出现:企业 AI 系统是否需要 RDF 和 OWL,还是属性图就足够了?
问题在于,这个问题本身就是错误的。
两者都以可预见的方式犯了错。
真正的问题不在于RDF/OWL是否比属性图更好,而在于:你要解决的是哪种语义问题?
如果你正在构建一个具有明确关系且需要快速遍历的单系统代理,那么属性图可能正是合适的选择。但如果你正在构建跨平台、受监管、可审计的代理工作流,并且系统之间需要就含义达成一致,那么形式化本体论就显得尤为重要。
本指南为架构师提供了一个结构化的决策框架——以生产部署为基础——并明确规定了正式本体何时能够证明其成本合理,以及何时会增加复杂性而没有相应的收益。
我们究竟在选择什么?
这场争论常常将不同层面的实施选择混为一谈。
RDF(资源描述框架)是一种数据模型:它由具有全局唯一URI的主语-谓语-宾语三元组组成,是W3C制定的链接数据标准表示方法。
OWL(Web本体语言)是一种用于RDF的模式语言。它允许您定义类、属性、关系,以及至关重要的推理规则。OWL推理器(例如Pellet或HermiT)可以推导出未显式存储的事实:如果AFxSpotContract是B的子类FinancialInstrument,推理器会自动推断出这种成员关系,而无需为每个实例显式存储。
SPARQL是 RDF 图的查询语言,相当于三元组存储的 SQL 语言。
SHACL(形状约束语言)是一种 RDF 词汇表,用于表达随数据一起传递的数据验证约束,而不是锁定在应用程序代码内部。
属性图(Neo4j、TigerGraph、Amazon Neptune)存储带有键值属性的节点和边。它们针对显式关系和操作遍历进行了优化。但它们并不提供 RDF/OWL 所设计的基于标准的语义模型、可移植的推理语义或全局共享的标识符规范。
问题不在于哪个“更好”,而在于它们是为了解决不同的问题而设计的。
影响决策的五个维度
1. 知识范围:单一系统与跨界
当您的知识仅限于单个应用程序、数据库或团队时,属性图就足够了。如果您拥有整个数据模型,属性图可以以极低的设置成本为您提供所需的一切。
当需要在组织或系统边界之间共享、比较或验证知识时,RDF/OWL 就变得至关重要了。
设想一个典型的企业采购环境。同一供应商同时出现vendor_id在ERP系统、party_ref合同管理系统、supplier_code发票平台和counterparty_id风险管理系统中。对于人工分析师而言,这只是日常的摩擦;而对于自主智能体来说,这却是一道难以逾越的障碍。
当你部署一个采购代理,需要验证供应商是否已获得合同批准才能发出采购订单时,你就是在要求它实时协调四个标识符、三个状态分类和两个“已批准供应商”的定义——而且没有人会注意到它何时连接错误。
“首选供应商”、“可寻址支出”、“合同价格”和“批准类别”等概念缺乏跨系统通用的定义。而RDF/OWL + SHACL则弥补了这一空白:本体只需定义Supplier一次,即可包含所有有效状态和约束。SHACL将这些约束表达为任何系统都能独立验证的形式。新加入工作流的代理导入本体,运行验证器,即可获知供应商是否符合共享定义。语义契约得以共享,集成工作量也随之减少。
2. 推理要求:存储的事实与推导的知识
这是大多数建筑师容易低估的一个方面。
属性图存储的是你输入的内容。添加一个新的子类后,你必须更新所有依赖于该层次结构的查询和应用程序。OWL 推理器会自动推断——你只需定义一次类层次结构,其含义就会自动在整个图中传播。
RDF/OWL 在以下情况下值得使用:
你需要发现其中存在的隐含矛盾(两个不可能同时为真的事实)。
您的域具有复杂的继承层次结构,并且会随着时间的推移而增长。
为了符合合规性或审计要求,您需要可证明的完整性。
属性图在以下情况下是正常的:
你需要快速遍历明确的、稳定的关系。
查询性能比推理完备性更重要
State Street GFRO 部署中使用了 Pellet(一个 OWL DL 推理器)进行工具层面的监管报告——因为这类报告需要完整性。基金层面的报告则使用参数化的 SPARQL,而没有使用完整的推理器,因为这类报告不需要推理的完整性。在需要完整性的地方使用推理器;在不需要完整性的地方则不使用。
3. 治理模型:应用所有制 vs. 数据可移植制
大多数属性图和专有平台部署都用作封闭式操作系统:平台决定哪些数据存在、哪些数据有效以及允许哪些操作。治理规则存在于平台逻辑、API、工作流定义或应用程序代码中。它们功能强大,但无法随数据一起流动。
RDF/OWL 提供开放的、基于标准的语义。SHACL 则通过可移植的验证机制对其进行补充。OWL适用于需要共享语义和推理的情况。SHACL 适用于需要可导出、版本化并由其他系统(包括发布机器可读要求的外部审计机构或监管机构)执行的数据质量约束的情况。
对于拥有复杂专有模型的平台而言,合适的框架在于:平台边界内的运维能力与跨平台边界的语义互操作性。两者都是合理的架构选择——问题在于你的多智能体设计实际需要的是哪一种。
4. 代理架构:单系统与跨平台协调
当一个平台上的AI代理将任务移交给另一个平台上的代理,而该代理又调用第三个平台上的工具时,认知协调机制并未建立。代理要么拥有共享的语义契约,要么做出一些会向下游传播的假设。
微软的 GraphRAG 研究(Edge 等人,2024/2025)展示了一种截然不同的方法:基于 LLM 的图结构。GraphRAG 并非预先定义模式,而是从非结构化文本中提取实体和关系,构建属性图,并利用莱顿社区检测将其划分为主题聚类。对于语料库级别的非结构化文本意义构建,GraphRAG 的性能显著优于传统的向量 RAG,其全面性胜率高达 72%–83%。
GraphRAG 和 RDF/OWL 并非对同一问题的相互竞争的答案。GraphRAG回答的是“该文档语料库的主题是什么?”,而 RDF/OWL 回答的是“该金融工具在我们五个源系统中是否符合巴塞尔协议 III 对一级资本的定义?”。第一个问题没有预先存在的模式;第二个问题则需要一个权威的模式。
5. 投资期限:短期速度与长期杠杆
RDF/OWL 确实存在前期成本:本体工程需要专门的技能,三元组存储的操作特性与关系数据库不同,而且 SPARQL 不如 SQL 常见。
属性图能让你更快地构建出可用的原型。Neo4j 的开发者体验远胜于任何三元组存储。
微积分发生变化的地方:
语义协调工作需要在多个源系统和团队之间重复进行——尤其是在添加新系统时。
数据质量溯源的外部监管要求
已建立的行业标准本体(金融领域采用 FIBO,医疗保健领域采用 SNOMED CT / HL7 FHIR,建筑领域采用 IFC)
跨组织或供应商边界运行的人工智能代理
在这些关键节点,RDF/OWL 的前期成本会分摊到所有使用该本体的系统中。道富银行团队向开放标准贡献了 62 个 FIBO 扩展——这项工作惠及所有符合 FIBO 标准的机构,而不仅仅是道富银行。
决策框架
首先,何时开始使用 RDF/OWL?

何时使用属性图谱 + API:

实践中效果最佳的混合模式
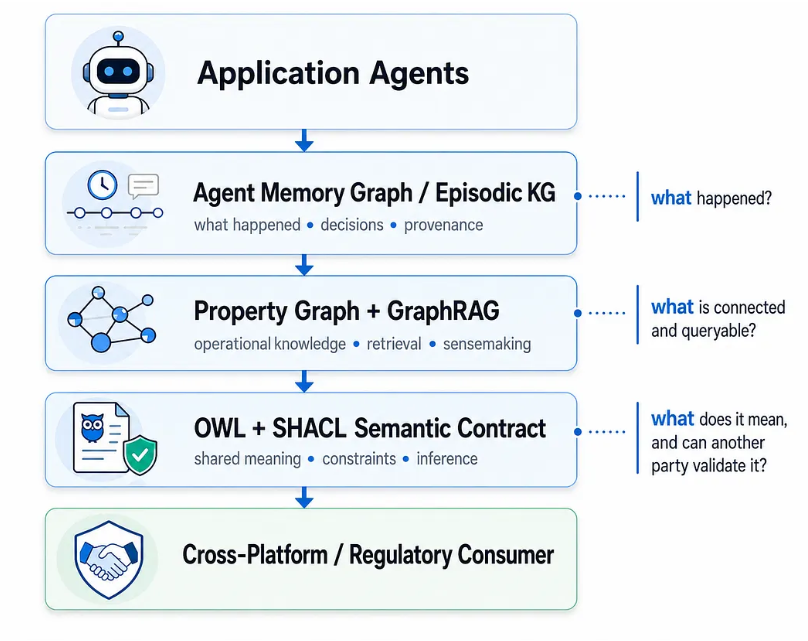
在设计良好的企业系统中,这两种方法都不会被全盘采用。生产部署倾向于采用三层架构,其中每种图类型都承担其擅长的任务:
智能体记忆图/情景知识图谱——捕捉智能体的行为、决策及其原因;具有双时态溯源性;决策轨迹作为一种不断累积的制度资产。图式在交互过程中涌现,而非预先设定。(类似Zep的框架在此发挥作用。)
属性图谱 + GraphRAG在操作知识层——显式参考知识、语料库意义构建、快速遍历以进行推荐和检索。在此,领域知识变得可查询。
OWL 本体 + SHACL在语义契约层——跨组织边界共享含义、类层次结构、在需要时进行形式推理、外部各方无需导入您的平台即可执行的可移植验证。
三种需要避免的模式
模式 1:过早的形式本体论
一个团队构建单租户内部知识库,却花了六个月时间进行 OWL 建模、SPARQL 端点设计和推理器调优——而属性图只需两周就能解决这个问题。当既不需要跨边界交换,也不需要推理时,形式化本体就毫无价值。
模式二:大规模的图谱蔓延
一个团队为一个用例构建了一个属性图,并将其扩展到另外五个用例,然后与三个外部合作伙伴共享——结果发现他们之间没有统一的URI方案,没有可移植的约束,也无法验证合作伙伴对节点的解释是否一致。每个新的集成点都需要定制的协调方案。成本不断累积。
模式 3:将平台级语义层误认为可移植语义标准
许多企业平台都自带所谓的“本体”——一种跨平台共享的语义模型,能够在其生态系统内良好运行。其实,它本质上就是一个平台级的语义层。它解决了同一厂商内部的集成问题,但无法解决跨厂商的互操作性问题。
如果没有 OWL 导出、SPARQL 访问或可移植的 SHACL 约束,平台级语义层就无法作为跨平台代理协调的语义标准。从外部加入的新代理必须调用源平台的 API 并信任其解释,才能对其进行验证。
关于为何这种差距持续存在,需要说明一点:对于拥有成熟语义模型的平台而言,实现可移植语义契约在技术上并不困难。但在平台经济中,谁拥有协调层,谁就能获得不成比例的价值——而可移植标准打破了这种依赖关系。历史模式一脉相承:可移植性只有在监管机构强制要求(例如医疗保健领域的 FHIR,金融领域的 FIBO)或企业买家将其作为采购条件时才会出现。在此之前,应将可移植性视为一项需要明确定义的架构需求,而不是供应商会主动趋同的特性。
总结
对于受监管的行业而言,跨组织边界运营,拥有长期存在的数据资产,需要由您无法控制的系统和代理进行一致的解释,因此 RDF/OWL 并非过度设计。
对于语义含义稳定、易于理解且永远不需要外部方验证的单团队、单平台部署来说,这样做是过度的。
属性图并非“精简版的RDF”。它们是一种不同的工具:操作速度快、开发人员操作方便、并且具有LLM友好的归纳结构。
企业人工智能的未来不在于选择哪个图论阵营,而在于了解何时需要推断含义,何时需要验证含义,何时需要传递含义,以及何时只需要快速查询。
来源(公众号):数据驱动智能




