

客户姓名一列,1,200 行是空的
手机号 4,000 多条缺失,800 多条明显是错的(8 位、12 位都有)
性别字段里出现了"M""F""男""女""未知""0"——六种写法,根本没法分组统计
数据接进来了,流转也正常,但问题是——数据本身是脏的,下游谁敢用? 这不是个别现象。很多团队建数据中台,精力全花在"能不能接进来"和"能不能跑通",很少有人关注"接进来的数据对不对"。等到业务部门真要用的时候,才发现数据只能看、不能用。
为什么传统质检方式不够用
常见的做法是两种。
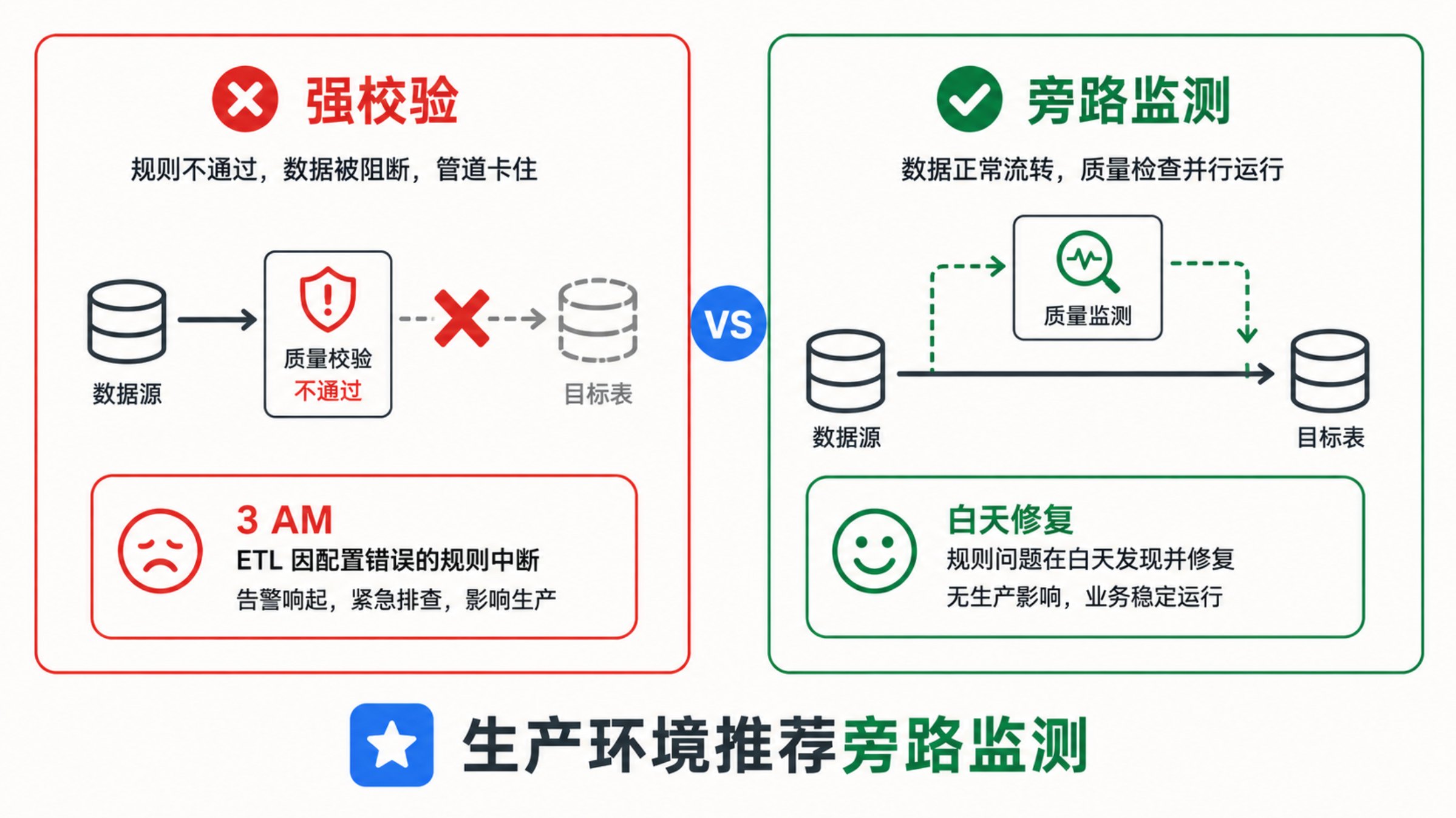
第一种,强校验。 在数据入库前做检查,不合格就拦截。逻辑上没问题,但实际项目里风险很大:一条字段格式的规则配错了,可能把整个管道卡住。凌晨三点的 ETL 任务如果因为一个质量规则报错而中断,运维会被电话叫醒——而且大概率是误报。
第二种,旁路监测。 数据正常同步,质量检查并行运行。发现问题后单独记录到问题库,不阻塞主链路。你可以在白天慢慢修复,不影响任何生产流程。
多数项目里,旁路监测比强校验更实际——这也符合 DAMA 数据管理知识体系中"数据质量管理应优先保障业务连续性"的原则。龙石数据中台的质量管理模块就是这么干的——用"评测模型"管规则,支持 MySQL、Oracle 到 Doris、GaussDB 等一堆数据库,配规则不用写 SQL。作为 DAMA 大中华区实训基地和信通院《数据治理产业图谱 3.0》入选厂商,龙石在这个领域已经有多个项目验证。
上手配置:从零搭建一条质量监控链路
拿最常见的客户基础信息表来跑一遍。customer_info 每天从 CRM 增量同步,要盯三件事:姓名和电话不能空、手机号格式得对、性别代码得在标准字典里。
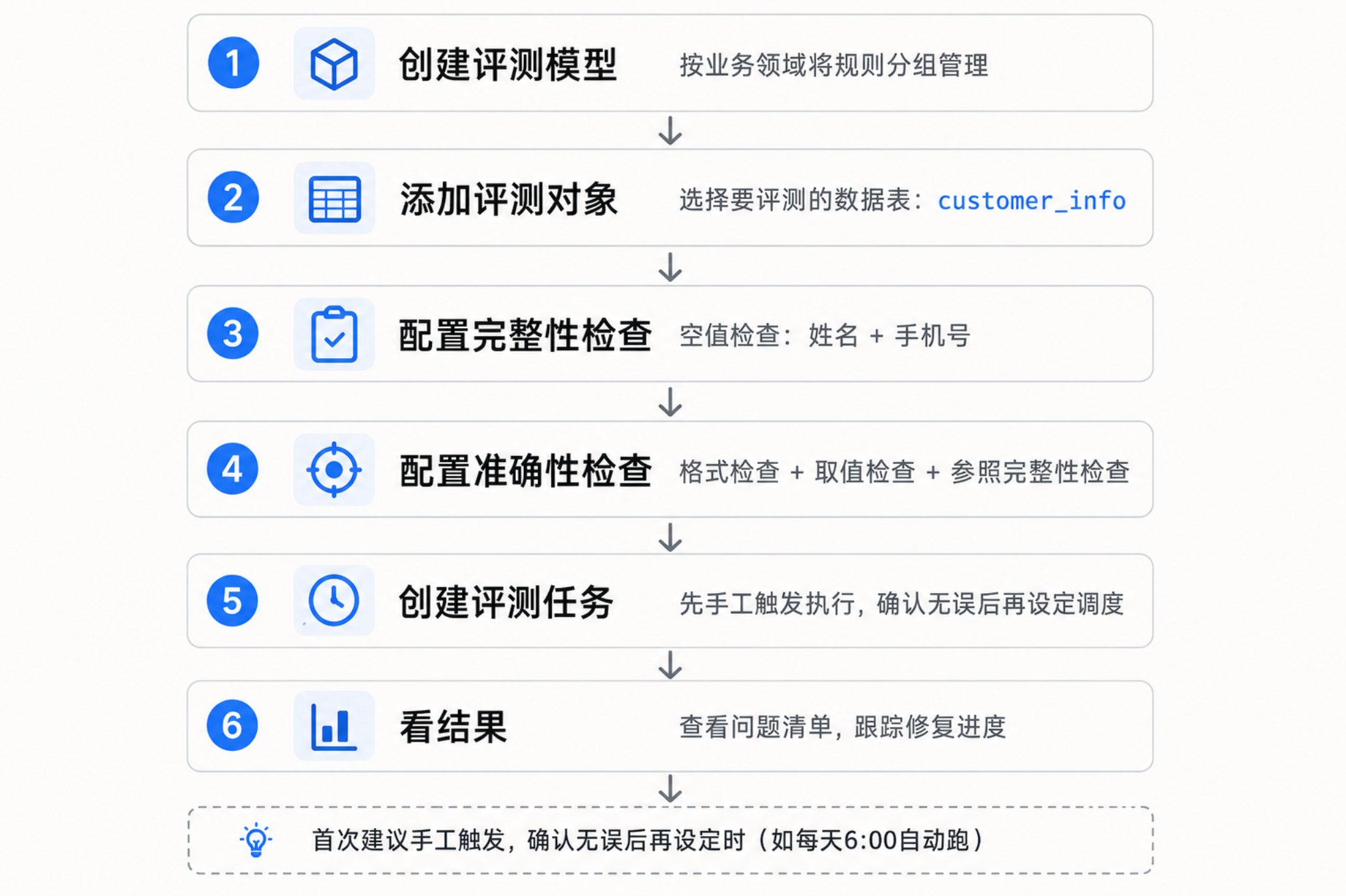
第一步:创建评测模型
评测模型就是按业务域把规则分组——客户域一个模型、产品域一个、订单域一个。进入「数据质量 → 评测模型管理」,点击新增,填写模型名称"客户信息质量评测",选择评测数据库为治理库(DW),保存。
第二步:添加评测对象
在模型详情页点击新增评测对象,选择 customer_info 表。如果表没有物理主键,需要指定一个逻辑主键来唯一标识每行数据,方便后续问题追溯。
第三步:配置完整性检查
最常见的问题是字段为空,比如客户姓名和电话缺失。新增一条「空值检查」规则:
| 配置项 | 填写 |
|---|---|
| 规则名称 | 客户姓名与电话非空检查 |
| 检查字段 | customer_name,phone |
| 检查方式 | 每个字段都不能为空 |
| 规则权重 | 高 |
| 错误描述 | 客户姓名或电话存在空值,影响标签生成和营销触达 |
| 修复建议 | 核对 CRM 客户基础信息是否完整录入 |
第四步:配置准确性检查
字段有值不代表值是对的——手机号是 11 位的吗?年龄在合理范围内吗?性别代码是标准值吗?
格式规范性检查(手机号格式): 规则类型选「格式规范性检查」,检查字段选 phone,EL 表达式写 #phone REGEXP '^1[3-9][0-9]{9}$'。不符合 11 位手机号格式的,自动标记。
值域检查(年龄范围): 规则类型选「值域检查」,检查字段选 age,值域范围设为介于 0 和 120。超出这个区间的数据会被捕获。
引用完整性检查(性别代码标准化): 规则类型选「引用完整性检查」,检查字段选 gender。前提是数据标准模块里已经定义了"性别代码"字典表(M=男/F=女),质检规则直接引用标准定义,不需要重复维护值域。标准改了,规则自动同步。
第五步:创建评测任务
规则配好后,需要建一个评测任务来触发执行。进入「评测任务管理」,选择"客户信息质量评测"模型。首次建议用"手工触发"先跑通验证,确认规则无误后再改为定时策略——比如每天早上 6 点自动跑。
第六步:看结果
任务执行完成后,进入「问题数据查看」。首次扫描 86 万条客户数据,通常能看到类似这样的结果:
| 问题类型 | 数量 | 占比 |
|---|---|---|
| 手机号缺失 | 4,200 条 | 0.49% |
| 客户名称缺失 | 1,200 条 | 0.14% |
| 手机号格式异常 | 800 条 | 0.09% |
| 性别编码不在标准范围 | 3,500 条 | 0.41% |
| 合计问题率 | 1.03% |
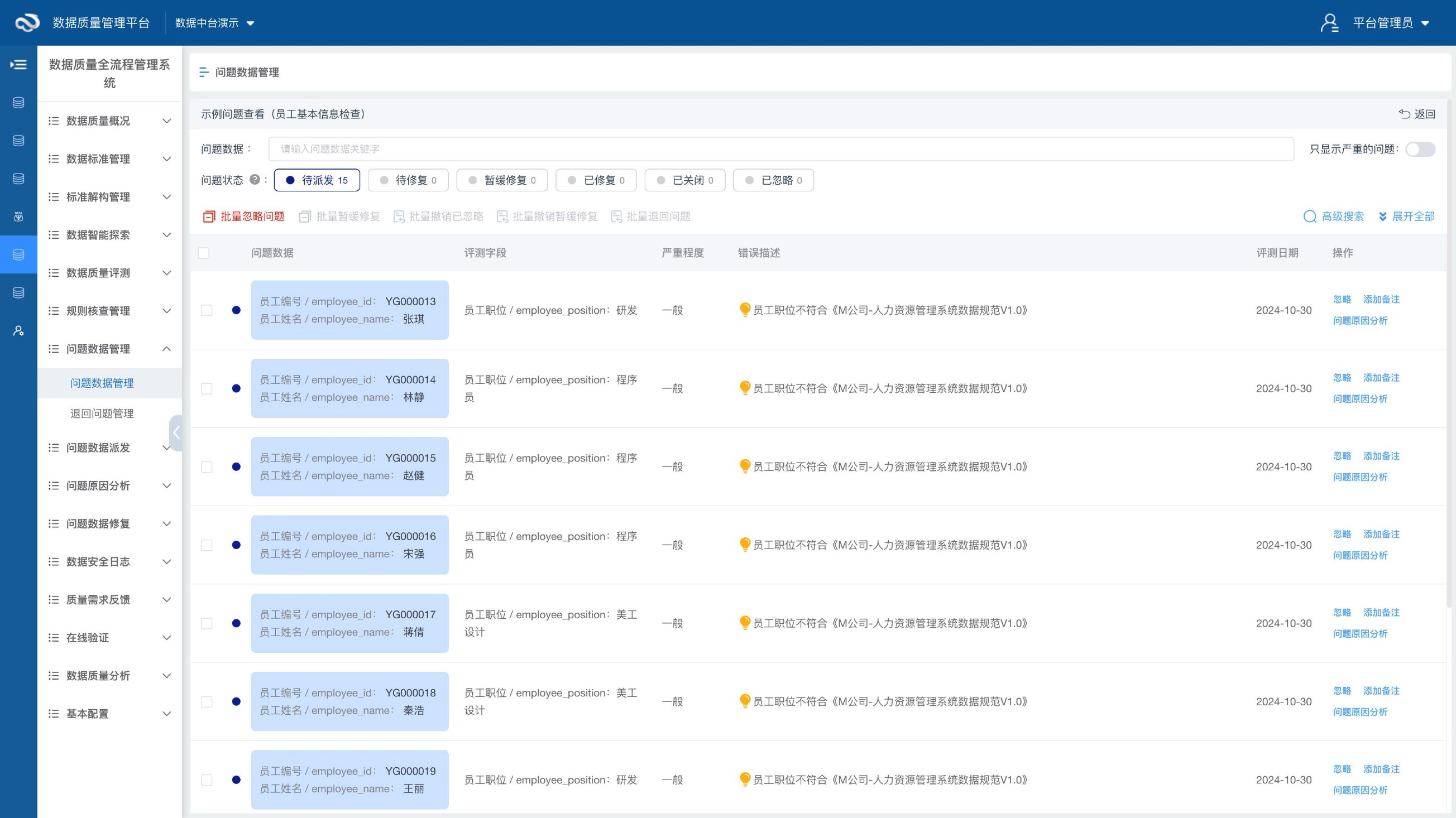
每条问题都能点开看详情——哪个字段、违了什么规则、当前是啥值、什么时间发现的。修好之后下次跑评测,问题状态自己就关了。
项目里最容易踩的 4 个坑
坑一:规则越多越好。 不是。第一次做数据质量的团队,上来就配几十条规则,觉得覆盖面越广越好。结果每天几千条告警涌进来,没人看得完,也没人处理。两周之后,所有人把告警通知关了。正确做法:从一个核心业务域开始,先配 3-5 条高价值规则,等团队习惯了处理节奏,再逐批加。规则不在多,在有人盯。
坑二:把低价值字段当核心字段。 手机号缺失,值得告警——影响短信触达。备注字段为空,不值得——本来就可空。但很多项目里两者权重设成一样,重要问题淹没在一堆"备注为空"里。区分方法很简单:问自己"这个字段如果错了,下游哪个业务会受影响?"答不上来的,就设低权重或者不配。
坑三:一上来就设定时任务。 评测任务刚建好就设定时,凌晨自动跑——听起来很规范。现实是:第一条规则配错了,半夜产生几千条误报,没人发现,第二天打开系统直接懵了。正确做法:先手工触发跑一次,对着问题清单一条条确认"这是真问题还是误报",确认规则没问题了,再切定时策略。
坑四:错误描述技术部门都看不懂。 见过一个真实案例:规则错误描述写的是"phone 字段不满足 EL 表达式 REGEXP"。业务部门看不懂,技术部门看不出业务影响,这条告警在两个部门之间转了三天没人认领。错误描述应该回答三个问题:什么问题(业务语言)、影响什么(下游场景)、怎么修(可操作的步数)。比如别写"gender 不在值域范围",写"性别字段存在非标准值,影响客户画像分组统计,请在数据标准模块确认标准字典后批量修正"。
真正难的不是发现问题,是把问题推回去
项目做久了会发现一个规律:大部分质量问题并不是系统故障造成的,而是业务过程产生的。客服录入时图省事,手机号随便填。老系统迁移时历史数据没清洗,脏数据原封不动搬过来。ERP 和 CRM 对"客户类型"各有各的编码规则,合到一起全乱了。质量规则能扫描出来的,只是冰山浮在水面上的部分。
更棘手的是:你标记了 4,000 条手机号缺失,谁来补?客服部说"这是历史数据,不是我录的",IT 说"数据已经同步完了,源系统不改我们也没办法"。一圈下来,问题清单躺了一个月没人动。
所以旁路监测真正的价值,不是发现问题——发现很容易,配几条规则就够了。真正的价值是给一个持续推动的抓手:每周把问题清单按来源系统分类,谁产生的谁认领。一次不行两次,两次不行拉上业务负责人一起看数据。质量管理要解决的不是一次性清洗,而是让问题回到业务源头的能力。
常见问题
Q1:旁路监测会影响数据同步性能吗? 一般不会。质量评测是数据同步完之后另外跑的,跟主链路不打架。头一回跑的时候留意下耗时,千万级往上的大表可以用分区评测或者增量评测,别一次扫全表。
Q2:发现问题数据后,系统会自动修复吗? 不会。质量管理的任务是发现问题和推动治理,不是直接改业务数据。问题数据进问题库,标清楚哪条记录、谁负责、怎么修。等业务侧改好了,系统会自动把这条问题关掉。
Q3:什么时候用旁路监测,什么时候用强校验? 不冲突。身份证号、统一社会信用代码这种核心交易数据,强校验合适。客户信息、设备信息、业务标签这些,用旁路监测更稳——别因为几条破数据把整个流程卡了。
Q4:质量规则应该一次性全部配完吗? 别。先盯核心字段,把 80% 的高价值问题干掉,跑顺了再慢慢加。上来就全配,告警多到自己都不想看。
Q5:数据质量问题主要来自哪里? 很多团队第一反应是同步任务出了问题。其实大部分质量问题是业务侧搞出来的:录入的时候图省事、老系统迁移过来的脏数据没洗、不同系统对同一个字段各有各的编码。所以数据质量治理,治的不是数据,是业务过程。
很多人以为数据质量就是上线前集中洗一轮,洗完就干净了。实际上数据质量跟产线质检差不多——每天都有新料进来,质检得一直跑着,不是搞一次就收工。
评测模型和定时任务搭好之后,每周扫一眼问题修复率就行。主要看三样:问题数是在涨还是在降、高权重问题从发现到关闭用了几天、新接的数据源有没有同步建质检规则。
说到底,数据质量不是要把所有问题都干掉——那不可能。是得有一个"一直在查、查出来有人修"的机制。旁路监测做的就是这件事。




