

"我们中台搭了快两年,ERP和MES的数据到现在还没跑通。"
这话来自一家制造业企业的CDO,说的时候他苦笑了一下。不是缺工具——Kettle、DataX都在用,开发团队也不弱。问题是每接一个新系统,光接口适配就要耗掉半个人月,而且"接完只是开始"——数据对不上、字段含义靠猜、出问题不知道从哪追。
这不是个例。在参与过的项目中,异构数据集成几乎每次都是中台建设的第一道坎,也是耗时最长的一道。
一、不是技术不够,是"接不住"
首先是数据源类型多。数据库不只是MySQL,还有Oracle、SQL Server、PostgreSQL,不同版本接口行为各异。加上API对接的SaaS系统、文件交换的遗留系统、消息队列流转的实时数据——一个企业少则三五套系统,多的十几套。然后是对接技能要求高。ERP里的"客户名称"、CRM里的"客商名称"、财务系统里的"往来单位",指向同一个东西,但集成人员得一个一个去对应。这还只是一个字段。实际情况是,一个核心业务表可能有几十上百个字段,全靠人工逐个映射,工作量极大。
江苏某自动化制造企业在建设数据中台时,光是把ERP、PLM、MES、SCADA、质量系统五套核心业务系统打通,就花了好几个月。不是技术方案复杂,而是各系统的数据字典差异太大——同样的"订单号",在不同系统里长度、格式、含义都不完全一致。
二、接进来了,然后呢——三个根因
数据集成常见的困境是:第一阶段把数据接进来了,以为大功告成,但很快发现接进来的数据用不了。这才是真正的问题。
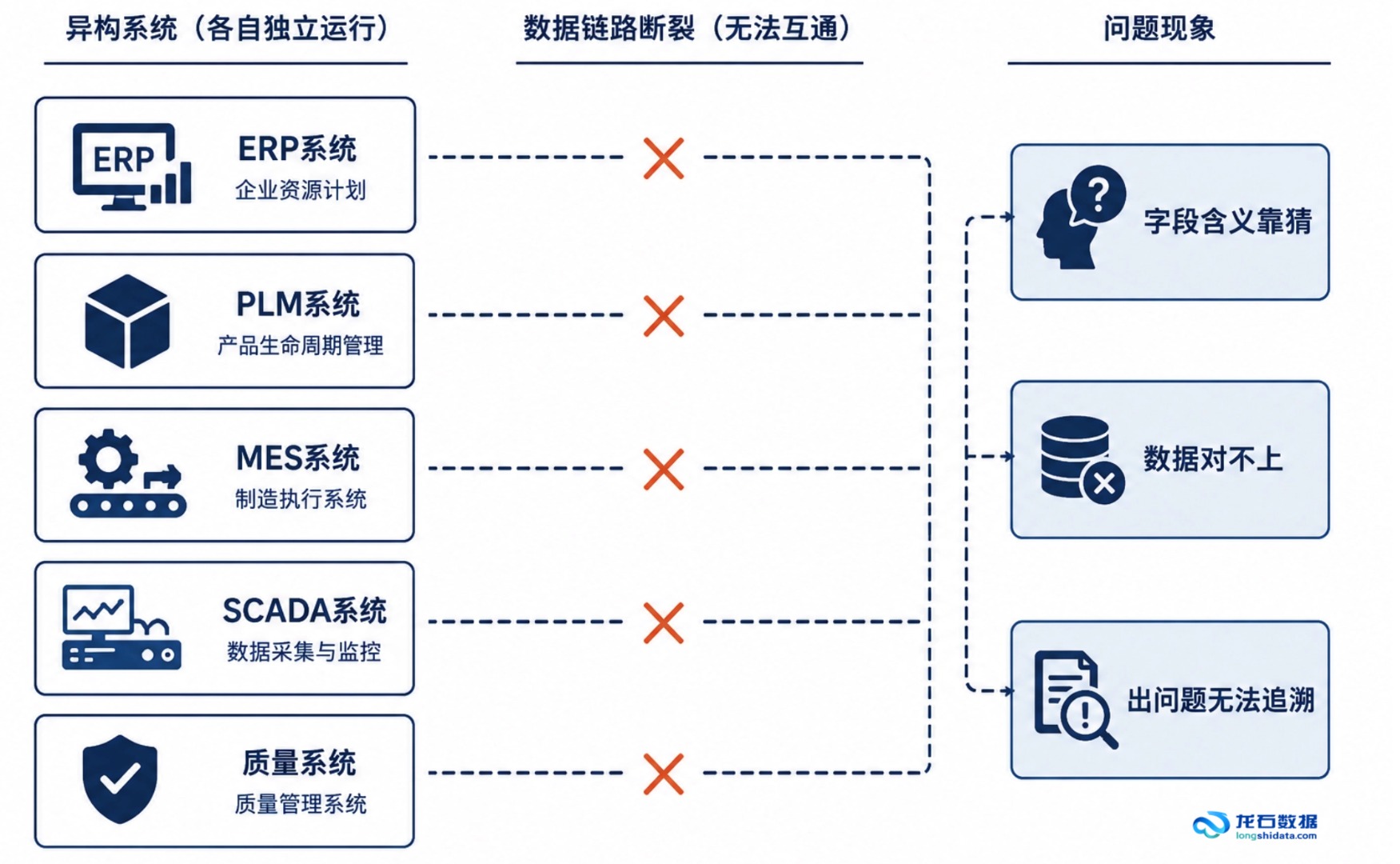
根因1:标准前置缺失,映射全靠人工
如前所述,字段名称不统一只是表层。更深层的问题是缺乏统一的数据标准体系——字段的业务含义、格式规范、取值范围、编码规则,如果不在集成前定义清楚,集成就变成了"硬接"。[1]
某跨区域运营的多元化产业集团旗下覆盖多个业务板块,同一个物料在不同板块间能有三种叫法,同一个供应商在多个业务系统中有独立编码。在没有统一主数据标准的情况下做集成,数据汇聚之后口径打架,报表分析全是错的。跨板块对账需要数天,数据纠纷常年不断。
根因2:元数据不跟进,血缘一片空白
比字段映射更隐蔽的问题是元数据缺失。很多人理解的集成就是把数据从一个系统搬到另一个系统——但搬的过程做了什么转换?原始数据是什么?被谁在哪一步改过?这些信息如果没有记录,后续出了任何问题都无法溯源。
没有元数据管理的数据中台,就像一个没有库存清单的仓库:东西都放进去了,但不知道放了什么、从哪来的、什么时候入库的、有没有被人动过。数据量的增长反而加剧了混乱——仓库越大越找不到东西。
根因3:质量校验缺位,数据进来了却没人管质量
这是最典型却最容易被忽略的问题。集成只管"搬",搬完之后数据对不对、全不全、重不重——没人检验。字段缺失、格式错误、逻辑矛盾这类问题在集成阶段没有被发现,等业务部门用数据做分析时才发现结果离谱,回头追溯已经过了好几手。[2]
江西某国控集团在建设中台前,10余套业务系统的数据缺乏统一的质量管控——财务数据填报错误、投资项目信息缺失、指标口径不一致,监管决策的依据本身就不可信。这些问题不解决,集成的数据越多,错误放大的范围就越大。
三、四个常见误区
误区1:把集成当纯技术活。 认为选对工具就能搞定——DataX不行换Kettle,Kettle不行换Flink。但实际上异构数据集成的瓶颈不在传输性能,而在业务语义的对齐。没有数据标准的集成工具,就像一个翻译软件只懂语法不懂语境。
误区2:等全接完了再治理。 不少团队的思路是先把所有系统的数据汇聚进来,后面再统一治理。问题在于,数据一旦入库,错误就会随着下游任务扩散——等发现的时候已经分不清哪些数据是干净的、哪些经过了污染。集成和治理更适合并行推进,而非先后串行。
误区3:追求"一键接入"。 任何做过系统对接的人都明白,现实中没有真正的一键接入。每个系统都有自己的历史包袱和业务特殊性,对接过程必然需要业务人员参与确认语义、校验口径。工具可以减少重复劳动,但不能替代业务对齐。
误区4:忽视元数据。 规模越大越需要元数据。如果不知道数据从哪来、谁改过、给谁用,数据中台很快就会变成一个巨大的"黑箱"——所有人都在往里放数据,没有人知道里面到底有什么。
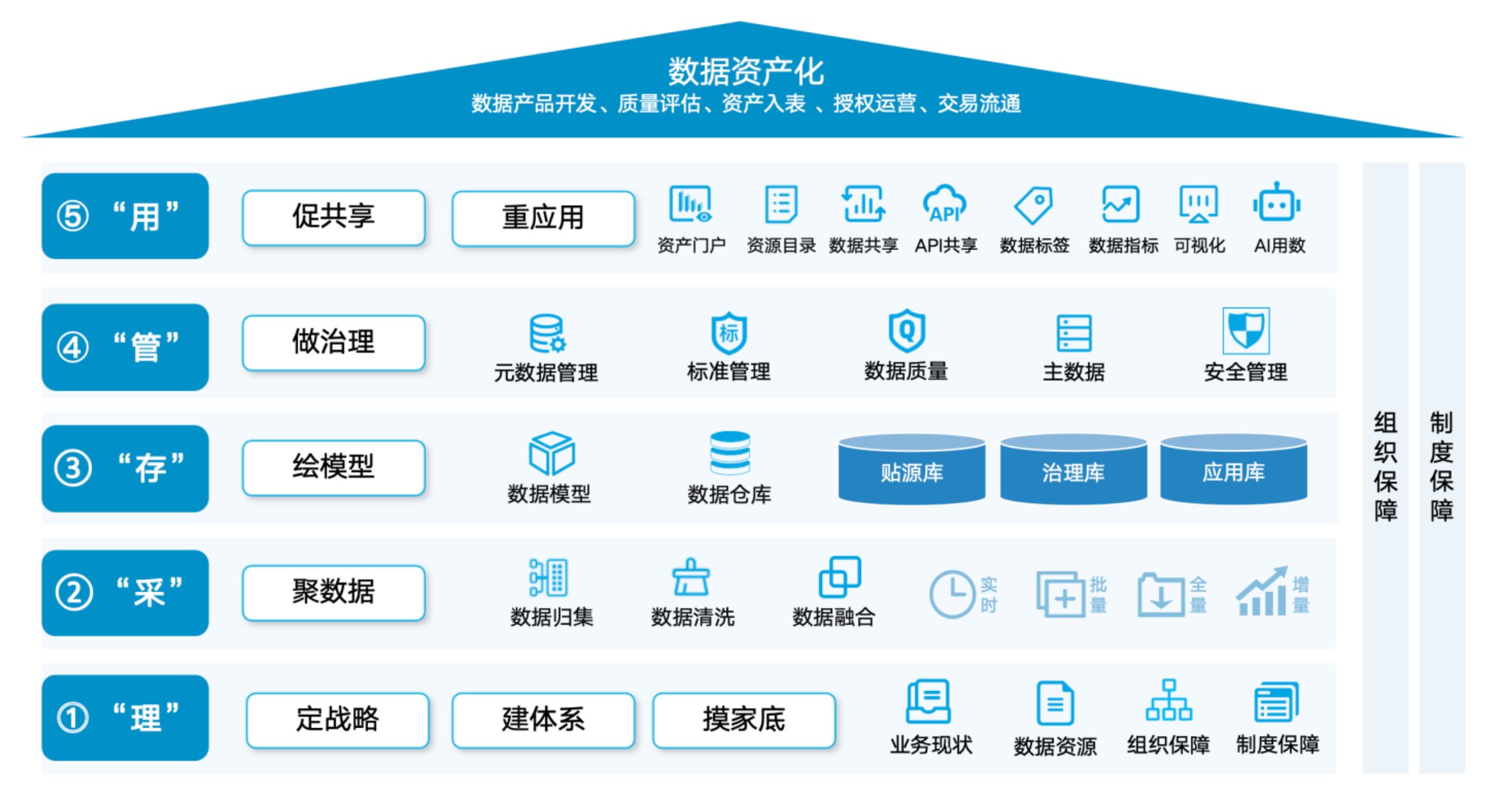
四、解决路径:集成与治理并行
核心思路一句话:数据的采集和治理不是先后关系,而是并行关系。[3]
数据集成负责归集,不拦截数据。 数据中台通常不建议在采集链路中修改或拦截数据——数据原样入库是行业实践中较为稳妥的做法,便于后续审计追溯。如果在采集链路里做格式转换或校验阻断,出了问题难以排查:是源端数据本来就有问题,还是中间转换环节改了数据?
治理在入仓后立即启动。 数据进入中台后,数据标准模块做字段到业务语义的映射对齐——不是在采集链路中硬性转换,而是在治理层建立标准与源数据的对照关系。同时元数据自动采集,让每张表、每个字段都有来源、有去向、有变更记录。
质量管控用旁路监测模式。 这是关键。质检规则不对数据入库做任何拦截——数据正常入库,质检任务并行扫描,发现问题后打标记、发告警、生成整改工单,定位到具体表、具体字段、具体记录。比如你发现某张订单表的"客户名称"字段有300条缺失,系统告诉你是哪300条,而不是阻塞整张表不让入库。这种模式既保证了数据流转的效率,又确保了质量问题可发现、可追溯。
质量前置是可选的增强做法。 如果你想更早发现问题,可以在集成前对源端数据做一轮检测——摸清源系统数据的质量底数,有问题的先让源头系统修复再进入中台。这不是必需的步骤,但对数据质量要求高的场景非常有效。
五、实践中怎么落地
江苏某面料贸易企业在做数据集成共享时就采用了这样的思路。这家企业的PLM、ERP、MES、外贸订单、仓储系统各自为政,跨境工厂数据割裂。他们没有追求一步到位,而是先解决核心链路——把订单相关的数据通路打通,同时部署数据标准管理统一字段口径,用质量规则持续监控数据完整性和一致性。系统间数据开始自动流转后,跨境业务协同效率显著提升。
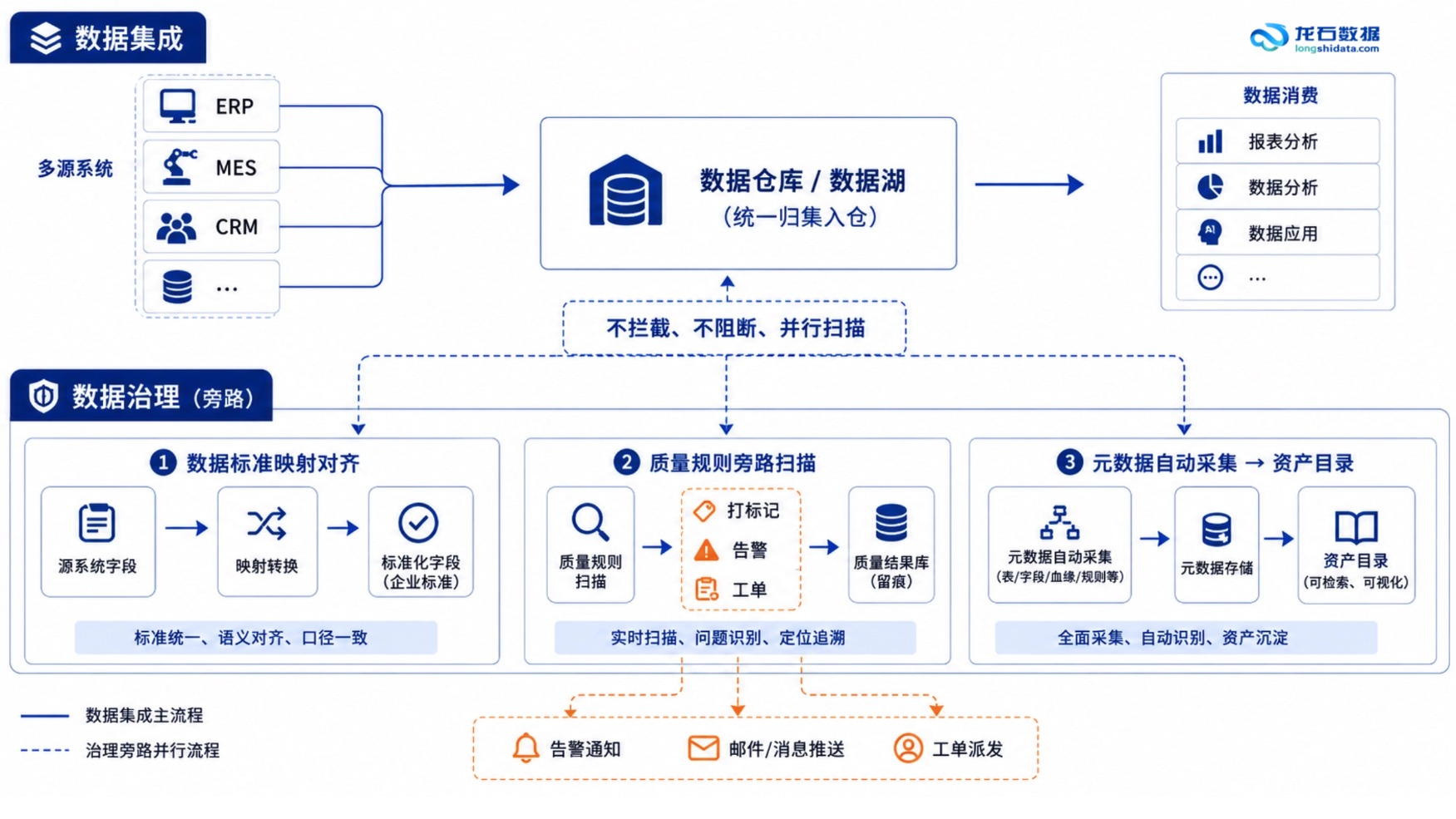
这种做法和龙石数据中台的产品逻辑是一致的:数据通过集成模块归集后,数据质量模块以旁路监测方式对入库数据做质量扫描——不需要改采集链路,质检规则可视化配置,发现问题自动告警。标准管理模块统一数据口径,元数据自动采集构建血缘,资产目录让数据资产可查可用。也可以在数据进中台前,先对源端做一轮质量检测,复核数据质量修复效果。
简单说就是八个字:数据照进,质量并行。
六、常见问题
1. 我们已经有了ETL工具,还需要数据中台的集成能力吗?
工具能搬数据,但不能管数据。中台的价值不在"搬",而在搬完之后——数据质量有没有保障、标准是否统一、血缘能不能追溯。如果只是想先摸清手头数据质量到底怎么样,龙石数据质量管理平台社区版免费可用,一行命令部署十来分钟就能跑起来,先做一次数据体检。
2. 异构数据集成的最大成本在哪里?
不是工具采购,是人力和时间。每个新系统的字段映射需要业务人员参与确认语义,这无法自动化。统一数据标准能从根本上降低每次集成的对接成本。
3. 实时集成和批量集成怎么选?
看业务需求。监管报表可以T+1生成,但订单交付状态追踪需要准实时。关键是中台要能同时支持两种模式,而不是二选一。
4. 集成完数据后发现质量不行怎么办?
这正是旁路监测要解决的问题——数据正常入库,质检规则并行扫描,发现问题定位到具体表、具体字段、具体记录。可以打标记、发告警、生成整改工单,而不是简单粗暴地拦截入库。
参考来源
[1] 国家标准化管理委员会,《数据管理能力成熟度评估模型》(GB/T 36073-2025,DCMM 2.0),




