

"我们数据中台已经跑了两年多,但今年启动的AI项目还是在数据环节反复翻车——数据质量不过关、元数据缺失、跨系统的字段对不上。我明明有中台,为什么AI还是用不起来?"
这是今年初一家制造企业CDO在行业闭门会上的困惑,当场引发了一圈共鸣。数据中台建设的浪潮过去后,一个尴尬的现实浮出水面:平台搭好了,数据也确实在跑了,但离"AI就绪"还差着一大截。
一、三股力量正在重塑数据中台
政策端的推动已从鼓励走向倒逼。国家数据局"数据要素×"三年行动计划(2024—2026年)[1]进入收官年,财政部《企业数据资源相关会计处理暂行规定》[2]已施行两年,数据资产入表从试点走向扩面——企业不再被"建议"把数据管好,而是被"要求"把数据当资产管。当数据要上资产负债表,中台就不只是技术平台,而必须成为能支撑数据确权、估值、质量验证的资产管理基础设施。
标准端的演进同样在提速。DCMM 2.0(GB/T 36073-2025)[3]将能力域从8个扩展为9个,新增"数据资产"能力域——这是一个信号:数据管理能力的评判标准已从"有没有治理"升级为"能不能资产化"。企业对标DCMM时,不再只是盘点元数据和数据质量,还需回答"你的数据资产在哪里、值多少、能不能用"。
技术端的推力最为直接。Data-Centric AI 的理念[4]在过去两年被反复验证:与其花80%精力调模型参数,不如花80%精力提升数据质量——因为AI效果的上限取决于数据,而不是算法。当企业发现花了几百万调优的大模型,在实际业务场景中的表现还不如一个治理到位的中小模型时,数据治理在AI战略中的优先级自然被重新排列。
二、中台建好了,为什么数据还没"AI就绪"?
回到开篇那个CDO的困惑。问题的根源不在平台本身,而在于大多数数据中台在建设时,数据治理被当成"附加模块"而非"默认配置"。
第一个症结:治理是"事后追认"。 典型场景是:平台先搭起来,数据先接进来跑起来,等业务反映"数据不对"了,再回头补标准、补质量规则、补元数据。事后的治理本质上是在给已经流转的数据"打补丁"——打上了还好,打不上的就变成技术债。而当AI项目启动时,这些债集体到期:训练数据中夹杂着不同口径的字段、缺失的元数据让模型理解不了业务语义、跨系统的数据不一致让AI输出互相矛盾。
第二个症结:管和用是两条平行线。 在很多企业里,数据治理团队和AI团队各自为战。治理团队产出的数据标准文档、质量报告、资产目录,AI团队看不到也用不上;AI团队从数据湖里直接拉原始数据训练,治理团队不知道他们在用什么数据、数据质量如何。两个团队用同一套数据底座,却活在两个信息孤岛里。
第三个症结:组织认知仍然滞后。 不少企业仍然把数据中台当作一个IT项目来管理——上线验收、结项归档、团队解散或转岗。但数据中台本质上是一个持续运营的能力平台,不是有明确终点的工程项目。当组织机制没有跟上——没有数据管理部、没有常态化的质量巡检、没有人对"数据资产健康状况"负责——中台建得再好,也只是一个技术空壳。
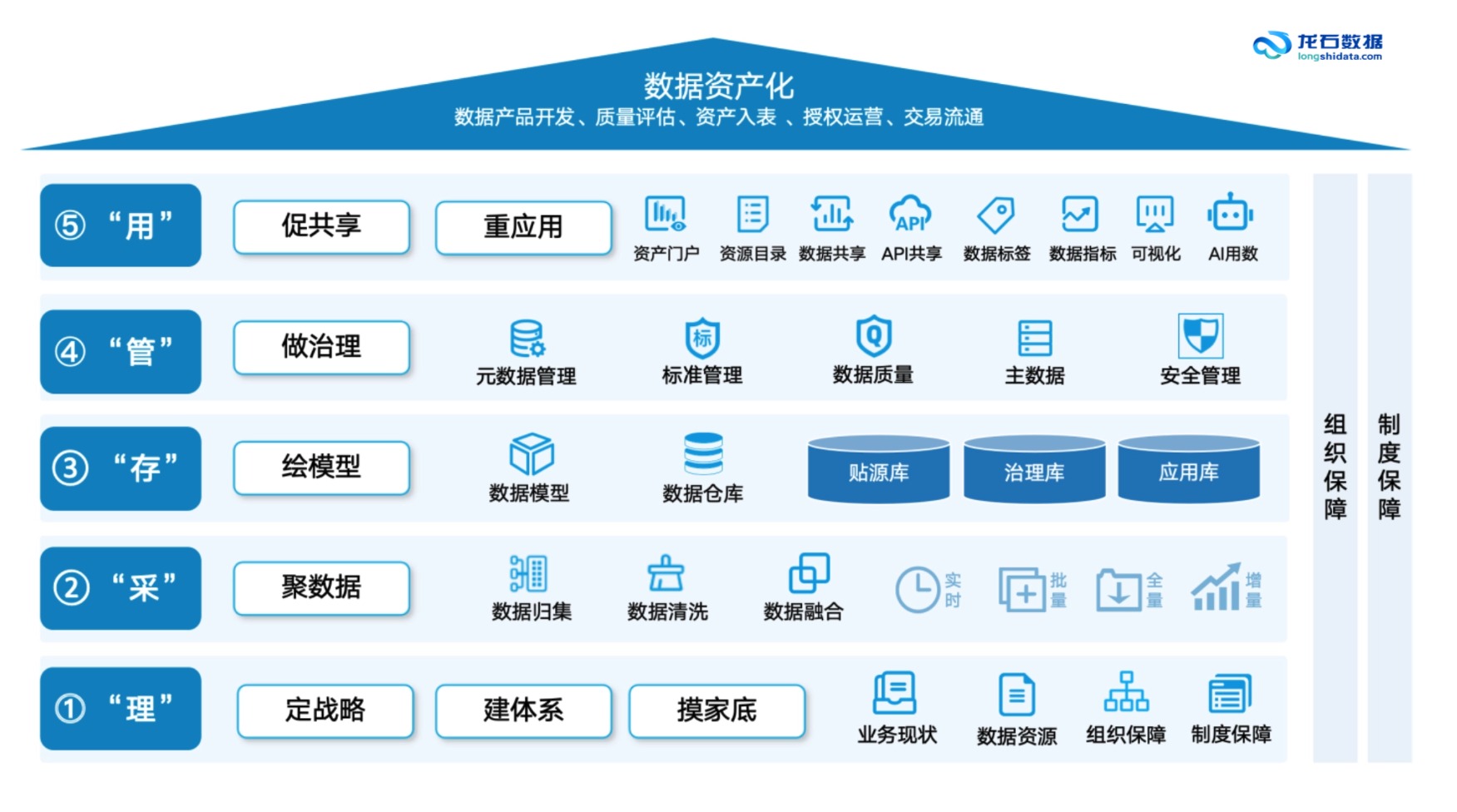
三、2026年的三个趋势深化
在上述挑战的倒逼下,数据中台正在经历一轮深层次的演进。不是功能列表的扩充,而是架构逻辑的重构。三个趋势方向正在从概念走向常态。
趋势一:AI原生——治理能力嵌入AI pipeline
过去两年行业逐渐达成一个共识:数据治理不是AI上线前的"准备工作",它应该是AI基础设施的一部分。
传统的思路是"先治理再AI"——先花半年把数据标准建好、质量拉上来、元数据补全,再启动AI项目。这套逻辑在纸面上说得通,在实践中往往走不通:半年后业务需求变了,治理的优先级被重新调整,AI团队等不了那么久。
2026年更务实的路径是"治理即AI基础设施"——不是治理完了再给AI用,而是在AI用数的过程中,治理能力实时生效。具体来说:元数据管理不只是给数据管理员看的目录,而是AI理解数据含义的前提——"这个字段叫'客户名称',但在ERP里指签约主体,在CRM里指联系人",没有元数据层,AI永远读不懂数据。数据标准不只是规范文档,而是AI跨表关联的"翻译层"——当ERP的"订单状态"是数字编码、CRM的"订单状态"是中文描述时,标准层负责统一语义,让AI能正确关联。数据质量管理不只是出质检报告,而是AI输出可信度的基础——模型给出的分析结论是否可靠,取决于输入数据的质量水平。
这不是理论推演。Data-Centric AI 的研究和实践反复验证了一个朴素逻辑:在数据治理上投入的每一分精力,最终都会在AI效果上体现出来。
趋势二:数据编织——从"集中式仓库"到"智能编排层"
数据中台在很长一段时间里被理解为一个"超级数据库"——把所有系统的数据都搬进来、存起来。但在企业系统日益复杂、数据量持续膨胀的背景下,"全量搬迁"的成本和时效越来越难以承受。
数据编织(Data Fabric)的理念为这个问题提供了新思路:不要求所有数据物理集中,而是通过元数据自动发现、虚拟集成、智能编排,在逻辑层打通异构数据源。对于数据中台而言,这意味着从"存数据"向"连数据"的范式升级——不是所有数据都要进中台的仓库,但所有数据都应在中台的治理视野内。
落到"理采存管用"框架里,这个变化是根本性的。"采"不再只是物理归集,还包括虚拟接入和联邦查询;"存"不再追求全量存储,而是智能分层——高频热数据本地化、低频冷数据按需获取;"管"的治理规则需要在逻辑层覆盖所有数据源,而不仅仅是中台内部的数据。
趋势三:"理采存管用"从串行流水线走向智能飞轮
"理采存管用"作为数据治理的工程落地框架,过去常被理解为五步串行:先理清家底、再把数据采进来、存好、管住、最后用起来。但在2026年的语境下,五个环节之间的关系正在被重新定义。
它不再是一根接力棒,而是一个相互驱动的闭环飞轮。"理"的产出——数据资产目录——直接成为"用"的起点,让AI用数智能体有据可依。"用"过程中发现的质量问题和数据缺口,自动反馈到"管"的质量规则迭代和"采"的接入策略调整。"存"的数据模型设计,为"用"的智能分析提供业务语义层。五个字之间是双向的信息流,而不是单向的接力传递。
这个转变的关键在于:数据中台从"工具集成"走向"智能驱动"。不是把采集、存储、治理、服务的工具集成到一个平台上就算完成,而是让治理逻辑在数据流转的每一个环节实时生效、自动反馈、持续优化。以市场上已有的部分产品(如龙石数据中台)为例,其"理采存管用"方法论已从概念框架落地为产品模块间的自动化贯通——标准规范驱动采集策略、资产目录驱动共享服务、质量规则在数据流转中旁路并行扫描,五个环节之间的信息流动不再依赖人工衔接。
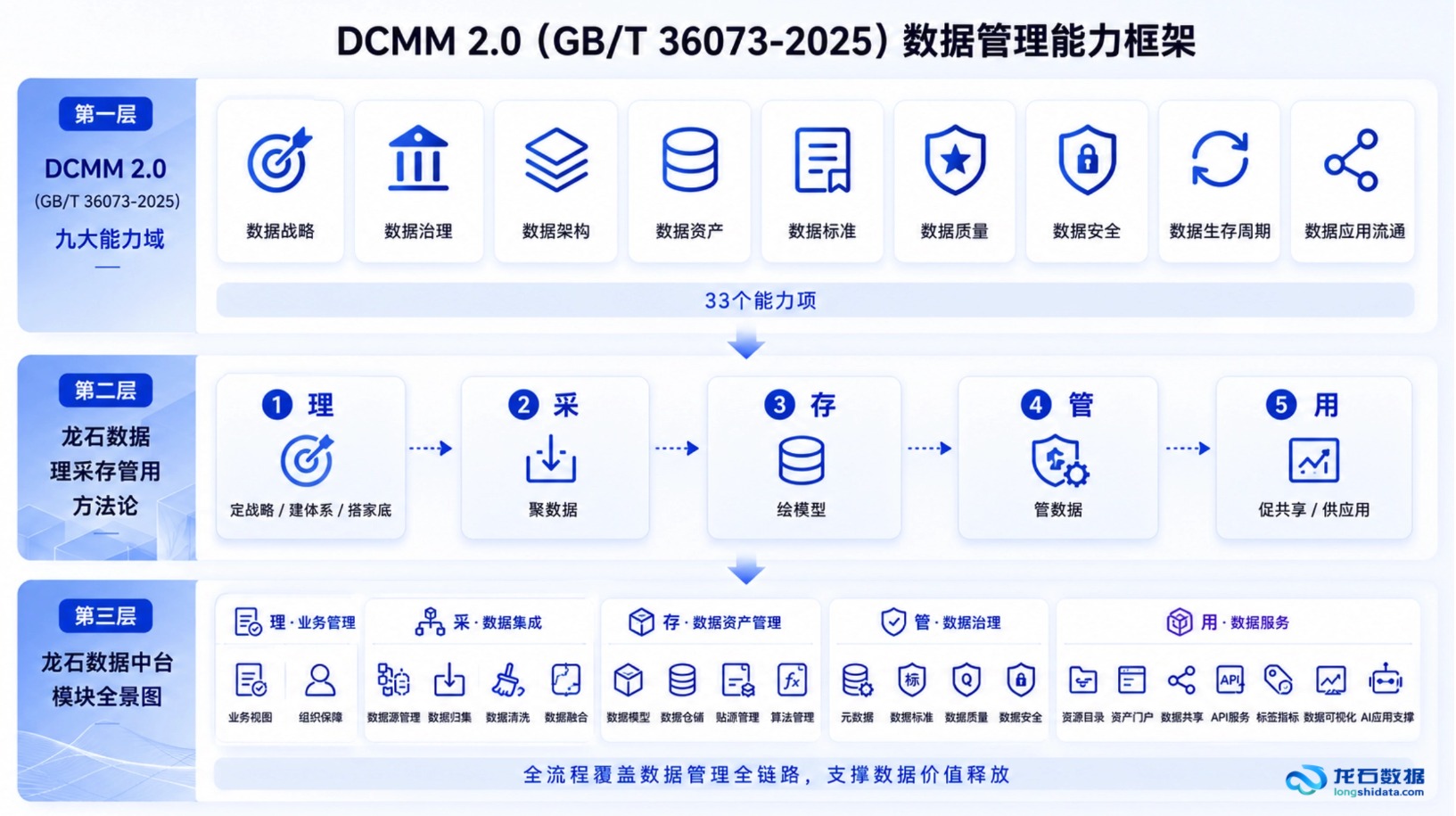
四、一个落地样本:当智能体成为数据中台的"用"的入口
前面讲的是趋势,下面看一个已经发生的事情。
江苏某国企数科运营着一个数据要素流通平台,汇聚了大量公共数据与市场化数据资源(企业名称已脱敏,下同)。平台建设完成后,运营团队很快撞上了三个断层:找数难——资源丰富但检索粗放,用户往往需要多次筛选才能定位所需数据;用数难——功能完备但缺乏引导,新用户不知道从哪里开始;运营难——需求存在但难以系统收集,数据产品迭代缺乏依据。
龙石数据为平台构建了一个"感知-匹配-演进"三位一体的AI用数智能体。在技术层面,智能体基于语义检索和模糊检索双模引擎理解用户意图,通过自然语言即可完成数据资源的查询和流程引导。在运营层面,智能体不只是一个问答机器人——它通过分析用户的搜索失败记录、浏览中断点、未完成订单等行为,自动识别潜在需求并生成需求洞察报告。
更值得关注的是机制层面的变化。平台运营团队从"凭感觉安排数据产品上架"转变为"依据智能体需求报告召开数据产品决策会",数据产品迭代周期明显缩短。运营团队的一位成员说了一句很形象的话:"以前推数据产品像蒙着眼睛打靶,智能体给了我们一杆瞄准镜。"
这个案例的启示不在于技术本身——智能问答、语义检索都不是新技术。它真正的价值在于验证了一个逻辑:当"理"(资产目录)、"管"(数据标准和质量规则)、"用"(智能体)被打通成一个闭环,"用"不再是数据中台链条的末端,而是驱动整个飞轮旋转的起点。
五、给CDO的行动建议
面对2026年的趋势变化,三条行动路径值得关注:
先理后AI。 在启动AI项目之前,把数据资产目录和元数据先建立起来。不是要求"完美治理",而是要求"最小可用治理"——AI至少要知道有哪些数据、数据在哪里、数据是什么意思。这是AI项目不翻车的底线。
管用一体。 不要把数据治理和AI应用分成两个团队、两个项目、两个预算线。治理能力要嵌入AI pipeline,治理团队的产出要对AI团队可见、可用、可验证。管和用是一件事的两个面。
机制比平台重要。 数据中台建好不是终点。成立数据管理部、建立常态化的质量巡检机制、明确数据资产健康度的责任人——这些组织层面的动作,往往比平台功能升级更能决定中台的长期价值。从多数成功案例来看,能够持续产出数据价值的企业,不是平台最先进的那批,而是组织机制最扎实的那批。
六、常见问题
Q: "理采存管用"和数据编织(Data Fabric)是替代关系吗?
不是替代,是互补。"理采存管用"是数据治理的工程落地框架,数据编织是一种数据架构理念。"理采存管用"的五个环节中,"采"和"存"两个环节天然适合融入数据编织的虚拟集成和智能分层思路——不要求所有数据物理集中,但要求所有数据在治理视野内。
Q: AI原生数据中台和传统数据中台的核心区别是什么?
核心区别在于治理能力的定位。传统数据中台把数据治理当作一个独立的功能模块,你可以用也可以不用。AI原生数据中台把数据治理能力——元数据、数据标准、数据质量——内化为AI用数的基础设施,没有这些治理能力,AI就无法正确理解和使用数据。两者不是"功能多少"的差异,而是架构逻辑的根本不同。
Q: 中小企业预算有限,怎么跟上这些趋势?
中小企业不一定需要"全面跟上",更需要"精准切入"。优先做三件事:一是建一个最小版本的数据资产目录,搞清楚自己有什么数据;二是选一两个业务价值最高的场景做数据质量治理,不追求全覆盖;三是利用市场上已有的轻量化工具——例如龙石数据质量管理平台社区版免费可用,覆盖GB/T 36344数据质量评价指标的主要维度,可以帮助团队先做一次数据质量体检,再根据体检结果决定下一步投入方向。
参考来源
[1] 国家数据局,《"数据要素×"三年行动计划(2024—2026年)》 — https://www.gov.cn/
[2] 财政部,《企业数据资源相关会计处理暂行规定》(财会〔2023〕11号),2023年8月 — https://www.gov.cn/
[3] DCMM 2.0(GB/T 36073-2025),数据管理能力成熟度评估模型,九大能力域




