

这不是孤例。过去两年,大量企业在数据中台和智能中台上分别投入资源,两个中台各自运转良好,但中间那条缝,正在成为AI落地最大的卡点。
一个越来越清晰的趋势是:数据中台和智能中台不再应该分开建设。不是"数据中台给智能中台供给数据"这种上下游关系,而是两层能力深度融合,最终让AI用数成为企业里像用邮箱一样自然的标配能力。
一、两个中台,两种逻辑,一个断层
分开建设不是没有理由。数据中台的逻辑是"把数据管好"——统一标准、保障质量、管理元数据、建设资产目录。智能中台的逻辑是"把模型用好"——训练、部署、推理、监控。组织上,数据中台归数据团队,智能中台归AI团队,两边汇报给不同的领导,拿不同的预算。
问题出在交接区。数据中台的治理产出——标准文档、质量报告、元数据清单——本质上是给人看的。AI读不懂一份PDF格式的数据标准说明,也不理解"这个字段在ERP里叫客户名称,在CRM里叫签约主体"意味着什么。AI团队只能从数据湖里直接拉原始数据,花大量时间做数据清洗和特征工程。而这些工作,本该在数据中台层面就已经完成。
Data-Centric AI 的理念[1]已经被反复验证:AI效果的上限取决于数据质量,而不是算法。DCMM 2.0(GB/T 36073-2025)[2]将数据质量和数据标准列为核心能力域,从国家标准层面确认了一个判断:数据治理不是AI的"前置准备工作",而是AI基础设施的组成部分。当企业发现调优了几个月的大模型,在实际业务场景中的表现还不如一个数据治理到位的中小模型时,把治理嵌入AI pipeline就不再是选择题。
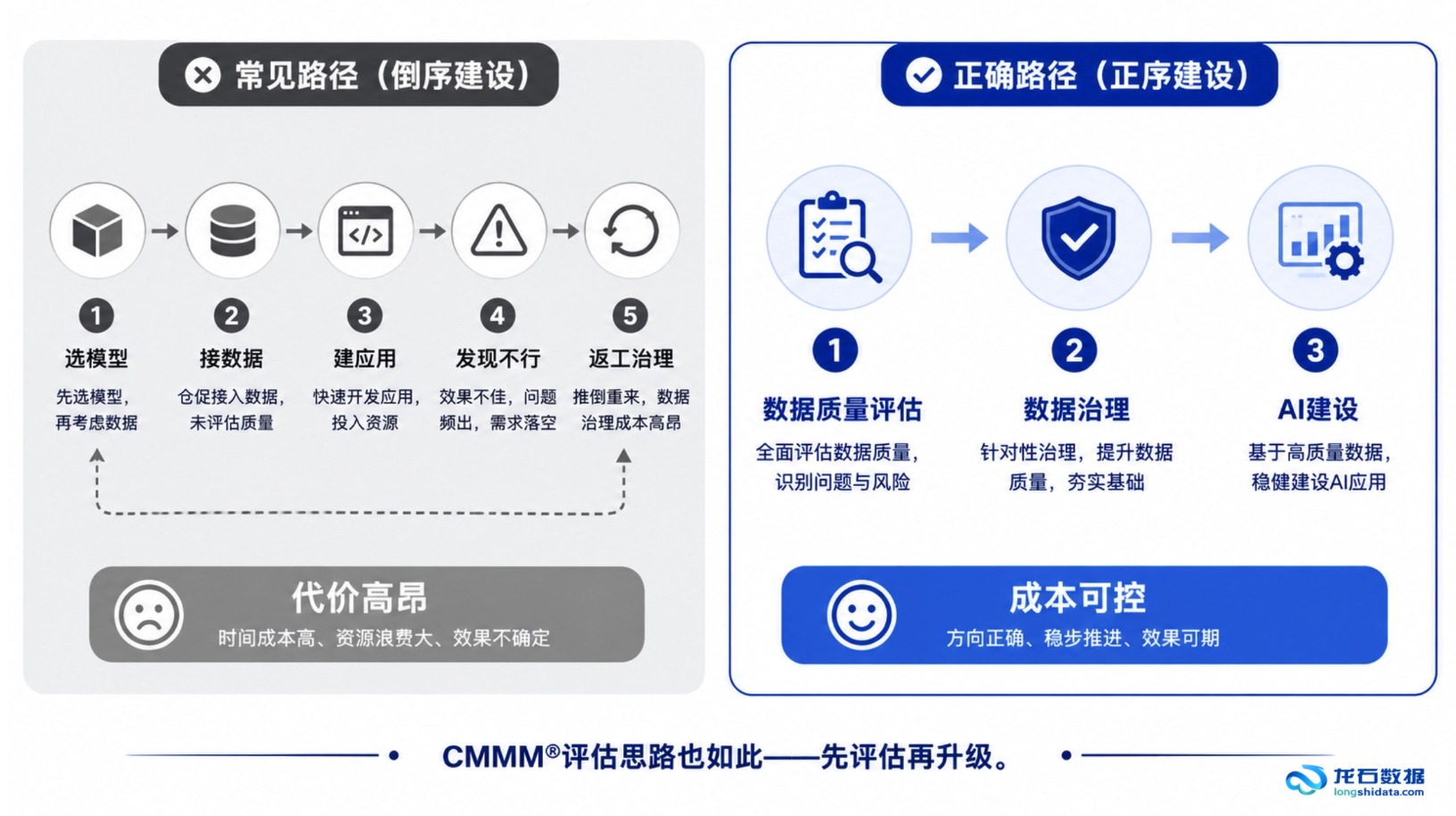
分开建设的本质,是把"治理"和"使用"拆成了两段接力赛。数据团队跑完第一棒交出去就完事了,AI团队拿到第二棒发现交接过来的数据并不是自己想要的格式和粒度。交接区,就是故障区。
二、合流的三个方向
数据中台与智能中台的合流,不是要在技术层面做平台合并,而是在能力层面打通三个关键环节。
方向一:治理能力从"人可读"变成"机器可读"
传统数据治理的产出是给人用的——标准文档是PDF、质量报告是Excel、元数据清单是一个网页目录。AI用不到这些东西。
合流的第一步,是把治理能力变成AI基础设施。元数据管理不只是给数据管理员看的目录,而是AI理解数据含义的前提——"这个表叫sales_order,但它的实际业务含义是客户签约后的正式订单,不包括意向单和草稿单",没有这一层语义标注,AI永远读不懂企业数据。数据标准不只是规范文档,而是AI跨表关联的翻译层——当ERP的订单状态是数字编码、CRM的订单状态是中文描述时,标准层负责统一语义。数据质量管理不只是出质检报告,而是AI输出可信度的基础——模型给出的分析结论是否可靠,取决于输入数据的质量水平。
方向二:资产目录从"汇报材料"变成"AI导航地图"
多数企业的数据资产目录定位是"给领导看的数据资产全景图"——展示了有多少张表、多少个字段、分布在哪些系统,但没人真的用它来找数据。
合流之后,资产目录的角色变了:它是AI用数的导航地图。当业务人员用自然语言问"帮我分析上个月的库存周转异常",AI智能体要做三件事:理解"库存周转"这个业务概念;在资产目录中定位相关数据和指标;评估这些数据的质量是否满足分析要求。这三步的完成度,直接取决于资产目录的质量——目录里有没有这些数据、元数据描述是否准确、质量标注是否可信。
市场上已有部分产品在实践这个逻辑。以龙石数据中台的AI用数智能体为例,它基于语义检索和模糊检索双模引擎理解用户意图,背后依赖的就是数据中台层建立的资产目录和元数据体系。没有"理"和"管"打下的基础,"用"的体验就是空中楼阁。
方向三:用数能力从"专业特权"走向"企业标配"
今天在企业里用数据做分析,仍然是专业门槛很高的事——你得会SQL,或者至少会用BI工具拖拽。业务人员查一个数据的典型路径是:找IT提需求→等排期→IT写查询→返回结果→不对→再沟通→再等。一个简单问题来回好几天。
当数据中台和智能中台合流后,这个路径被压缩成:打开对话窗口→自然语言提问→AI理解意图、定位数据、生成查询、返回结果。整个过程不需要SQL、不需要等排期、不需要猜测数据在哪。龙石AI用数智能体的实际运行数据显示,简单场景下自然语言问数的准确率可达100%,全场景综合准确率超过95%。基础咨询工单量显著下降,用户检索耗时大幅缩短。
当用数能力像发邮件一样简单时,它才能真正成为企业标配——不是数据团队的特权,而是每个业务人员的日常工具。
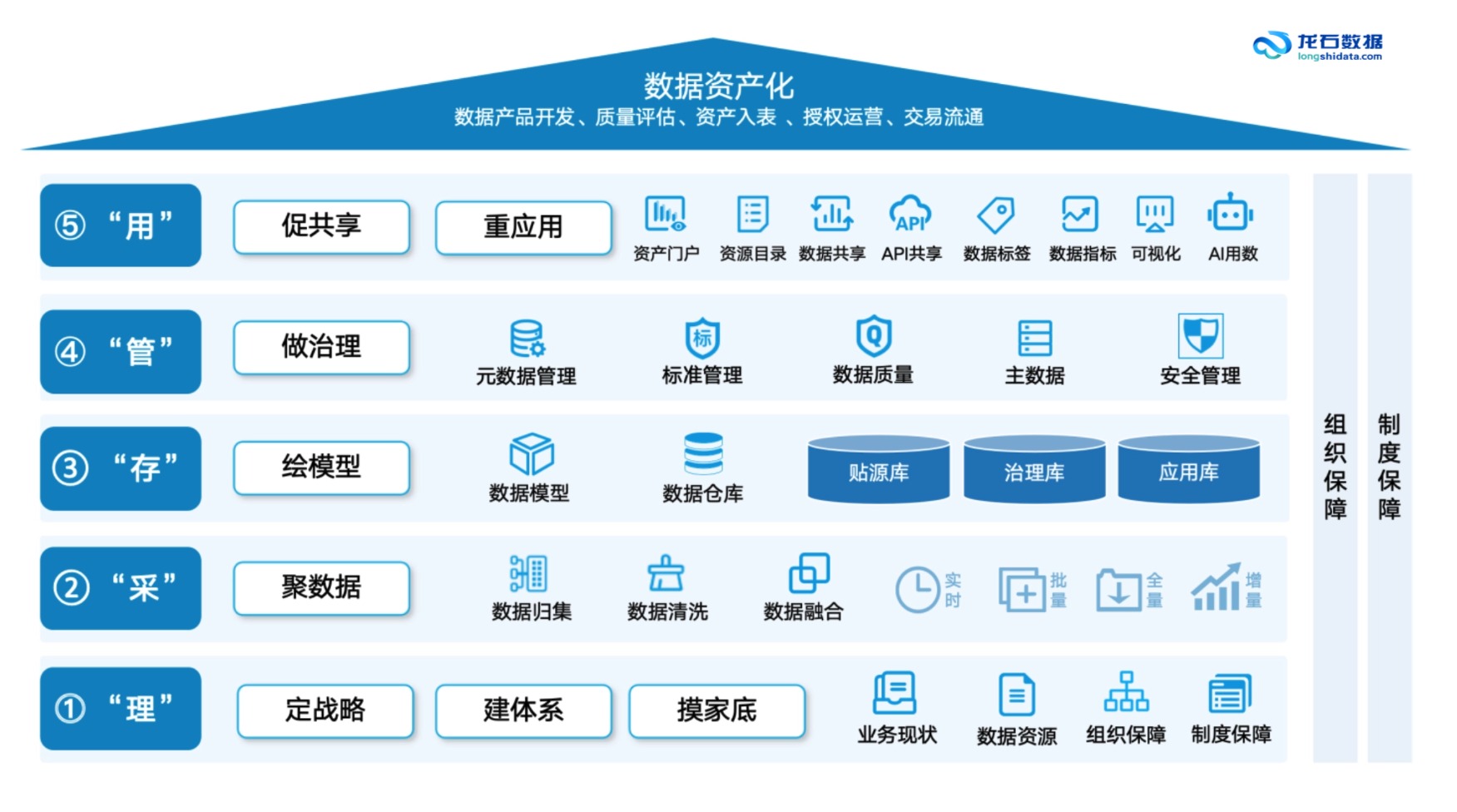
三、一个已经落地的样本
江苏某国企数科运营着数据要素流通平台,汇聚了大量公共数据与市场化数据资源(企业名称已脱敏,下同)。平台上线后面临一个典型问题:数据有了、功能全了,但用户用不起来——找数靠关键词硬搜、用数靠自己摸索、运营需求难以系统收集。
龙石数据为平台构建了一个"感知-匹配-演进"三位一体的AI用数智能体。不是简单加一个问答界面,而是把智能体深度嵌入数据中台的治理成果之上。技术层面,智能体基于语义检索和模糊检索双模引擎理解用户意图,自动引导从查找到申请的全流程。运营层面更值得关注——智能体分析用户的搜索失败记录和浏览中断点,自动识别潜在需求并生成需求洞察报告,直接驱动数据产品的上架、优化和迭代。
运营团队的一位成员说得直白:"以前推数据产品像蒙着眼睛打靶,智能体给了我们一杆瞄准镜。"
这个案例的启示不在于技术本身,而在于验证了一个逻辑:当智能中台不是独立于数据中台之外的另一个项目,而是基于数据中台的治理成果(资产目录、元数据、质量标准)来构建,合流就不是口号,而是可验证的效果。
四、给企业的三个行动建议
先理后AI。 如果还没有数据资产目录和元数据体系,在启动AI项目之前先把这些基础建起来。不需要追求完美覆盖,但至少让AI知道有哪些数据、在哪、是什么意思。这是AI不翻车的底线。
把用数入口做简单。 不要让用数据成为IT部门的专属能力。衡量标准很简单:一个业务人员能不能在不看说明书的情况下,3分钟内查到他想要的数据。自然语言问数、智能检索、自动可视化——这些能力今天已经可以在现有数据中台之上快速叠加。
管用一体。 如果数据治理团队和AI团队还在分开汇报、分开预算、分开考核,合流只会停留在PPT里。管和用是一件事的两个面,组织设计上应该先解决这个断裂。
五、常见问题
Q: 数据中台和智能中台合流,是不是意味着要推倒重建?
不需要。合流是能力打通,不是平台合并。如果现有数据中台已经有资产目录、元数据和质量管理体系,智能中台可以直接基于这些能力构建用数入口。如果治理基础薄弱,合流的过程本身就是倒逼治理升级的契机——不是"等治理完美了再上AI",而是"AI用数的需求反过来驱动治理加速"。
Q: 中小企业没有专门的AI团队,怎么推进合流?
中小企业反而是合流模式更容易落地的场景——团队小,数据团队和AI团队可能本来就是同一拨人,不存在组织上的割裂。关键是选一个业务价值最高的用数场景,把资产目录做扎实,叠一个轻量级的AI用数入口,先跑通再扩展。如果对数据质量心里没底,龙石数据质量管理平台社区版免费可用,覆盖GB/T 36344主要维度,可以先做一次数据质量体检。
Q: AI用数准确率能到100%吗?
做不到,也不需要。业务场景下的AI用数追求的不是实验室里的完美准确率,而是"可用的准确率+可解释的错误"。简单场景(如按条件查询统计)准确率可以做到接近100%,复杂场景(如跨多表关联推理)会有误差。关键是当AI出错时,用户能理解为什么错了、原始数据是什么、正确结果该怎么得到。治理到位的元数据和数据质量标注,正是支撑这种"可解释性"的基础。
参考来源
[1] Andrew Ng et al., Data-Centric AI, https://datacentricai.org/




