

上周,一位制造业的 CIO 在会议室里摊手:"模型换了三个,提示词改了十几版,智能问数查出来的数据还是和 ERP 对不上。"
排查了一圈,问题不在模型。在他系统里的数据。
过去一年,大模型、智能问答、AI Agent 在企业里跑马圈地。但真正用起来的屈指可数。我们交付了十几个 AI 项目后发现一个规律:AI 效果不佳的根因,十次里有七次不在模型,而在数据。
很多企业有个假设:模型足够聪明,数据差一点没关系,AI 能自动理解和纠错。
这个假设是错的。
AI 不会修复数据。AI 只会使用数据。
你把一份客户等级录错的 CRM 数据喂给 AI,它不会帮你纠正——它会基于错误的数据,输出一个看起来逻辑自洽、但结论完全错误的客户分析报告。
错误数据进入 AI 系统之后的传导路径,不是衰减,而是放大。
AI 不会自动修复数据,只会放大数据的缺陷
AI 本质上是数据的使用者。不管是智能问答、BI 分析还是 Agent 执行链路,最终的输出都建立在底层数据之上。
数据的缺陷传导到 AI 的过程,不是衰减,而是放大。
举个例子:某制造企业的 ERP 系统中,同一个物料编码在采购模块叫"316L 不锈钢板",在生产模块叫"316L 冷轧板",在库存模块又变成"SS316L"。人工处理时,老员工凭经验知道"说的是一回事",但 AI 不知道。当员工问"316L 不锈钢板的库存还有多少",AI 用 NLP 匹配到的可能是零——因为库存表里根本没有"316L 不锈钢板"这个字段值。
一个编码不统一的问题,在传统人工模式下只是"沟通麻烦点"。到了 AI 这里,直接变成"答案不可信"。
这就是 AI 时代数据质量最残酷的真相:人工能容忍的模糊,AI 会把它变成硬伤。
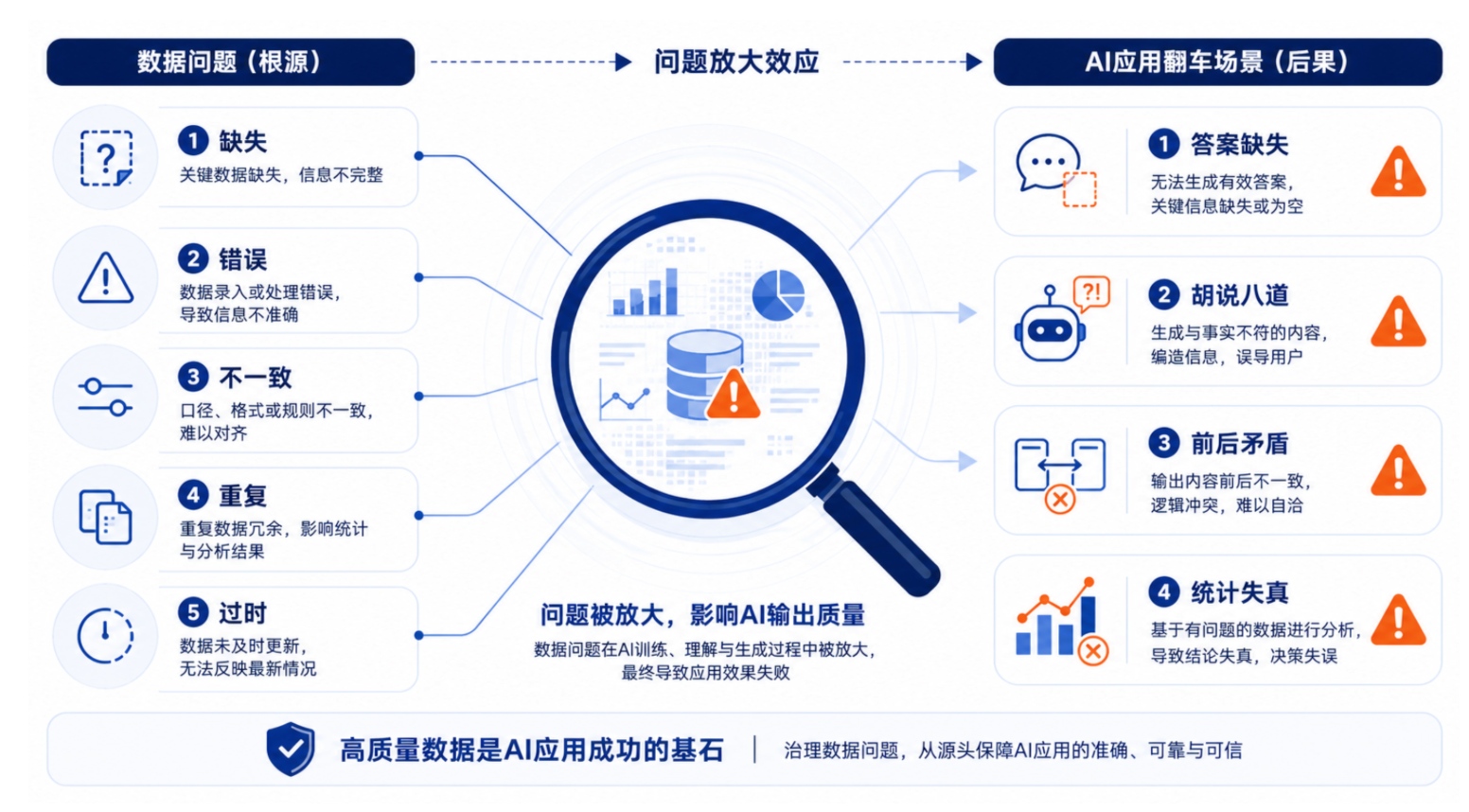
五种最容易毁掉 AI 项目的数据问题
结合近两年 AI 项目交付的经验,以下是五种最高发的数据质量问题,以及它们对 AI 造成了什么实际影响。
1. 数据缺失——AI 的答案永远不完整
某装备制造企业上了智能问数系统,管理层想查"过去半年各车间的设备综合效率(OEE)"。结果 AI 给出的是 4 个车间的数据,第 5 车间一片空白。不是 AI 漏了,是第 5 车间的 MES 系统过去三个月运维升级,部分设备的运行时间数据没有采集上来。
AI 不会主动告诉你"这部分数据缺失",它只会基于已有的数据给你一个看起来完整的结论。
2. 数据错误——AI 一本正经地胡说八道
一家化工企业把客户等级手工录入 CRM 时,将"战略客户"的编码从 A 错录成了 B。AI 做客户分级分析时,自动把这个年采购额八千万的客户归类到"普通客户"组。分析报告看起来数据翔实、逻辑自洽——直到被人发现最大的客户被降了级。
3. 数据不一致——同一个问题,两个答案
某地政务服务中心上线了智能问答,市民查询"办理不动产登记需要哪些材料"。AI 给出的清单和窗口实际要求差了三种材料。原因是审批系统里的材料清单和办事指南网站上的材料清单,已经半年没有同步过。市民白跑一趟。
4. 重复数据——让 AI 的统计变成笑话
某分销企业在 CRM 合并过程中,同一客户产生了多个编码。AI 做客户 360 画像时,把同一个客户的采购历史拆成了多条记录,画出的画像既不对也难看。业务团队从此对 AI 的客户分析结论持保留态度。
5. 数据过时——AI 在替三年前的信息做决策
某制造企业的 ERP 物料主数据中,有一批物料三年前已停产,但系统中仍标记为"在产"。AI 做生产计划时把这批物料纳入了排产,采购部照着计划下了订单——供应商回电话说"这个型号的料我们三年前就不生产了"。
车间主任看了一眼排产表,直接打了 CIO 的电话。
这五种问题在传统人工模式下不是不存在,而是被经验、沟通和层层审核消化掉了。当企业的运转切换到 AI 驱动的模式,人工缓冲层消失,数据的问题会直接暴露在决策者面前。
为什么数据正在成为 AI 的竞争力?
根本原因在于一个趋势:数据量在涨,但数据治理没跟上。
过去三年,企业数据量平均年增长 40% 以上。系统越来越多、数据越来越分散、数据之间的关联越来越复杂。但大多数企业的数据治理仍然是"出了问题再补"的事后模式。
国家数据局在近期的政策表述中明确提出:高质量数据是人工智能发展的关键基础设施[2]。中国信通院的研究也显示,企业在 AI 项目中用于数据准备和数据治理的时间,平均占到项目总周期的 60% 以上[3]。
这意味着什么?
不是 AI 技术不好,而是我们把 60% 的时间用在了修补数据上,只用 40% 的时间发挥 AI 的价值。
AI 竞争正在从拼模型,转向拼数据。当大模型能力越来越接近——今天你的问答评测分高一点,下周别人追上来——高质量数据正在成为企业新的竞争壁垒。
企业的 AI 竞争,本质上正在变成数据质量的竞争。
国家标准怎么说?
很多管理者认为"系统在跑、报表能出,数据就没问题"。
但国家标准《GB/T 36344-2018 信息技术 数据质量评价指标》[1]给出了更严谨的框架,其中六个维度除可访问性外,其余五个直接影响 AI 应用效果:
完整性——该有的数据有没有。客户表里缺了联系方式,AI 做客户画像就缺了一大块。
准确性——数据是不是真实正确的。产品单价录入时多打一个零,AI 的价格分析就闹笑话。
一致性——不同系统之间的数据是否统一。ERP、CRM、MES 里同一个客户名称不一样,AI 跨系统查询必然翻车。
唯一性——有没有重复数据。一个供应商建了三个编码,AI 做评估时把一家当成三家统计。
时效性——数据还有没有用。供应商联系人三年前已离职,系统没更新,AI 把评估报告发到了空号上。
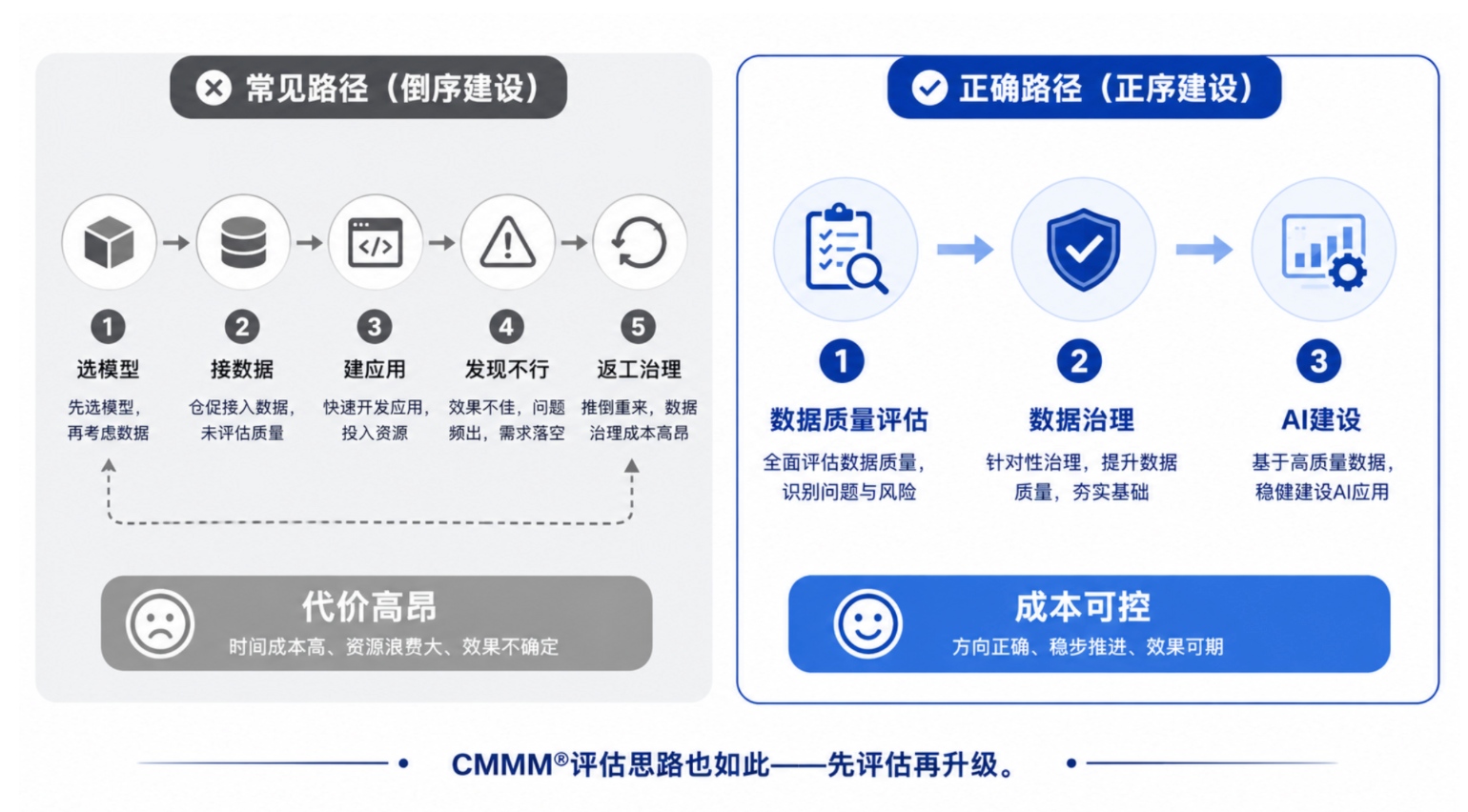
正确的 AI 建设顺序:先体检,再上马
很多企业的 AI 建设路径是这样的:
选模型 → 接数据 → 建应用 → 发现效果不行 → 返工治理数据
这是典型的"倒序建设"——把最应该前置的工作放在了最后。
更合理的路径只有三步:
第一步:数据质量评估。 先搞清楚数据有什么问题。哪些表缺字段、哪些系统数据打架、哪些标准不统一——问题被量化,决策才有依据。
第二步:数据治理。 不是一次性的运动式治理,而是建立持续的、可迭代的质量管理机制。定规则、跑检测、修问题、回头看。
第三步:建设 AI 应用。 在干净、一致、可信的数据基础上,让 AI 真正发挥作用。
这个顺序不是"更合理",而是"更便宜"。先做数据体检,把大部分问题消灭在 AI 上线之前,比上线之后被业务部门投诉再返工,成本差一个数量级。
其实制造业对这个逻辑并不陌生——企业在推进智能制造之前,通常会先做 CMMM®评估(GB/T 39116-2020《智能制造能力成熟度模型》),摸清自身的成熟度等级再规划升级路径。数据质量评估也是同样的思路:先诊断,再下药。
如果让你下周就开始一次数据质量体检
坦率地说,靠人工检查已经走不通了。一个中型企业的核心业务表少则几百张、多则上千张,靠人力逐表排查既不现实也不可持续。
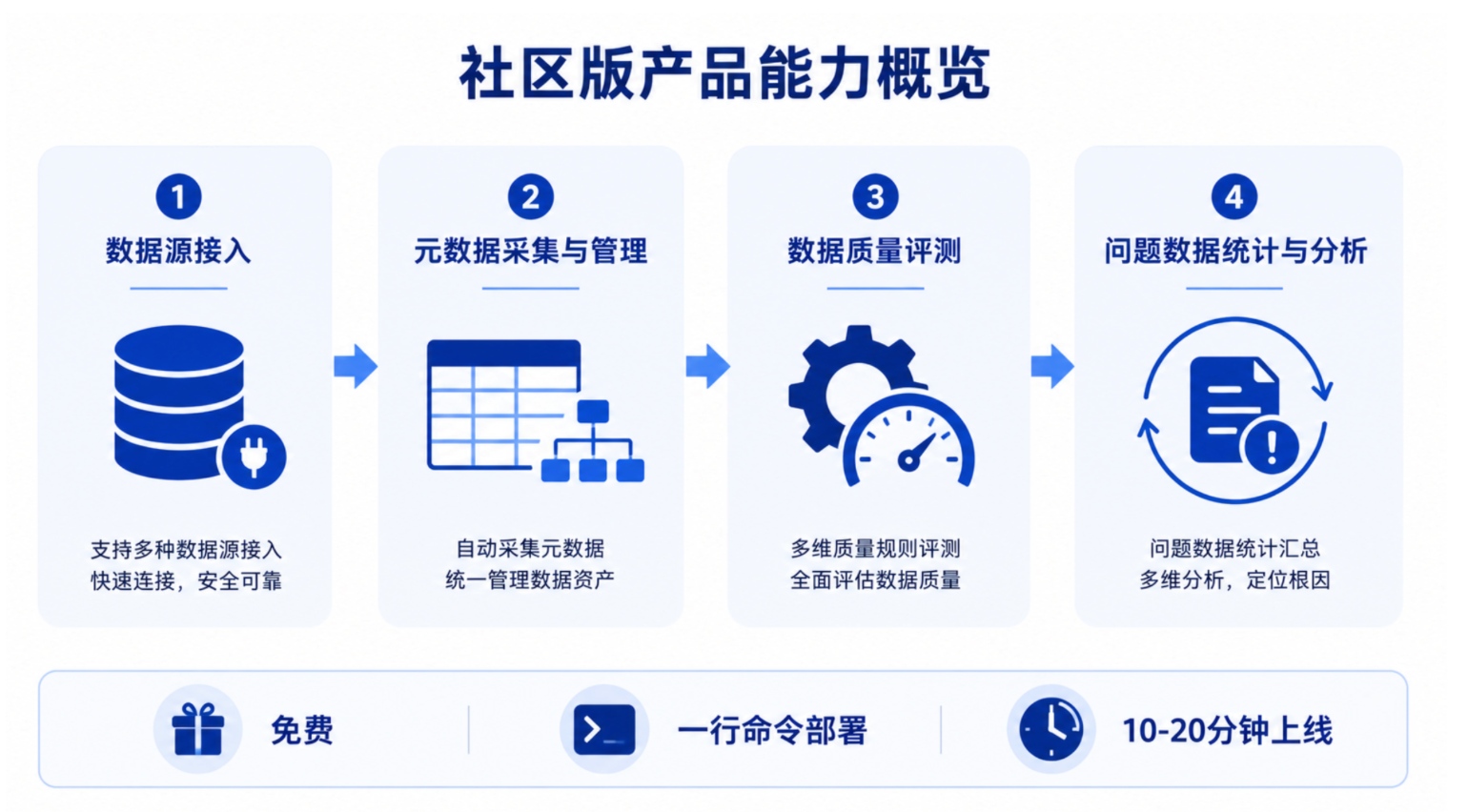
企业的操作流程也很直接,四步走完一次体检:
第一步:数据源接入。 支持 MySQL、Oracle、SQLServer、PostgreSQL 等主流数据库,把现有业务系统的数据统一纳进来。
第二步:元数据采集与管理。 自动采集表结构、字段信息等元数据,统一管理,不用人工梳理。
第三步:数据质量评测。 搭建评测模型 → 配置调度任务 → 自动输出结果。覆盖完整性、准确性、一致性、唯一性、规范性、时效性等全部质量维度。
第四步:问题数据统计与分析。 自动标记问题数据 → 分配修复 → 验证反馈,形成从发现到解决的完整闭环。
针对这个需求,龙石数据推出了数据质量管理平台·社区版——一个免费可用的数据质量体检工具。
它的核心价值很简单:
免费。 零采购成本,不需要走预算审批流程。
快速。 最低 4 核 16G 的服务器,一行命令完成部署,10 到 20 分钟就能打开浏览器开始用。
实用。 支持 MySQL、Oracle、SQLServer、PostgreSQL 等主流数据库,覆盖完整性、准确性、一致性、唯一性、规范性、时效性等全部质量维度,可视化配置检测规则。
闭环。 从发现问题 → 分配修复 → 验证关闭,形成完整的治理闭环。
更关键的是——社区版不是"功能阉割版"。它的内核和商业版一致,真正把数据质量管理的核心能力开放出来,让还没有采购预算的团队也能先做起来。
结语:AI 的起点,不是模型,而是数据
数字化时代解决的是"有没有数据"的问题。
AI 时代解决的是"数据能不能被正确使用"的问题。
模型决定 AI 能力的上限。但数据质量决定 AI 应用的下限——如果下限已经崩塌,上限再高也没有意义。
当大模型的能力越来越接近,当提示词工程越来越成熟,真正拉开企业 AI 差距的,是先人一步把数据清理干净的能力。
AI 时代最贵的成本,不是模型采购费用。而是在错误数据基础上的反复试错。
做 AI 之前,先看一眼你的数据。花一两周做一次数据质量体检,可能会省下半年甚至一年的试错。这可能是整个 AI 项目中投入最小、回报最高的一步。
龙石数据质量管理平台·社区版,免费可用。一行命令部署,让数据问题在 AI 上线之前被看见、被解决。
参考来源
[1] 国家市场监督管理总局、中国国家标准化管理委员会. GB/T 36344-2018 信息技术 数据质量评价指标. https://openstd.samr.gov.cn/bzgk/std/newGbInfo?hcno=D12140EDFD3967960F51BD1A05645FE7
[2] 国家数据局. 高质量数据集建设指引. https://www.nda.gov.cn/sjj/ywpd/szkjyjcss/0830/20250830210000366789341_pc.html




